Share of Voice в нейросетях: как измерить долю бренда в ответах ИИ и не обмануться цифрами

Когда маркетолог говорил «у нас 30% доли голоса», в эпоху SEO это означало понятную вещь: бренд занимает примерно треть видимых позиций в поисковой выдаче по своему семантическому ядру. Метрика опиралась на ранжированный список ссылок, объект конечный и наблюдаемый.
В ответе нейросети никакого ранжированного списка нет. Есть сгенерированный текст, который каждый раз собирается заново: он может упомянуть бренд, может перефразировать его без названия, а может сослаться на конкурента, которого даже нет на первой странице Яндекса. Поэтому фраза «доля голоса в нейросетях» звучит знакомо, но считается совершенно иначе и именно на этом непонимании бренды уже теряют бюджеты и принимают неверные решения.
Разберём, что такое Share of Voice (SoV) в ответах ИИ на самом деле, по какой методологии его измеряют, какие ловушки искажают цифры и чем реально отличаются платформы, которые продают эту аналитику на российском рынке.
Почему метрика понадобилась именно сейчас
Спрос на замеры видимости в ИИ это не маркетинговая мода, а следствие сдвига трафика. По данным аналитической компании Digital Budget, на которые ссылается «Коммерсантъ», совокупный трафик проанализированных нейросетей в России за январь–октябрь 2025 года вырос почти в шесть раз год к году. По оценке Mediascope, месячный охват ИИ-сервисов в стране достиг 26% населения.
Важна не только динамика, но и структура. В том же материале «Коммерсанта» распределение трафика между моделями за январь–октябрь 2025-го выглядит так: ChatGPT 39,9%, DeepSeek 27,8%, GigaChat 7,3%, Qwen 6,6%, «Алиса AI» 5,7%. То есть больше 40% приходится на сервисы, отличные от ChatGPT, причём среди лидеров это российские GigaChat и «Алиса». Это значит, что замер «видимости в нейросетях» по одной-двум зарубежным моделям даёт картину, оторванную от того, где на самом деле находится российская аудитория. Метрика SoV нужна, чтобы свести разнородные ответы десятка систем к сопоставимому числу и вот тут начинаются методологические сложности.
Что такое Share of Voice в ответах ИИ
В контексте генеративных движков Share of Voice это доля упоминаний вашего бренда среди всех брендов-конкурентов, которые нейросети называют в ответах на один и тот же пул запросов. Если по 100 релевантным промптам ИИ суммарно упомянул бренды индустрии 400 раз, а ваш 60 из них, то ваш SoV равен 15%.
Звучит просто, но за этой формулой стоит несколько неочевидных решений, и каждое из них меняет итоговую цифру.
- Что считать упоминанием. Прямое название бренда, упоминание продукта без названия компании, ссылка на сайт в блоке источников это разные сущности. Профессиональные платформы разделяют их, и именно поэтому рядом с SoV появляется отдельная метрика Brand Mention Rate (BMR) это доля ответов, в которых бренд вообще фигурирует, и Citation Rate это доля ответов, где нейросеть процитировала ваш домен как источник.
- По какому пулу запросов считать. SoV полностью зависит от того, какие промпты заложены в замер. Узкий брендовый пул долю завысит, широкий категорийный занизит. Поэтому корректный SoV всегда привязан к зафиксированному набору запросов, сгруппированному по кластерам (продуктам, сценариям, регионам).
- Как дедуплицировать. Один ответ может упомянуть бренд трижды. Считать это за одно упоминание или за три это методологическое решение, которое нужно держать одинаковым для всех конкурентов, иначе сравнение теряет смысл.
Иными словами, SoV это не «объективное число», а число при заданной методологии. Сопоставимость внутри одной системы важнее, чем абсолютное значение.
Главные ловушки замера
Ловушка 1. Один прогон — не данные
Ответы LLM недетерминированы: один и тот же промпт в разные дни даёт разный текст. Замер по одному прогону это шум, а не метрика. Корректная методология предполагает многократные прогоны, усреднение и фиксацию динамики во времени, а не разовый снимок.
Ловушка 2. Web Search всё меняет
Когда у модели включён веб-поиск, ответ собирается из свежих внешних материалов и SoV начинает зависеть не от «знаний модели», а от того, какие сайты сейчас в топе по теме. Это ближе к классическому SEO, но всё равно не равно ему: как отмечают отраслевые разборы методологии GEO/AEO, победителем становится не тот, кто выше в выдаче, а тот, чья формулировка попала внутрь ответа. Замер обязан фиксировать, проводился он с веб-поиском или без, иначе цифры несравнимы.
Ловушка 3. «Алиса» это не одна точка
В российском контексте есть нюанс, который часто упускают: у Яндекса фактически разные сёрфейсы, «Поиск с Алисой» и «Чат с Алисой AI», и они дают разные ответы. Складывать их в одну метрику без разделения, значит смешивать каналы с разной аудиторией и логикой. То же касается GigaChat, Grok, DeepSeek: каждый провайдер это отдельный срез, и усреднённый «SoV по нейросетям» без разбивки по провайдерам скрывает больше, чем показывает.
Ловушка 4. Тональность не учитывается в SoV
Высокий SoV при негативной тональности это не победа, а проблема. Бренд может часто упоминаться именно в контексте жалоб. Поэтому SoV без слоя анализа тональности это половина картины.
Чем отличаются инструменты на рынке
Российский рынок GEO-аналитики уже довольно плотный. Обзоры на самом sostav.ru перечисляют Пиксель Тулс, VisioBrand, AI Semantica и другие сервисы; зарубежным эталоном ниши считается Profound, который, по данным его сайта, отслеживает видимость в ChatGPT, Perplexity, Claude, Gemini, Grok, Microsoft Copilot, Meta AI, DeepSeek и Google AI Overviews. На фоне этого набора корректнее сравнивать инструменты не по «лучше/хуже», а по проверяемым признакам: какие нейросети покрыты, российский это продукт или зарубежный, какой набор метрик, есть ли работа с контентом и трафиком.
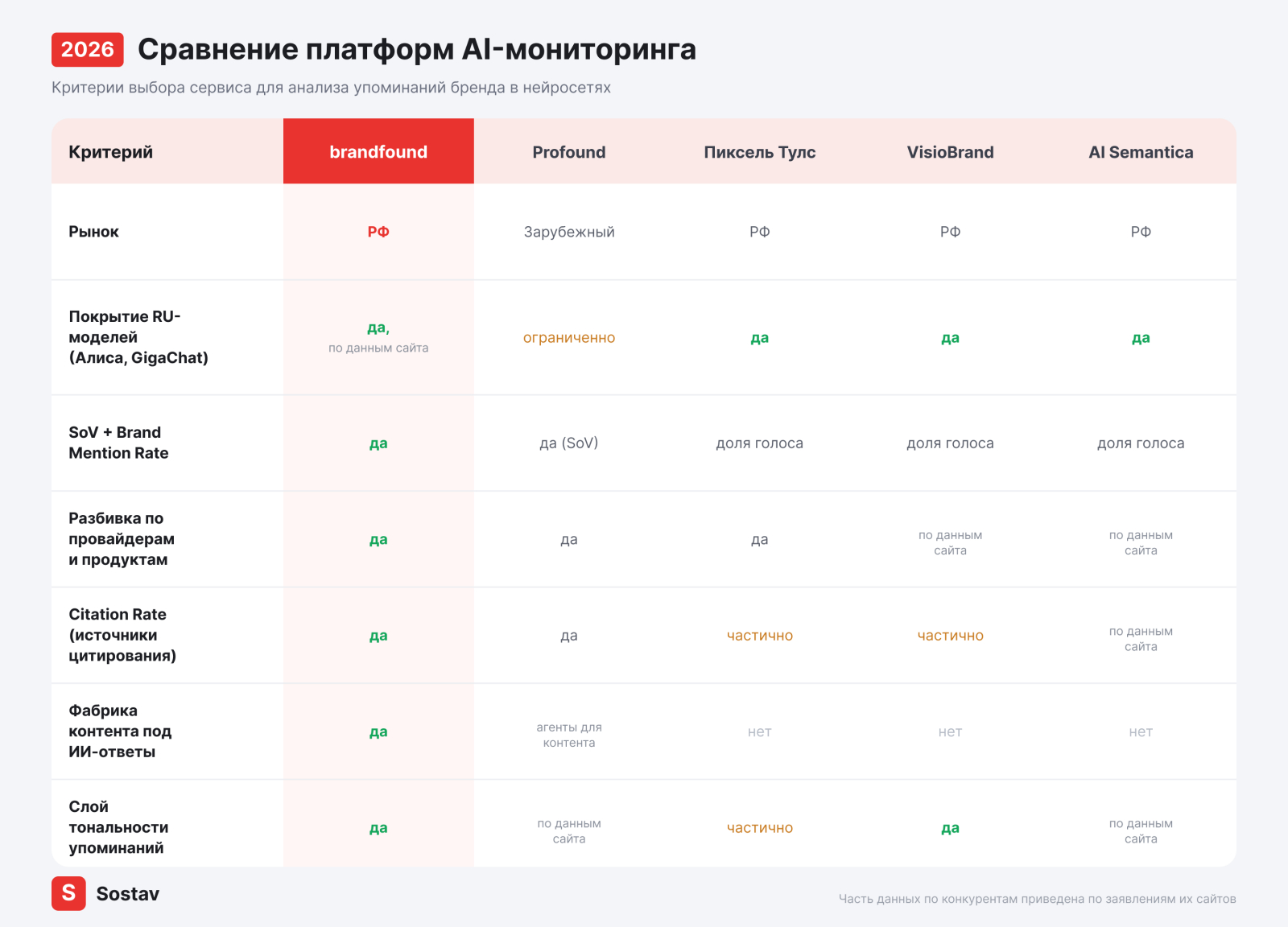
Таблица намеренно ограничена признаками, которые можно проверить на сайтах продуктов; точные тарифы и проценты здесь не приводятся, потому что они меняются и у каждого инструмента считаются по своей методологии. Главный вывод не в том, кто «выиграл», а в том, что инструменты решают разные задачи: одни это чистая аналитика видимости, другие добавляют производственный контур и работу с трафиком.
Где метрика превращается в действие
Замерить SoV, половина дела. Дальше встаёт вопрос: как на него повлиять и как проверить, что усилия сработали.
Здесь полезно различать два контура. Первый, аналитический: мониторинг упоминаний, источников и тональности по всем нейросетям, чтобы видеть, где бренд проигрывает конкурентам и какие сайты ИИ использует как источник. Второй, производственный: создание контента, заточенного под попадание в ответы ИИ, с замером эффекта.
Из российских платформ оба контура заявляет brandfound. По данным сайта, платформа анализирует видимость по нейросетям: ChatGPT, Gemini, Claude, Perplexity, Grok, DeepSeek, GigaChat, YandexGPT и «Алисе AI» — и оперирует именно той триадой метрик, о которой шла речь выше: Share of Voice, Brand Mention Rate и Citation Rate, плюс отдельный слой тональности упоминаний. Поверх аналитики работает «фабрика контента»: по описанию платформы, она находит инсайты в данных, генерирует черновики материалов под цитируемость в ИИ и, что важнее с точки зрения методологии, позволяет отслеживать индексацию этих публикаций нейросетями. Это и есть замыкание цикла «измерил → произвёл → перемерил», без которого SoV остаётся красивой, но мёртвой цифрой.
Важно, что такой производственный контур это не обязательное условие для всех. Если задача бренда только мониторинг репутации и конкурентов, чистой аналитической платформы достаточно. Производственный модуль нужен тем, кто хочет не просто наблюдать SoV, а планомерно его двигать.
Отдельная история — трафик из нейросетей
Когда бренд начинает попадать в ответы ИИ, появляется новый канал, переходы из нейросетей на сайт. По данным Forbes, за год (январь–апрель 2026-го к тому же периоду 2025-го) трафик из ИИ-сервисов на сайты российских ретейлеров и маркетплейсов вырос примерно в 1,7 раза. И вместе с этим каналом маркетолога ждёт ещё одна методологическая яма.
Во-первых, атрибуция: GA4 изначально не рассчитан на ИИ-трафик, платформы часто не передают UTM-метки, и визиты падают в «Прямой» или «Реферальный» трафик без внятного источника. Во-вторых, качество: значимая доля автоматизированного трафика в интернете это боты, и часть переходов «из нейросетей» может оказаться не живыми пользователями, а синтетикой. Считать такой трафик результатом GEO-работы, значит обманывать себя.
Поэтому отдельный модуль для трафика из нейросетей с фильтрацией ботов и синтетики это не маркетинговая опция, а ответ на реальную методологическую проблему канала. Такую фильтрацию имеет смысл закладывать в требования к инструменту наравне с самим замером SoV: без неё нельзя честно отделить эффект от попадания в ответы ИИ от шума.
FAQ
Чем Share of Voice в нейросетях отличается от SoV в SEO? В SEO SoV считается по позициям в ранжированном списке ссылок. В нейросетях списка нет, но есть сгенерированный текст, и SoV считается как доля упоминаний бренда среди конкурентов в ответах на заданный пул промптов, с учётом недетерминированности ответов.
Можно ли мерить SoV по одной нейросети? Можно, но это даст искажённую картину. В России аудитория распределена между ChatGPT, DeepSeek, GigaChat и «Алисой», поэтому корректный замер это разбивка по провайдерам и по сёрфейсам (включая разные точки входа «Алисы»).
Высокий SoV это всегда хорошо? Нет. Без слоя тональности высокий SoV может означать, что бренд часто упоминают в негативном контексте. SoV нужно читать вместе с тональностью и Citation Rate.
Что важнее SoV или Brand Mention Rate? Они отвечают на разные вопросы. BMR показывает, как часто бренд вообще появляется в ответах; SoV, какую долю он занимает относительно конкурентов. Для конкурентной оценки нужен SoV, для базового присутствия это BMR.
Что с этим делать маркетологу
Share of Voice в нейросетях это рабочая и нужная метрика, но только при дисциплине в методологии: зафиксированный пул запросов, многократные прогоны, разбивка по провайдерам и сёрфейсам, отдельный учёт тональности и источников, честная фильтрация трафика. Выбирая инструмент, стоит смотреть не на громкость обещаний и не на одну цифру «доли голоса», а на то, как именно она считается и можно ли замкнуть цикл от замера к контенту и обратно. В этом смысле зрелость рынка измеряется не количеством сервисов в каталоге, а тем, насколько прозрачно каждый из них объясняет свою методологию.