Как попасть в ответы YandexGPT, Gemini, ChatGPT и других ИИ — поисковиков?

Рассмотрим ситуацию, знакомую многим SEO-командам: сайт стабильно держится в топе поисковой выдачи, но в ответах ИИ (ChatGPT, Gemini, Perplexity, ЯндексGPT) появляются конкуренты. На первый взгляд это выглядит как ошибка алгоритма. Однако причина обычно проще: генеративные системы используют другой механизм отбора источников и иную логику доверия. Поэтому даже сильные сайты иногда оказываются «невидимыми» для ИИ-ответов, несмотря на высокие позиции в поиске.
SEO vs GEO: почему старые правила больше не работают
Классическое SEO оптимизирует страницы под поисковые алгоритмы. Основные факторы ранжирования:
- релевантность запросу
- поведенческие сигналы
- ссылочный профиль
- техническая оптимизация
Генеративные системы работают иначе. Generative Engine Optimization (GEO) — это подход к созданию контента, который делает его удобным для извлечения и цитирования в ответах ИИ-поисковиков. В отличие от традиционного SEO, генеративные модели:
- извлекают конкретные факты и определения, а не ранжируют страницы целиком
- чаще используют авторитетные источники и «хабы знаний»
- предпочитают структурированную информацию
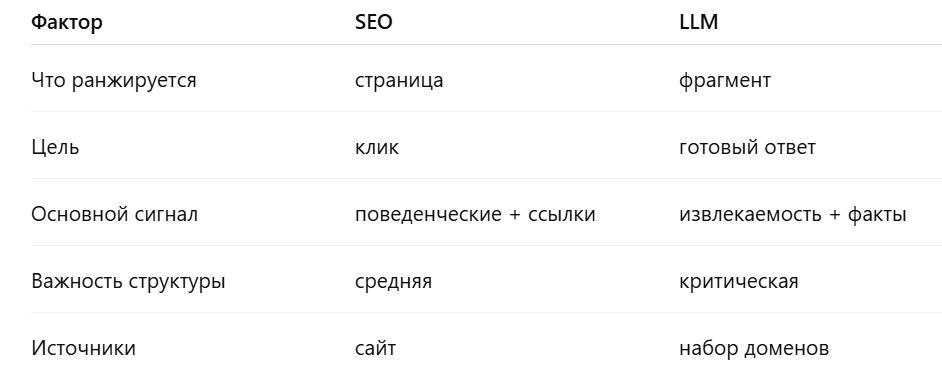
Вывод: сайт может занимать первое место в поиске и при этом не попадать в ответы ИИ, если из него трудно извлечь конкретные факты.
Почему даже сильный сайт не попадает в ответы ИИ?
Даже у авторитетных ресурсов есть 4 критические уязвимости:
- Размазанный фактаж: нужные данные распределены по нескольким страницам, нет чётких формулировок, таблиц и блоков FAQ.
- Технические барьеры: страница закрыта от индексации или плохо парсится (тяжёлые JS-скрипты, перегруженные шаблоны).
- Вторичная роль бренда: бренд присутствует в тексте как «участник кейса» или комментатор, а не как первичный источник знания.
- Слабое внешнее окружение: конкуренты «прикрыты» отраслевыми справочниками, рейтингами и СМИ, которые модели ИИ используют как эталонные источники
Источники для ИИ-выдачи: где живут ваши конкуренты?
Ключевой фактор успеха — определение доменов, на которые реально опираются ИИ-поисковики в вашей категории. Это далеко не всегда совпадает с ТОП-10 выдачи.
Чаще всего модели предпочитают:
- Агрегаторы и маркетплейсы;
- Отраслевые медиа с высокой цитируемостью;
- Энциклопедические форматы и Wiki-структуры;
- Инструкции «как выбрать» и гайды;
- Страницы с чёткими сравнительными блоками.
Если вы не присутствуете в этом «слое», модель будет добирать факты у тех, кто там есть — даже если их собственный сайт в органике слабее вашего.
llmSpot: Анализ и управление видимостью в ИИ
В системе llmSpot полную картинку разрыва между поиском и нейросетями можно увидеть за один цикл мониторинга. Система сама формирует сотни релевантных вопросов, фиксирует ответы во всех популярных моделях и показывает реальную роль бренда.
Как это работает в llmSpot:
- Query Space: автоматическая генерация пула вопросов, которые пользователи задают ИИ в вашей нише.
- Source Mapping: наглядная карта сайтов, которые ИИ цитирует чаще всего.
- Role Analysis: фиксация статуса бренда (основной источник, второстепенное упоминание или полное отсутствие).
- Gap Detection: поиск «галлюцинаций» ИИ или устаревших данных о вас — это ваши прямые точки роста.
Дорожная карта: как попасть в ответы ИИ
Переход от классического контент-маркетинга к системной работе с ИИ в llmSpot выглядит так:
- Проектирование под Retrieval: создание контента емкими, независимыми блоками (Self-contained). Чёткое определение — Таблица сравнения — Список преимуществ.
- Насыщение «слоя источников»: важно присутствовать на площадках, которые уже часто цитируются в отрасли: отраслевые медиа, экспертные статьи, рейтинги, каталоги, исследования). Это формирует внешний цифровой след бренда.
- Коррекция фактов: вытеснение неверных версий о продукте через обновление данных в цитируемых ресурсах: обновление информации на авторитетных площадках, публикация новых материалов, корректировка справочных источников
- Регулярность и системность: эффективная работа с видимостью в ИИ требует не разовых действий, а системного подхода. Система llmSpot помогает:
- формировать медиаплан на регулярные периоды
- выявлять дефицитные темы и форматы в нише
- отслеживать изменения в ответах ИИ
- создавать контент, оптимизированный под извлечение и цитирование
Такой подход позволяет не только реагировать на изменения, но и планомерно увеличивать присутствие бренда в ответах ИИ-поисковиков.
FAQ: частые вопросы
— Почему ChatGPT не показывает мой сайт? Чаще всего контент неудобен для извлечения: нет чётких фактов, структурных блоков и понятных ИИ определений.
— Почему мой сайт в топе, но нейросети его не рекомендуют? Поисковые системы ранжируют страницы целиком, а генеративные модели выбирают конкретные фрагменты информации и чаще опираются на авторитетные источники.
— Как попасть в ответы ИИ? Использовать таблицы и списки, увеличивать плотность фактов на абзац, делать self-contained блоки и публиковаться во внешних авторитетных источниках.
— Можно ли повлиять на ответы ИИ? Да, через Generative Engine Optimization: работу со структурой контента, внешним цитированием и «цифровым следом» бренда.
Итог
Топ в поиске по-прежнему важен, но это уже не единственная витрина. Если бренд не становится источником для ответа ИИ, он постепенно теряет влияние. Будущее за теми, кто позаботился о своей цитируемости в моделях ИИ уже сегодня.