Как мы научили цифровых респондентов отвечать по-человечески
Как мы научили цифровых респондентов говорить без «ванильных» фраз, шаблонов и противоречий.
Когда мы запустили наши первые эксперименты с цифровыми респондентами, их ответы звучали так, будто их писал преподаватель и главный маркетолог страны. Все были вежливы, дружелюбны и безупречно академичны. В жизни люди так не говорят — особенно в России.
Чтобы сделать ответы цифровых персон ближе к человеческим, пришлось пройти путь от чрезмерной «ванильности» до системы архитектуры, где каждая персона ведёт себя реалистично и может проявлять разные эмоции. Ниже — основные проблемы, с которыми мы столкнулись, и то, как мы научились их решать.
1. «Ванильность» и академичность речи
Проблема
Большинство языковых моделей обучены на англоязычных корпусах и воспроизводят мягкие, обобщённо позитивные нормы общения. Они избегают оценочности и говорят «как из методички». Для российского контекста это неестественно: наши респонденты говорят проще, прямее и эмоциональнее.
Что мы сделали
Мы адаптировали контекст, а не модель. Через систему подсказок и контекстных примеров задали речевые и эмоциональные паттерны, характерные для целевой среды. Добавили параметры, которые помогают персонам говорить в той интонации и прямоте, что свойственна людям с похожими социальными установками.
Результат
Ответы перестали звучать как учебник. Появились эмоции, бытовые обороты и естественная интонация.

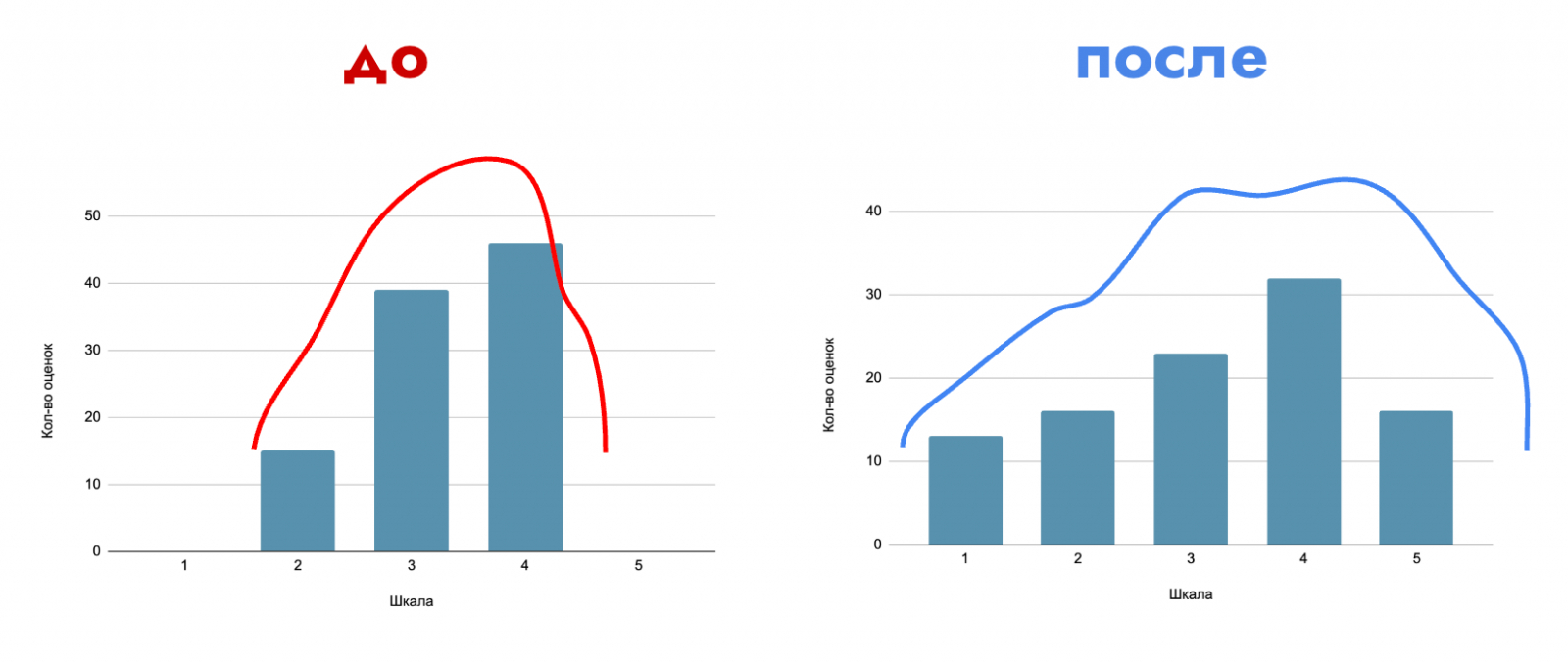
2. Узкий колокол оценок
Проблема
Цифровые респонденты склонны усреднять. На шкалах в 5 или 10 баллов почти все оценки группировались вокруг середины — получалась «стерильная адекватность» без настоящих реакций.
Что мы сделали
Мы ввели систему внутренних параметров, которые задают эмоциональный фон и индивидуальную строгость восприятия для каждой персоны. Это позволяет расширить диапазон оценок и приблизить форму распределения к человеческой.
Результат
Оценки перестали быть одинаковыми, появились пики и крайние реакции. Стало видно, какие идеи действительно вызывают отклик, а какие раздражают — как в реальных исследованиях.
3. Последовательность ответов
Проблема
Без внутренней логики персона может противоречить себе: сегодня она вегетарианка, а через минуту рассуждает о прожарке стейка.
Что мы сделали
Мы построили систему внутренней валидации, которая проверяет согласованность ответов с анкетой и профилем персоны. Если реакция противоречит ее характеристикам, система корректирует это на уровне поведения, а не текста.
Результат
Персоны стали вести себя как настоящие люди с устойчивыми установками и ценностями. Их можно «переопрашивать», и они сохраняют свою идентичность и стиль реакции.
4. Чистка невалидных вопросов
Проблема
Некоторые вопросы дают видимость корректности, но на деле искажают результат. Например, «Какой бренд рекламируется в ролике?» — модель «видит» логотип, а человек может не запомнить его вовсе.
Что мы сделали
Мы провели анализ анкет и исключили вопросы, где цифровые респонденты заведомо знают больше, чем живые. Для каждого типа исследования — видео, KV, позиционирование — зафиксировали собственный валидный набор вопросов.
Результат
Ответы стали отражать не знание фактов, а восприятие смысла и эмоций, что ближе к реальным респондентам.
5. Сопоставление с реальными людьми
Проблема
Без внешней проверки нельзя понять, насколько цифровые респонденты действительно приближаются к живым.
Что мы сделали
Мы регулярно проводим валидационные тесты, где те же идеи проходят и через цифровых, и через живых участников. Сравниваем структуру распределений и характер реакций — не только цифры, но и инсайты и смыслы.
Результат
Мы можем количественно измерять «человечность» ответов и видеть, где цифровые респонденты уже совпадают с живыми, а где — ещё нет.
Где границы реализма
Цифровые персоны — не замена живым людям. По крайней мере, пока 🙂 И это не абстракция, а инструмент, который помогает исследователям быстрее видеть закономерности и принимать решения на реальных данных.
Мы продолжаем использовать и проверять синтетических респондентов на практике и будем рады командам, которые готовы делать это вместе с нами. Чем больше у нас данных о реальных реакциях, тем человечнее становятся наши цифровые персоны.
Если хочешь — могу предложить лайтовый рерайт с чуть большей выразительностью или плотностью, но без потери стиля.