AI prompt tracking: не то же самое, что rank tracking: как изменить KPI команды
SEO-команды начали трекать «позиции в ChatGPT» так же, как раньше трекали позиции в Google. Search Engine Journal объяснил, почему это методологическая ошибка, и что измерять вместо этого
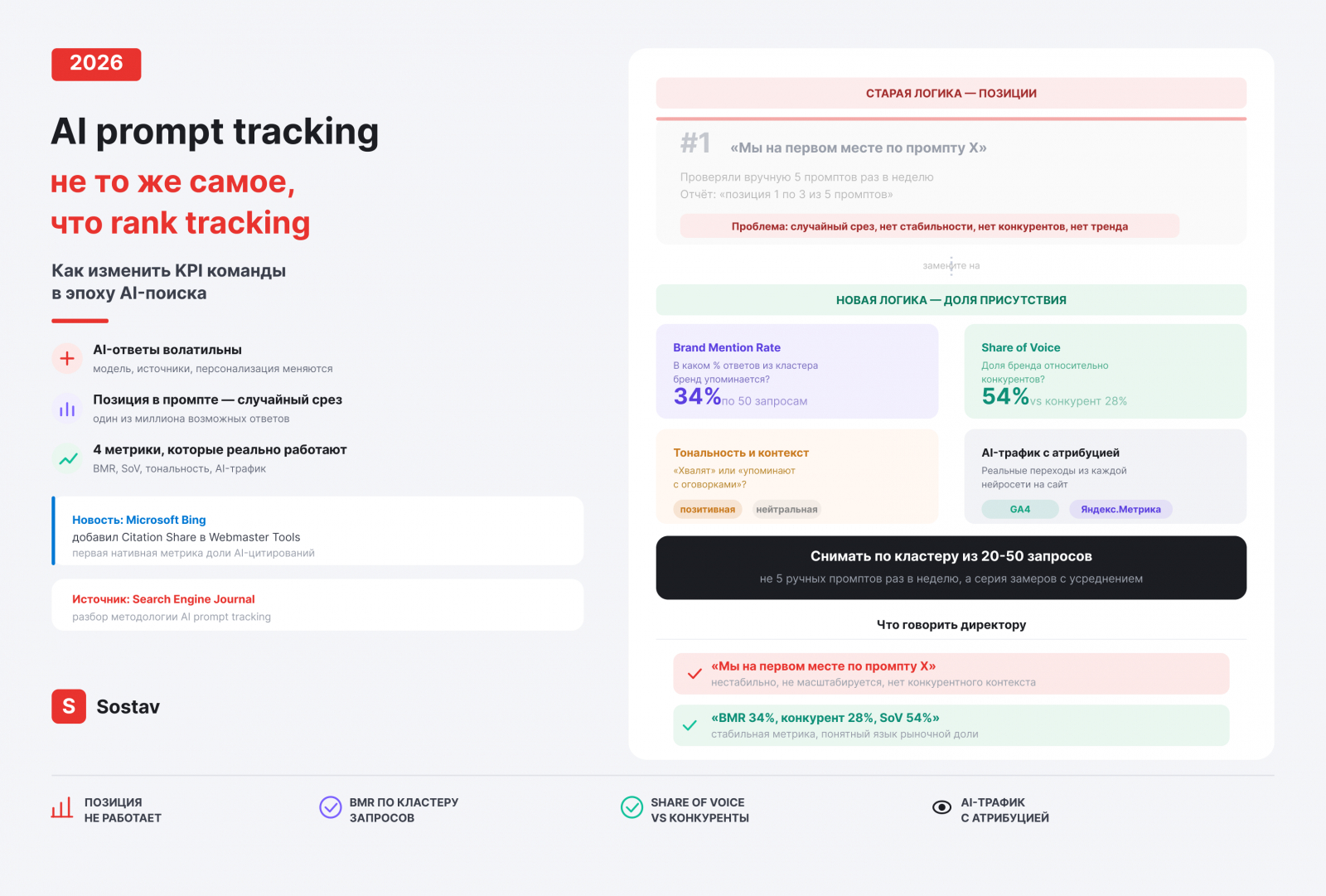
Когда у маркетолога появляется новый канал, первый импульс понятен: перенести знакомые метрики. Так было с социальными сетями (охват как TVR), с контекстом (CTR как газетный отклик) и теперь с AI-поиском. Команды начали задавать ChatGPT и Алисе тестовые промпты и фиксировать, на какой «позиции» стоит бренд в ответе: первый, второй, третий. Логика понятна: позиции работали в SEO, должны работать и здесь, но не работают.
Search Engine Journal опубликовал разбор, в котором объясняет: AI prompt tracking нужно оценивать через стабильность представления бренда, волатильность ответов и средние значения по кластеру запросов, а не через классический трекинг позиций. Это не техническая деталь, а принципиальный сдвиг в том, как вообще считать эффективность в AI-среде.
Почему «позиция в нейросети»: плохая метрика
Когда Google показывает сайт на первом месте по ключевому слову, это относительно стабильный факт. Алгоритм обновляется, но в течение недель и месяцев результаты предсказуемы. Можно поставить трекер, снимать скриншоты и строить отчёт.
AI-ответ устроен принципиально иначе. На то, что скажет нейросеть в ответ на один и тот же промпт, влияет сразу несколько факторов, которые меняются независимо друг от друга.
Версия модели. OpenAI, Яндекс, Сбер и другие регулярно обновляют модели. Одно и то же качество контента может давать разное упоминание на разных версиях.
Источники для RAG. Большинство современных нейросетей используют retrieval-augmented generation: перед ответом модель обращается к поисковому индексу и строит ответ на основе найденных фрагментов. Если свежая статья конкурента попала в индекс, это мгновенно меняет контекст ответа, без каких-либо изменений на вашем сайте.
Персонализация. ChatGPT с включённой памятью, Google AI Mode с историей пользователя, Алиса с учётом региона: ответ зависит от контекста сессии. Один промпт от разных пользователей может дать разные упоминания.
Поведение цитирования. Модели не фиксируют «позицию» как поисковик. Они генерируют текст, в котором бренд может появиться первым, последним или вовсе быть заменён обобщённым описанием категории.
Итог: если команда снимает «позицию» один раз в неделю по трём промптам, она видит случайную точку в пространстве. Не тренд, не системное присутствие, а один срез из миллиона возможных.
Что Microsoft понял раньше других
Хороший сигнал того, куда движется рынок измерений: Microsoft добавил в Bing Webmaster Tools новый раздел AI Performance с метриками Citation Share, Intents и Topics. Citation Share показывает долю AI-цитирований сайта по grounding-запросам, то есть не «вы упомянуты» или «не упомянуты», а какую долю от всех релевантных AI-ответов Copilot составляют ваши упоминания.
Это принципиально другая логика. Не позиция в одном ответе, а доля присутствия по всему кластеру запросов категории. Ближайший аналог из знакомых маркетологу метрик, Share of Voice в медиа, только применённый к AI-ответам.
Microsoft называет это нативным инструментом для измерения доли в AI-выдаче. Для GEO-команд это первый шаг к метрике, которую можно показывать руководству без необходимости объяснять, что такое промпт-трекинг.
Четыре метрики, которые реально работают
SEJ предлагает смотреть на кластер связанных запросов и оценивать стабильность присутствия. Переведём это в конкретные показатели.
Стабильность упоминаний (Brand Mention Rate по кластеру). Не «упомянут ли бренд в этом промпте», а «в каком проценте запросов из кластера категории бренд появляется в ответах». Если по 50 запросам категории бренд упоминается в 34% ответов, это BMR 34%. Этот показатель усредняет волатильность отдельных промптов и даёт стабильную метрику динамики.
Доля голоса (Share of Voice) относительно конкурентов. Бренд упоминается в 34% ответов, главный конкурент в 28%. SoV бренда в AI-среде 54%. Это метрика конкурентоспособности, понятная маркетинговому директору без погружения в детали.
Тональность и контекст. Бренд может упоминаться часто, но в осторожном или сравнительном контексте («есть варианты лучше», «некоторые пользователи отмечают»). Метрика факта упоминания это не фиксирует. Тональность нужно измерять отдельно и следить за её динамикой.
AI-трафик с атрибуцией. Нейросети приводят живых пользователей. Google Analytics с мая 2026 года выделяет переходы из ChatGPT, Gemini и Claude в канал AI Assistant. Яндекс.Метрика позволяет видеть трафик из Алисы. Эта метрика замыкает цепочку: упоминание в нейросети привело к реальному визиту и, если всё настроено, к конверсии.
Как изменить отчётность команды
Переход от позиционного трекинга к метрикам стабильности требует нескольких практических шагов.
Перейти от единичных промптов к кластерам. Вместо «мы проверяем 5 промптов» нужно иметь пул из 20-50 запросов, отражающих реальные пользовательские интенты в категории: информационные, сравнительные, транзакционные. Именно по этому пулу считается BMR.
Снимать данные регулярно и усреднять. Разовый срез не даёт достоверной картины из-за волатильности. Нужна серия замеров, ежедневно или минимум несколько раз в неделю. Усреднённое значение по периоду убирает случайные выбросы.
Разбивать метрику по нейросетям отдельно. ChatGPT и Алиса с GigaChat дают разные ответы на одни и те же запросы. Бренд с сильным присутствием в русскоязычном контенте будет выглядеть по-разному в Алисе и в Perplexity. Агрегированный показатель скрывает эту разницу.
Связывать изменения BMR с публикациями. Если после выхода статьи на авторитетной площадке BMR вырос с 12% до 27% по целевому кластеру, это атрибуция контентного действия к видимости в AI. Именно такой отчёт убеждает руководство продолжать инвестиции в GEO-контент.
Для автоматизации этого процесса существуют специализированные инструменты. brandfound измеряет BMR и Share of Voice одновременно по девяти нейросетям, включая российские «Поиск с Алисой», «Чат с Алисой AI» и GigaChat, которые большинство западных инструментов не видят вообще. Отдельный модуль AI-трафика, подключаемый к Яндекс.Метрике, позволяет видеть реальные переходы из каждой нейросети с фильтрацией ботов, чтобы данные в отчёте отражали живых пользователей, а не синтетику.
Что сказать руководству
Одна из причин, по которой команды цепляются за позиционный трекинг: простота коммуникации. «Мы первые по запросу X» понятно любому. «Наш BMR вырос с 14% до 31%» требует объяснений.
Хорошая новость: объяснение простое. В классическом поиске была логика «занять место». В AI-поиске логика другая: «присутствовать в разговоре». Когда пользователь спрашивает у нейросети про категорию, он не листает выдачу, он получает один текстовый ответ. Бренд либо в этом ответе, либо нет. BMR показывает, насколько часто «да».
SoV добавляет конкурентный контекст. «Мы присутствуем в 34% AI-ответов, конкурент А в 28%», это уже язык рыночной доли, понятный на уровне совета директоров.
FAQ
Можно ли совсем отказаться от промпт-трекинга?
Нет. Мониторинг конкретных промптов нужен на операционном уровне: чтобы понимать, что именно нейросеть говорит о бренде, какие источники цитирует, какой тон использует. Но это инструмент для команды, а не KPI для руководства. Перед директором нужно отчитываться в BMR, SoV и AI-трафике.
Почему AI-ответы такие нестабильные?
Нейросети генерируют текст статистически, а не детерминированно. Один и тот же запрос может дать разный порядок упоминаний даже в одной сессии. Добавьте обновления источников через RAG, обновления весов модели и персонализацию, и станет понятно, почему ни один единичный снимок не отражает системного присутствия бренда.
Как быстро меняется BMR после публикации нового контента?
Зависит от платформы. Алиса через поиск Яндекса может проиндексировать свежий материал за несколько дней. Базовые LLM без веб-поиска обновляют знания намного медленнее. Для полного эффекта от публикации разумный горизонт оценки: от 3 до 6 недель.
Bing Citation Share: это то же самое, что BMR?
Близкая идея, но разные данные. Bing Citation Share считает долю цитирований конкретного сайта в ответах Copilot. BMR считает упоминания бренда (в том числе без прямой ссылки) во всех ответах по кластеру запросов. Для полной картины нужны оба типа метрик.
Что в итоге
Рынок AI-аналитики проходит тот же путь, что SEO в 2000-х: сначала копируем метрики из знакомой среды, потом понимаем, что они не подходят, потом выстраиваем новую методологию. Позиции в поисковике были детерминированными, проверяемыми и стабильными. AI-ответы нестабильны, персонализированы и зависят от множества факторов вне контроля маркетолога.
Правильная аналогия для AI-присутствия: не позиция в выдаче, а доля упоминаний в разговорах. Команды, которые перейдут на эту логику раньше, получат отчётность, которой можно доверять, и аргументы для бюджетных решений, которые не рассыплются при первой же нестабильности модели.