Агенты, RAG, MCP: как ИИ вырос из чат-бота в систему

Помните время, когда ChatGPT казался почти волшебным? Ты задаёшь вопрос – он отвечает: связно, иногда даже умно. Казалось, будущее уже наступило. А потом ты спрашивал: «Почём акции Apple вчера?» – и модель либо уверенно сочиняла цифру, либо честно говорила, что не знает. И понимал: под капотом – просто очень умный автодополнитель.
С тех пор прошло несколько лет. ИИ-системы теперь бронируют билеты, пишут код, запускают тесты, лезут в Google Drive, читают Slack, дёргают API и даже делегируют подзадачи другим агентам. Это не тот же чат-бот, просто чуть поумневший. Это принципиально другая архитектура – и история о том, как она появилась, куда интереснее, чем кажется.
LLM – большие языковые модели
Большая языковая модель – это, если совсем честно, движок предсказания следующего токена. Дайте ей текст – она предскажет продолжение, дайте много текста – предскажет очень хорошо. Обучите на сотнях миллиардов слов из книг, статей, кода, форумов – и она начнёт выглядеть как нечто, что понимает.
Запрос: «Столица Франции –»Модель: [предсказывает следующий токен]Ответ: «Париж»
Просто в концепции. Масштаб делает её замечательной.
Но у чистой LLM есть потолок, который наступает ровно тогда, когда начинаешь строить что-то реальное:
- Модель предсказывает правдоподобное, иногда галлюцинируя
- Данные обрезаны датой обучения
- Каждый разговор начинается с чистого листа
- Нет доступа к вашим данным: внутренняя документация, база клиентов, корпоративная вики – всё это для модели terra incognita
- Нет действий – она производит текст, но не может отправить письмо, провести транзакцию или обновить запись
Для бизнеса этого мало. И именно здесь начинается самое интересное.
RAG – модель открывает шпаргалку
RAG (retrieval-augmented generation) – идея, которую можно сформулировать одной строкой: перед тем как генерировать ответ, достань релевантные документы и скорми их модели.
Аналогия из жизни очень точная: это как разница между студентом, который отвечает по памяти (иногда блестяще, иногда – сочиняет), и студентом, которому дали открыть конспект перед ответом. Модель не стала умнее – у неё просто появилась актуальная информация под рукой.
Механизм – в вектором поиске. Документы заранее конвертируются в числовые векторы (эмбеддинги), которые описывают смысл текста математически. «Автомобиль» и «машина» – близкие векторы. «Автомобиль» и «фотосинтез» – нет. Когда приходит запрос пользователя, он тоже превращается в вектор и система находит ближайшие по смыслу документы. Дальше они вставляются в контекст модели – и та генерирует ответ, опираясь на реальные источники.
Для хранения эмбеддингов нужна векторная база данных. Сейчас основные игроки – Pinecone (управляемый, готов к продакшну), Weaviate (open-source, богатые запросы), Chroma (отлично для разработки и небольших проектов), FAISS (быстрый, локальный, без инфраструктуры).
Рынок RAG-решений, кстати, летит вверх: по данным MarketsandMarkets, сегмент RAG оценивается в $1,94 млрд в 2025 году и, по прогнозам, достигнет $9,86 млрд к 2030-му – при среднегодовом темпе 38,4%. Сегодня компании выбирают RAG для 30–60% своих энтерпрайз-кейсов.
Однако RAG решает проблему знаний, но не проблему действий. Система может найти ответ на вопрос «какова наша политика возврата?» – но не провести возврат. Может показать варианты рейсов – но не купить билет. Это принципиальное ограничение архитектуры: она отвечает, но не действует.
Агенты – от «ответить» к «сделать»
Разница между чат-ботом и агентом – это разница между автодополнением и программой:
Обычная LLM:Пользователь спрашивает → модель отвечает → конецАгент:Пользователь ставит задачу → агент планирует →агент вызывает инструменты → наблюдает результат →принимает следующее решение → … → задача выполнена
В основе – паттерн ReAct (reasoning + acting): модель не прыгает сразу к ответу, а проходит цикл «подумать → действовать → наблюдать». И этот цикл повторяется, пока задача не закрыта.
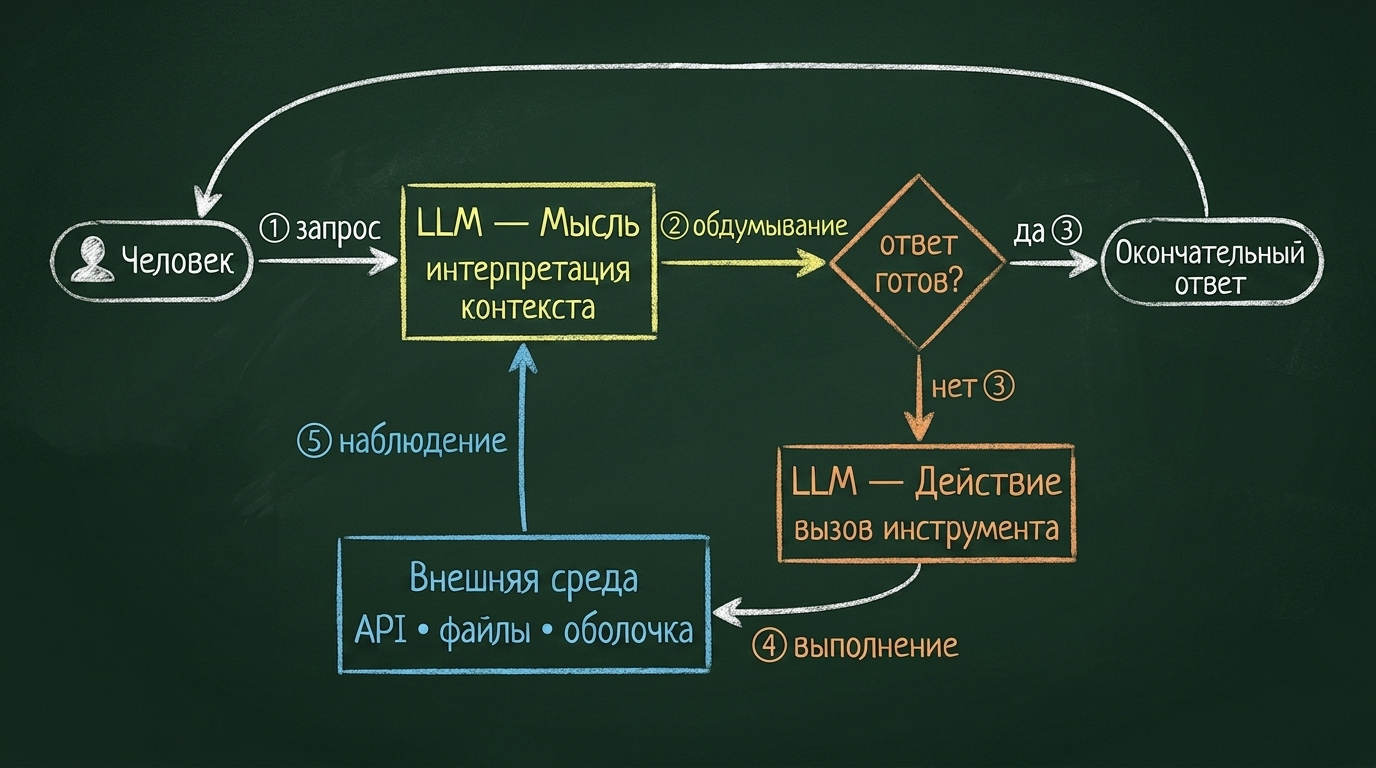
Под капотом всё это – детерминированный цикл на while. Вот минимальная реализация агента на Python, без какого-либо фреймворка:
def run_agent(task: str, client, model: str = "gpt-4o-mini") -> str:messages = [{"role": "system", "content": "Используй инструменты, когда нужно. ""Ответь без вызова инструментов, когда у тебя достаточно данных."},{"role": "user", "content": task},]while True:response = client.chat.completions.create(model=model, messages=messages, tools=TOOLS, tool_choice="auto")message = response.choices[0].messagemessages.append(message)# Ключевая точка: есть ответ или нужны инструменты?if not message.tool_calls:return message.contentfor tool_call in message.tool_calls:name = tool_call.function.nameargs = json.loads(tool_call.function.arguments)result = TOOL_FUNCTIONS[name](**args)messages.append({"role": "tool","tool_call_id": tool_call.id,"content": result,})# Возвращаемся в начало цикла
Список messages – это вся «память» агента в рамках сессии. Каждый вызов инструмента и каждый результат дописываются в него. К моменту, когда LLM решает завершить работу, он «видел» всё, что сделал и чему научился в процессе.
Теперь, если вы используете Ollama с локальной моделью – тот же агентский код работает с буквально одной строкой изменений:
ollama_client = OpenAI(base_url="http://localhost:11434/v1",api_key="ollama", # нужен библиотеке, Ollama его игнорирует)answer = run_agent(task, ollama_client, model="qwen2.5")
MCP – USB-C для ИИ-агентов
В ноябре 2024 года Anthropic представила и сразу открыла исходный код Model Context Protocol – стандарта для подключения ИИ-ассистентов к любым внешним системам: репозиториям контента, бизнес-инструментам, средам разработки.
Аналогия из источника очень меткая: MCP сделал для ИИ то же, что USB-C сделал для устройств. Один кабель подходит к любому источнику данных.
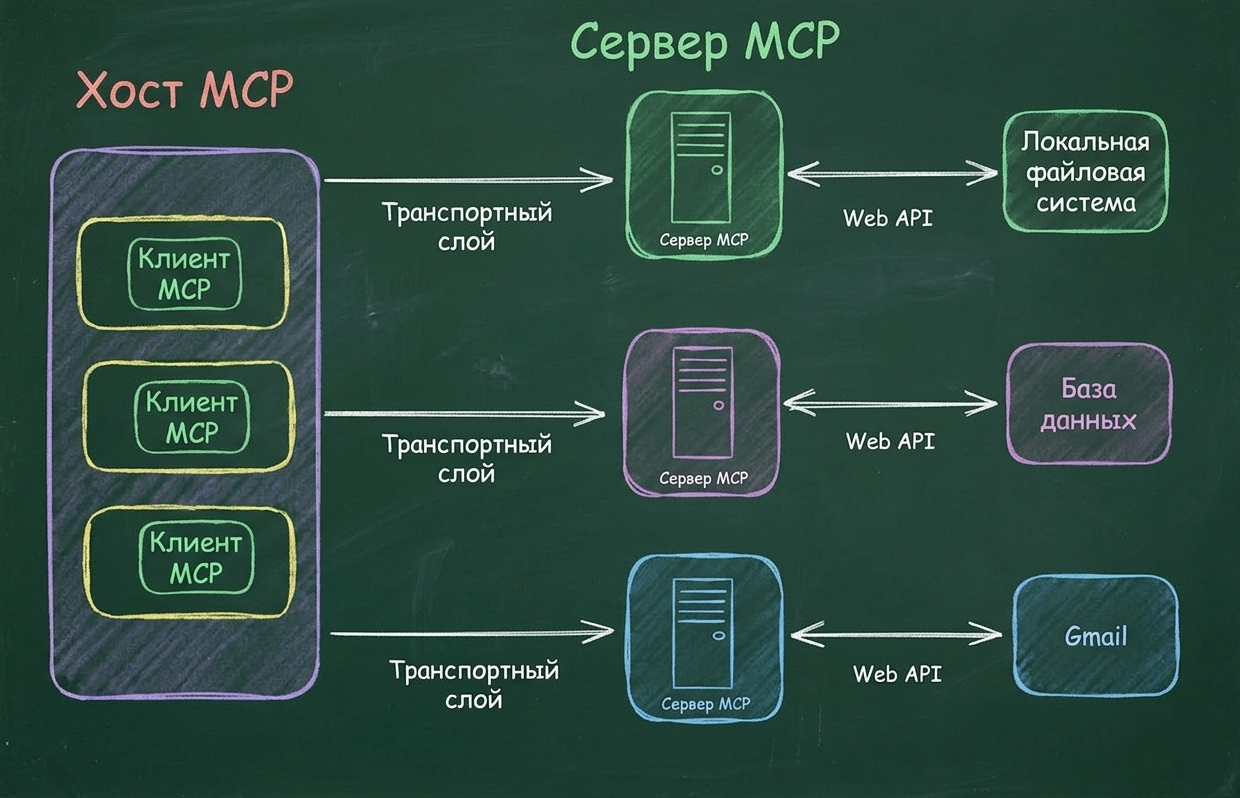
MCP-сервер предоставляет три типа сущностей: tools (действия, которые модель может вызвать), resources (данные, которые модель может читать) и prompts (шаблоны взаимодействия). Клиент (агент) подключается к серверу, узнаёт, что доступно, и дальше вызывает инструменты в структурированном, валидированном формате.
Написать собственный MCP-сервер – проще, чем кажется. Вот полный рабочий сервер в 10 строках Python:
# mcp_server.pyfrom mcp.server.fastmcp import FastMCPmcp = FastMCP("my-tools")@mcp.tool()def to_uppercase(text: str) -> str:"""Переводит текст в верхний регистр."""return text.upper()@mcp.tool()def count_words(text: str) -> int:"""Считает слова в строке."""return len(text.split())if __name__ == "__main__":mcp.run()
Опубликовали – и любой MCP-совместимый агент (Claude Desktop, Cursor, ваш собственный) может пользоваться вашими инструментами. Именно так экосистема масштабируется: вместо того чтобы каждый агент реализовывал «вызов GitHub API» заново, кто-то пишет MCP-сервер один раз – и все используют его.
MCP вырос с 100 000 загрузок в ноябре 2024 года до 97 миллионов ежемесячных скачиваний SDK к концу 2025-го. По данным официального MCP Registry API на май 2026 года, насчитывается почти 10 000 активных публичных серверов.
В декабре 2025 года Anthropic передала MCP вновь созданному Agentic AI Foundation под управлением Linux Foundation.
Контекстная инженерия: дисциплина, которая склеивает всё
Вот где мы переходим к вещи, о которой говорят меньше всего, хотя она, пожалуй, и есть настоящая киллер-фича современных ИИ-систем.
Промпт-инжиниринг – это написать хорошую инструкцию. Контекстный инжиниринг – это спроектировать всю информационную среду, в которой работает модель.
Что входит в контекст агента? Не только история разговора. В продакшен-системе окно контекста содержит:
- Рабочую память – то, что агент активно обрабатывает прямо сейчас
- Эпизодическую память – что происходило в прошлых сессиях, какие ошибки были, какие решения приняты
- Семантическую память – накопленные факты: о пользователе, о кодовой базе, о доменных правилах
- Процедурную память – выученные паттерны поведения, успешные стратегии (тот самый файл CLAUDE.md)
И вот тут начинается самое страшное. Исследование Zylos AI (февраль 2026-го) показало: 65% отказов энтерпрайз-агентов в 2025 году были вызваны не исчерпанием контекстного окна, а деградацией или потерей контекста в процессе многошагового рассуждения. Агенты не падали с ошибками – они продолжали работать, выдавая правдоподобный, но неверный результат. Тихий ад.
Явление называется context drift – постепенное расхождение между тем, что агент считает истиной о своей задаче, и тем, что реально происходит. Механизм простой: каждое действие и каждый ответ дописываются в историю; старый контент конкурирует с новым за внимание модели; ранние ошибки снова и снова всплывают в каждом туре, накапливаясь и усиливаясь.
Как с этим борются на практике
Компакция контекста. Claude Code, когда сессия приближается к лимиту, генерирует структурированное резюме размером 7–12 тысяч символов: что было проанализировано, какие файлы изменены, ключевые архитектурные решения, список оставшихся задач. Плюс пять последних открытых файлов. Этого достаточно, чтобы агент продолжил работу после сброса.
Совет из практики, который действительно важен: не ждите, пока автокомпакция сработает на 95% заполнения. Запускайте её в логических точках завершения задачи – пока состояние ещё когерентное, а не посреди операции.
Паттерн just-in-time. Anthropic описывают, как Claude Code работает с большими кодовыми базами: CLAUDE.md загружается заранее, а содержимое файлов – только по требованию, через glob и grep. Агент не содержит всю кодовую базу в голове, но знает, куда смотреть. Аналог того, как опытный инженер работает с монорепой: он не помнит каждую строку, но мгновенно находит нужное место.
ACON Framework. Предлагает формализовать компрессию контекста не как эвристику, а как задачу оптимизации: находить случаи, где агент успешно справлялся с полным контекстом, но проваливался с сжатым – и анализировать, что именно было потеряно. Итеративно уточнять компрессор, пока он не научится сохранять действительно важное.
Как выглядит современный AI-стек
Серьёзный AI-продукт 2026 года – это не просто API-вызов. Это система:
Пользовательский интерфейс↓Оркестрационный слой (LangGraph/AutoGen/и т. д.)↓Менеджер контекста├── Слой памяти (история, предпочтения пользователя)├── Слой извлечения (векторная БД, семантический поиск)└── Менеджер состояния (прогресс задачи, выводы инструментов)↓Слой инструментов (через MCP или кастомные интеграции)├── Веб-поиск├── Запросы к БД├── API-вызовы├── Выполнение кода└── Файловые операции↓LLM (GPT-4o, Claude, Gemini, опенсорс)↓Ответ + действия
Каждый слой решает конкретное ограничение.
Подведём итоги
Современные ИИ-системы – это архитектуры: системы памяти, пайплайны извлечения, слои оркестрации, экосистемы инструментов, менеджеры контекста и среды выполнения, обёрнутые вокруг модели.
Компании, которые строят лучшие AI-продукты, используют не только лучшие модели – они строят лучшие системы вокруг них.
Если отбросить маркетинговый шум, эволюция выглядит так:
- LLM научил машину говорить
- RAG дал ей актуальные знания
- агенты научили действовать
- MCP стандартизировал, как именно эти действия подключаются к миру
- контекст-инжиниринг стал дисциплиной, которая удерживает всё это вместе.
Каждый шаг – ответ на конкретный провал предыдущего.
И это, наверное, самая важная характеристика всей области: она движется не потому, что кто-то нарисовал красивый роудмэп, а потому, что каждый раз что-то ломается – и кто-то это чинит.