Контекст – это новый код. Ваш агент умнее, чем кажется

Помните то чувство, когда впервые запустил ChatGPT и он выдал что-то осмысленное? Казалось, всё – AGI пришёл, теперь можно просто писать «сделай мне продукт» и идти пить кофе. Прошло два года, и вот ты снова сидишь в три ночи, смотришь, как твой агент на двадцатом шаге начинает звонить инструментам наугад, игнорирует всё, что ты ему говорил в начале сессии, и с гордостью рапортует: «Migration completed», хотя тихо пропустил тридцать записей в базе данных.
Это не магия, не «модель плохая». Проблема в контексте.
И вот тут начинается то, что я считаю самым интересным сдвигом в разработке AI-систем за последние полтора года: контекст – это новый код. Не метафора. Буквально: то, как ты организуешь информацию вокруг модели, определяет успех системы сильнее, чем выбор самой модели.
Почему агенты ломаются не там, где все думают
Есть стандартный путь разочарования. Сначала ты изучаешь промпт-инжиниринг: учишься писать ролевые инструкции, добавляешь few-shot примеры, подбираешь температуру. Для одиночных запросов – работает отлично. Потом ты строишь агента, который делает десять, двадцать, пятьдесят шагов. И тут начинается.
Большинство сбоев агентов сегодня – это не сбои контекста. Когда твой агент выдаёт нерелевантные ответы или забывает предыдущие взаимодействия, в большинстве случаев базовая LLM работает нормально. Проблема в том, какую информацию ты в неё подаёшь.
Ограничение здесь архитектурное. Контекстное окно – это не просто «сколько токенов влезет», а активная рабочая память модели, и она работает не как жёсткий диск, где данные лежат нетронутыми. Она работает как оперативка: чем больше туда напихано, тем хуже всё работает.
LangChain придумал хорошую аналогию: представь LLM как новый вид операционной системы. Модель – это CPU. А контекстное окно – это RAM. Когда RAM заполнена мусором, система тормозит.
Но это ещё не всё. Chroma провела масштабное исследование восемнадцати передовых моделей – GPT-4.1, Claude 4, Gemini 2.5, Qwen3 – и обнаружила кое-что неудобное: каждая модель начинает деградировать по мере роста контекста, причём значительно раньше объявленного лимита. Модель с окном в 200K токенов может показывать заметную деградацию уже на 50K. Не обрыв – плавный, коварный спад.
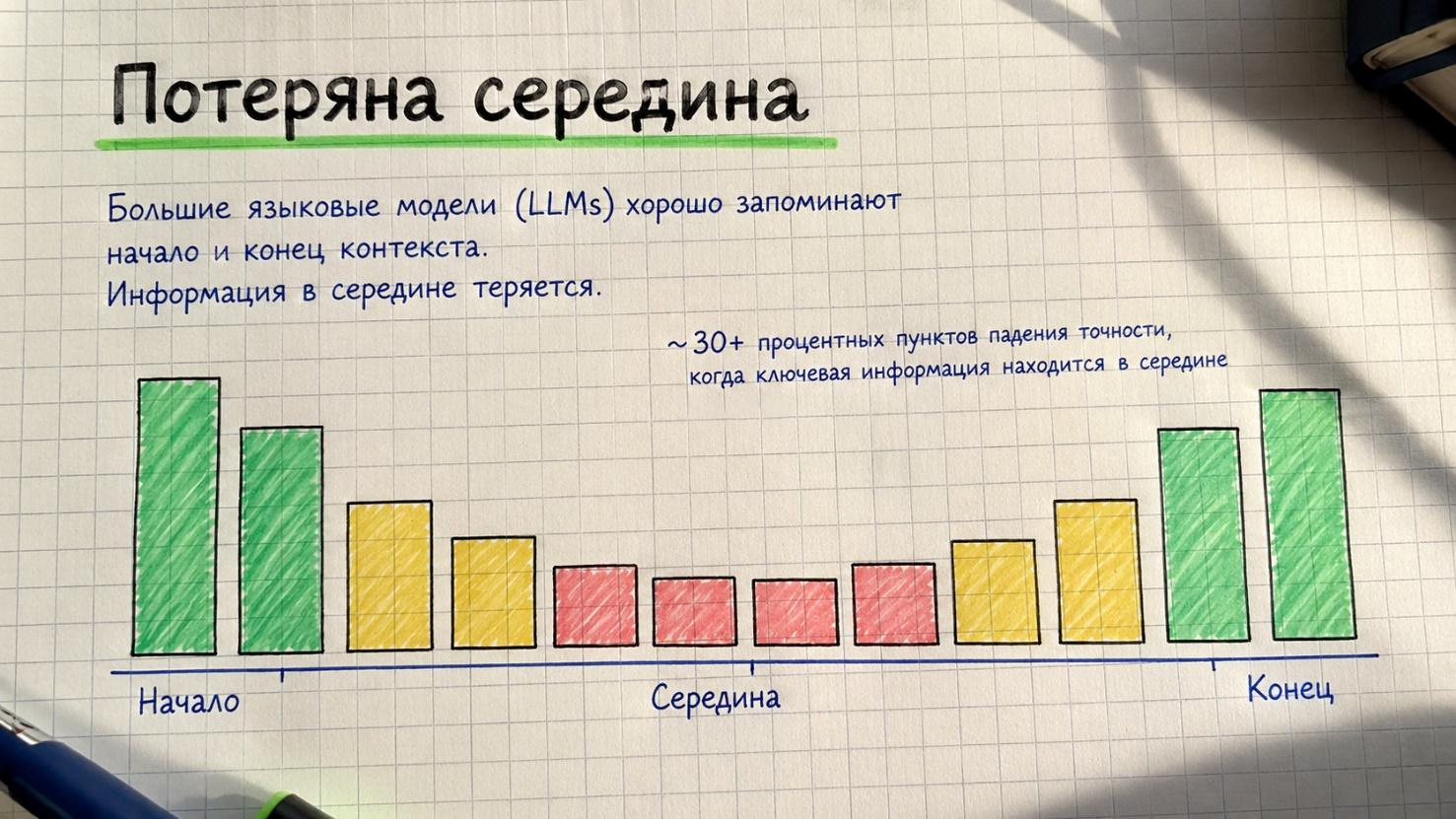
И это ещё не самое страшное. Есть эффект, который исследователи под руководством Liu назвали «lost in the middle» («потеряно посередине»): LLM-модели демонстрируют U-образную кривую внимания – хорошо запоминают начало и конец контекста, но информация в середине просто выпадает. Они измерили падение точности более чем на 30 процентных пунктов, когда релевантная информация перемещалась из начала контекста в середину. Подумай, что это значит для агента, чьи изначальные инструкции погребены под 50 тысячами токенов результатов вызовов инструментов. Они, по сути, исчезают.
На практике это выглядит так: пользователи Claude Code обнаружили, что качество вывода деградирует на 40–60% заполненности контекстного окна – задолго до любого жёсткого лимита.
Что такое context engineering – и чем он отличается от prompt engineering
Классическое промпт-инжиниринг решает один вопрос: «Поняла ли меня модель?» Ты оттачиваешь формулировку, добавляешь примеры, задаёшь роль. Для разовых задач работает.
Контекстная инженерия – это другой уровень. Она отвечает на вопрос: «Видит ли модель нужное в нужный момент на протяжении всей задачи?»
Команда Anthropic определяет это так: контекст – это набор токенов, включённых при семплировании из LLM, а контекстная инженерия – это оптимизация полезности этих токенов для стабильного достижения нужного результата.
Промпт-инжиниринг – подмножество контекстной инженерии. Она включает всё то же самое: чёткие инструкции, хорошие примеры, структурированное форматирование – но добавляет целый слой сверху: управление инструментами, внешними данными, историей сообщений, системами памяти и динамическим состоянием.

По прогнозам Gartner, к концу 2026 года 40% корпоративных приложений будут включать специализированных AI-агентов – по сравнению с менее чем 5% сегодня.
Что вообще живёт внутри контекстного окна
Прежде чем говорить о стратегиях, нужно понять, за что идёт борьба. В контекстном окне агента умещается примерно семь категорий информации.
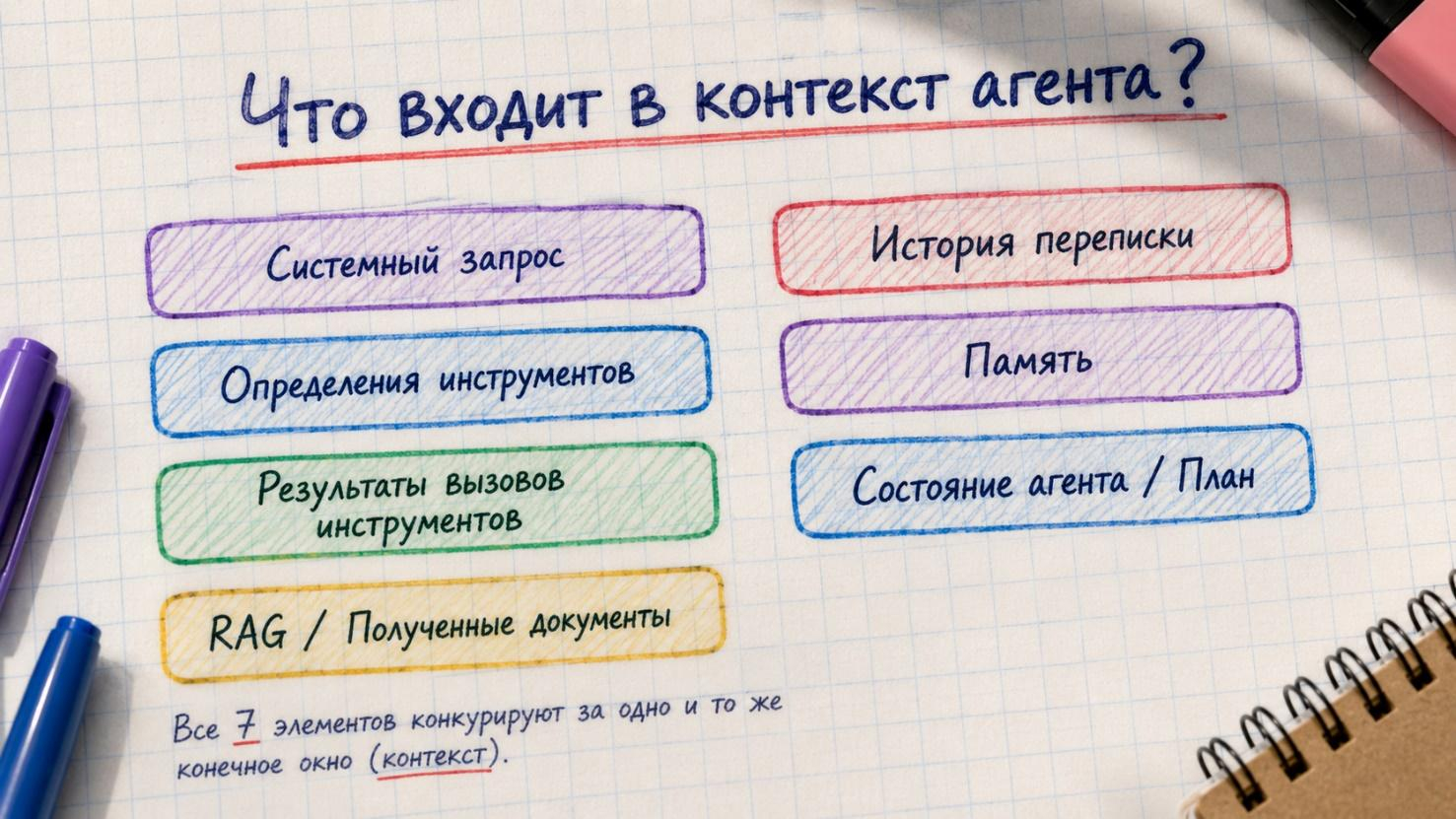
- Системный промпт – «должностная инструкция» агента: поведенческие правила, логика управления, как подходить к разным типам задач.
- Определения инструментов – каждый инструмент, который агент может вызвать, требует схемы в контексте.
- Результаты вызовов инструментов – один запрос веб-страницы может стоить 5–10 тысяч токенов.
- Знания из RAG – документы из векторных баз данных, результаты поиска, API-ответы.
- История разговора – растёт линейно с каждым ходом.
- Память – краткосрочная (текущая сессия) и долгосрочная (предпочтения пользователя, паттерны из прошлых задач).
- Состояние агента – текущий план, список задач, маркеры прогресса, черновые заметки.
Вся эта компания конкурирует за конечное пространство.
Четыре стратегии: фреймворк LangChain
LangChain опубликовал широко цитируемый фреймворк, который организует все техники контекстной инженерии в четыре категории: Write, Select, Compress, Isolate (записать, выбрать, сжать, изолировать).
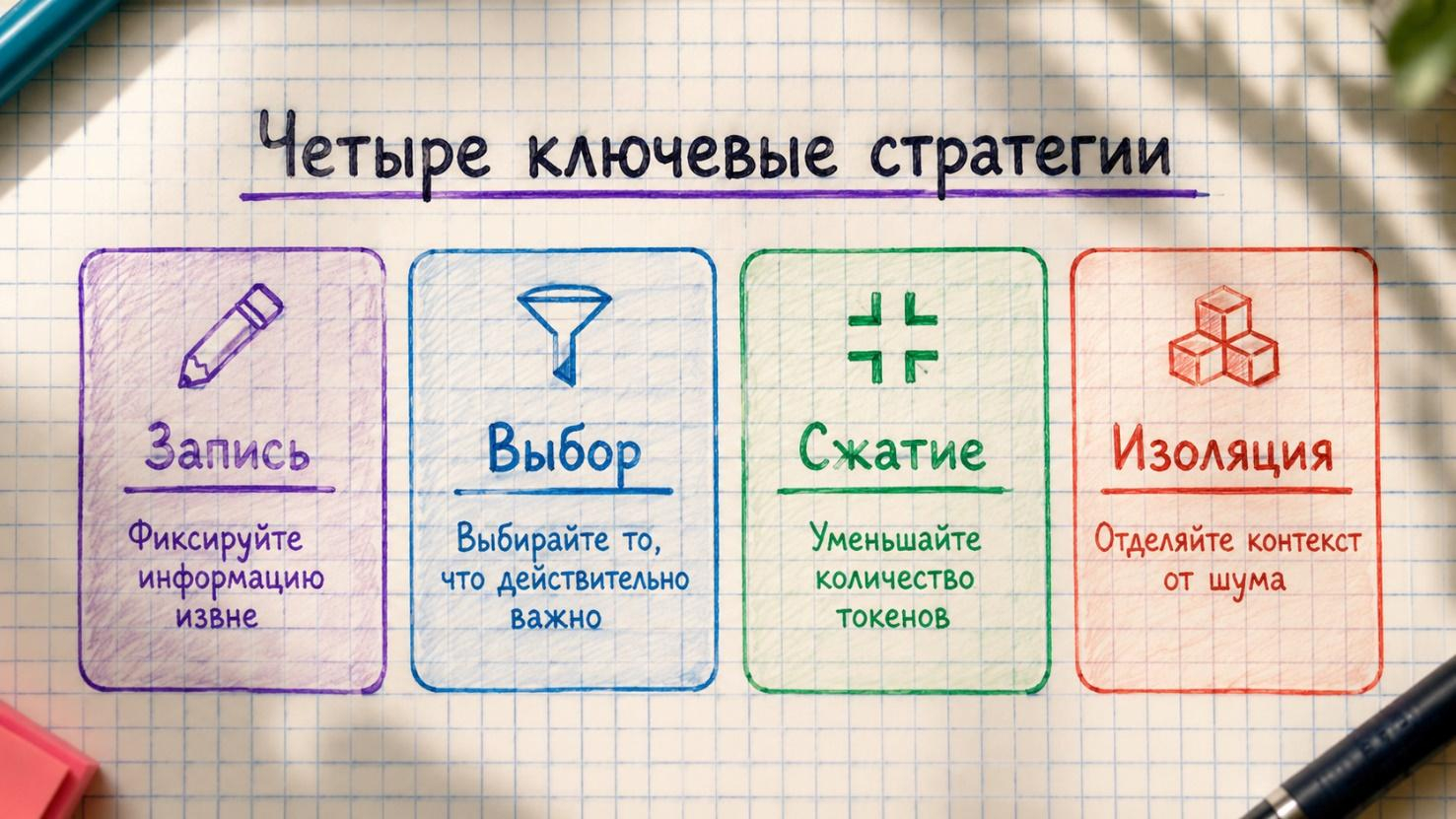
Как только ты знаком с этими четырьмя «вёдрами», любая техника, с которой столкнёшься, окажется в одном из них.
Write: агенты забывают – дай им блокнот
Первая проблема: когда контекст сжимается или сбрасывается, информация просто теряется. Стратегия Write – дать агенту механизмы сохранять информацию вне контекстного окна.
Три формы:
- Блокнот (scratchpad) – инструмент для заметок во время задачи. Anthropic создал «think tool» – выделенное пространство для проработки проблем. На бенчмарке tau-bench это улучшило производительность на до 54% на отдельных задачах.
- Файлы правил – постоянная процедурная память. Если работаешь с Claude Code, видел CLAUDE.md. Это инструкции, загружаемые в начале каждой сессии. Агент читает их при каждом запуске и никогда не забывает фундаментальные вещи.
- Извлечение памяти – сохранение фактов, предпочтений пользователя, усвоенных паттернов для использования в будущих сессиях.
Select: не давай агенту всё – давай нужное
Записать – это хорошо. Но это помогает только если агент в нужный момент достаёт нужное. Стратегия Select: не загружай всё подряд, загружай то, что нужно на этом шаге.
Классический RAG – статический: пользователь задаёт вопрос, ты достаёшь документы, пихаешь в промпт, готово. Agentic RAG переворачивает это: теперь агент сам решает, что искать, какие инструменты использовать, как уточнять запросы, когда информации достаточно.
Но есть одна ловушка, которая попадается чаще всего – инструменты. Если у агента доступ к сорока с лишним инструментам, это уже десять тысяч токенов на определения инструментов до начала какой-либо работы. И это не просто трата места – это активно путает модель.
Исследование RAG-MCP протестировало это: точность выбора инструментов выросла с 14% до 43% (более чем в три раза!), а количество токенов в промпте сократилось примерно вдвое – просто за счёт семантического поиска по описаниям инструментов вместо загрузки всех сразу.

Совет Anthropic: гибридная стратегия. Часть информации загружай в начале (например, CLAUDE.md) для скорости, остальное – по требованию.
Compress: контекст накапливается – сжимай
Даже при хорошей селекции контекст всё равно растёт. Агент сделал двадцать вызовов инструментов – теперь в контексте 80 тысяч токенов накопленных результатов, большинство из которых уже не нужны. Стратегия Compress: уменьшай количество токенов, сохраняя нужную информацию.
Три точки сжатия:
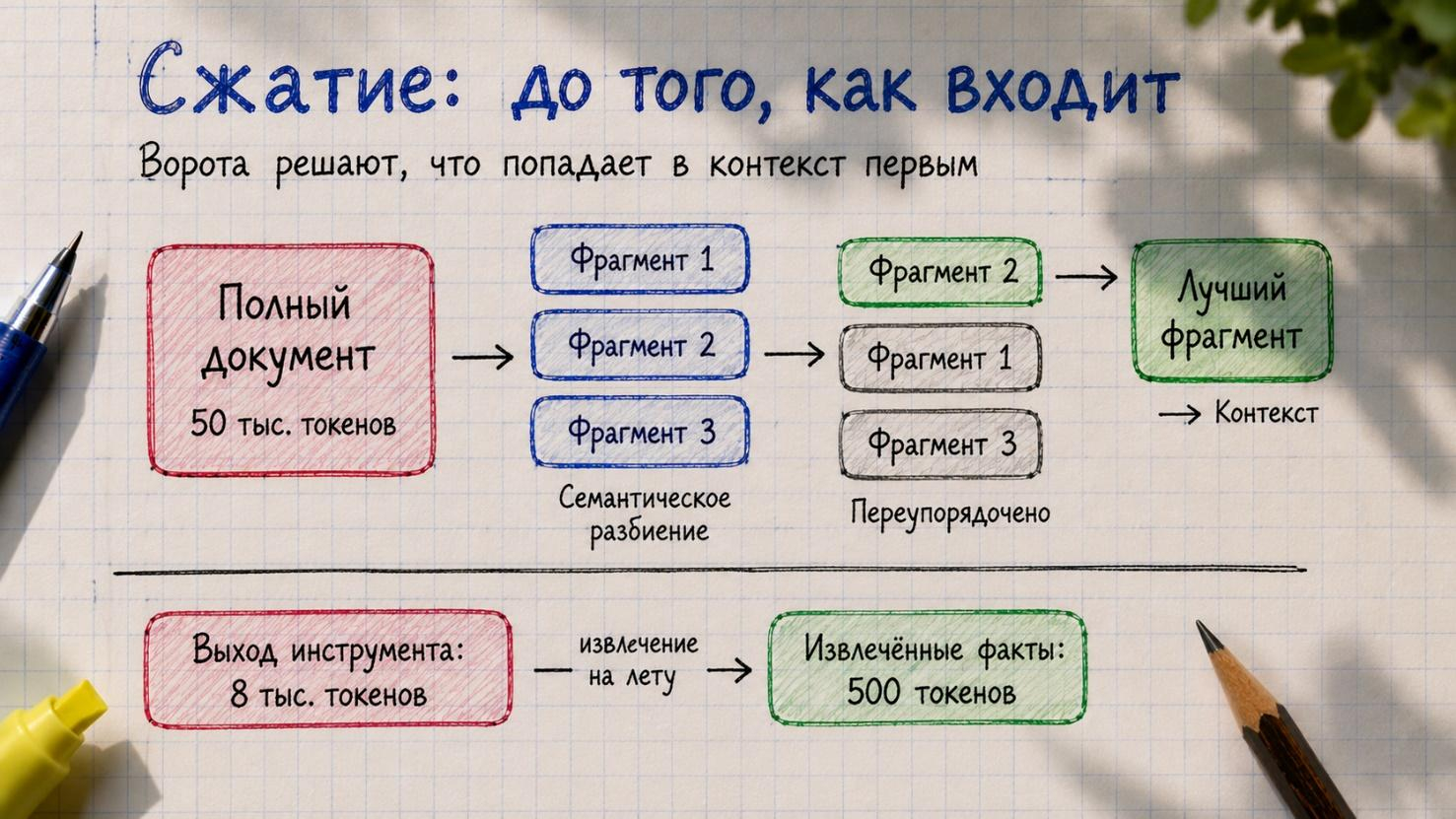
- До входа в контекст: чанкинг (разбивка больших документов на части) и ранжирование, чтобы в окно попадали только самые полезные куски. Суммаризация результатов инструментов на лету.
- Во время работы агента: непрерывно обновляемое резюме истории разговора. Популярный паттерн – гибрид: последние десять сообщений хранятся дословно, всё старшее суммируется. Claude Code сделал автосжатие: когда контекст достигает 95% заполненности, он автоматически суммирует всю траекторию. Это страховочная сетка, но идеально – сжимать проактивно, не дожидаясь аварийного триггера.
- После действия агента: результаты инструментов, которые уже использованы пятнадцать шагов назад, можно просто дропнуть или заменить однострочным резюме.
Isolate: разные задачи – разные окна
Это самая мощная стратегия. Если один агент пытается делать всё – исследовать, планировать, писать код, тестировать, дебажить – в одном длинном разговоре, он неизбежно забьёт контекст. Но проблема глубже: детали поиска из фазы исследования мешаются с фазой имплементации. Старый контекст – это шум.
Решение: разные части работы получают собственные отдельные контекстные окна.
Родительский агент делегирует сфокусированную подзадачу («найди все файлы, связанные с аутентификацией») дочернему агенту. Тот работает в чистом контексте и возвращает только конденсированное резюме. Весь мусор поискового процесса остаётся изолированным – и никогда не загрязняет контекст родителя.
Четыре способа, которыми агент ломается (и как это предотвратить)
Как именно агенты падают по мере роста контекста?
Четыре режима отказа – и каждый из них напрямую связан со стратегиями выше.
Context poisoning (отравление контекста): галлюцинация или ошибка попадает в контекст и многократно на неё ссылаются в последующих шагах. Агент строит дом на кривом фундаменте. Фикс: активное удаление устаревшей или противоречивой информации, валидация результатов инструментов перед добавлением в контекст.
Context distraction (отвлечение): контекст настолько длинный, что модель начинает избыточно полагаться на недавнюю историю вместо базовых знаний. Вместо синтеза нового плана – повторение предыдущих действий. Фикс: агрессивная суммаризация и обрезка, даже при большом окне.
Context confusion (путаница): лишнее содержимое в контексте приводит к некачественным ответам. Классический пример – слишком много инструментов. На бенчмарке GeoEngine квантизированная модель Llama 3.1 8B (* компания Meta запрещена в России) падала при 46 доступных инструментах, но нормально работала при 19. Не потому что не вмещалось – а потому что не могла рассуждать об этом.
Context clash (конфликт): новая информация противоречит уже существующей в контексте. Агент не может разрулить противоречие и ведёт себя непоследовательно. Фикс: чёткая иерархия доверия (системный промпт > извлечённые факты > история разговора), структурированные секции с XML-тегами.
Системный промпт для агента – это не «тон голоса»
Здесь пора поговорить о том, как писать хорошие системные промпты для агентов. Потому что «ты – полезный ассистент, будь лаконичным» – это промпт для чат-бота, а не для агента.
Системный промпт агента определяет архитектуру: как подходить к разным типам задач, какие инструменты использовать в каких ситуациях, что делать при ошибке, какие safety-ограждения соблюдать. Это ближе к написанию должностной инструкции для автономного сотрудника.
Anthropic называет правильный уровень детализации «написанием на нужной высоте»:
- Слишком конкретно – ломается на каждом непредусмотренном крайнем случае
- Слишком расплывчато – агент не знает, какие инструменты когда использовать
Зона Гольдилокса: достаточно конкретно для автономного поведения, достаточно гибко для применения суждения в новых ситуациях.
Практические советы:
– Организуй системный промпт с XML-тегами или markdown-заголовками
– Начни минимально, потом итерируй на реальных фейлах
– Используй few-shot примеры, показывай правильное поведение, а не только описывай
CLAUDE.md: 91 000 звёзд за четыре правила
История с CLAUDE.md – это хороший пример того, как контекстная инженерия работает на практике. Форрест Чанг взял четыре наблюдения Андрея Карпатого о том, как LLM-ы фейлятся при написании кода, и упаковал их в один markdown-файл.Только четыре правила.
## Rule 1 – Think Before CodingState assumptions explicitly. If uncertain, ask rather than guess.Push back when a simpler approach exists. Stop when confused.## Rule 2 – Simplicity FirstMinimum code that solves the problem. Nothing speculative.No features beyond what was asked. No abstractions for single-use code.## Rule 3 – Surgical ChangesTouch only what you must. Clean up only your own mess.Don't "improve" adjacent code, comments, or formatting. Match existing style.## Rule 4 – Goal-Driven ExecutionDefine success criteria. Loop until verified.Don't follow steps. Define success and iterate independently.
Почему это взлетело? Потому что проголосовали не за файл, а за проблему. Каждый, кто использовал AI-агентов в реальной работе, натыкался на одни и те же три стены: тихие предположения, избыточная сложность, расползание скоупа. Файл называет их прямым языком и предлагает фикс, установка которого занимает тридцать секунд.
Я добавил поведенческую секцию в свои CLAUDE.md в тот же день, как узнал про это.
Четыре дополнительных правила для агентного мира
Но – есть в бочке меда ложка дегтя. Правила Карпатого написаны для одиночных промптов. В многошаговых агентных сценариях они не защищают от деградации контекста. Вот ещё четыре правила под капотом, которые закрывают эту дыру:
## Rule 5 – Token budgets are not advisoryPer-task: 4,000 tokens. Per-session: 30,000 tokens.If approaching budget, summarize and start fresh. Surface the breach.## Rule 6 – Read before you writeBefore adding code, read exports, immediate callers, shared utilities.If unsure why code is structured a certain way, ask.## Rule 7 – Checkpoint after every significant stepSummarize what was done, what's verified, what's left.Don't continue from a state you can't describe back. Stop and restate.## Rule 8 – Fail loud"Completed" is wrong if anything was skipped silently."Tests pass" is wrong if any were skipped.Default to surfacing uncertainty, not hiding it.
Правило 5 (про бюджеты токенов) решает проблему, когда агент в цикле сжигает 50 000 токенов, дебажя одно и то же сообщение об ошибке, пока не потеряет голову. Правило 8 – «Fail Loud» – закрывает самый коварный тип фейла: «Migration completed», когда на самом деле тридцать записей тихо пропущены из-за нарушения ограничений.
В реальности после 200 строк инструкций соответствие промпту резко падает и агент просто распознаёт факт наличия правил, но не следует им. Восемь коротких, жёстких, императивных правил дают соответствие выше 75%.
Harness engineering: следующий уровень
Но и это ещё не предел. Есть третья ступень, которую Митчелл Хашимото (создатель Terraform) назвал harness engineering – инженерия упряжи.
Идея проста: каждый раз, когда агент делает ошибку, ты инженеришь постоянный фикс в его окружение, чтобы эта конкретная ошибка не могла повториться. Фикс живёт вне модели – и поэтому остаётся.
Метафора из названия старая: упряжь – это снаряжение, которое надевают на рабочее животное, чтобы направить его силу куда нужно. Модель – это лошадь: быстрая, сильная, совершенно равнодушная к тому, куда ты хочешь ехать. Упряжь – это поводья. И ты их держишь.
Практически это выглядит так: если агент снова и снова тянется к pandas вместо polars – один раз написал в файл конфигурации, что в этом проекте polars. Если тихо использует inner join там, где нужен left join – добавил строчку: «если join может дропнуть строки, скажи об этом явно до написания кода». Каждая строчка в таком файле – это шрам. История ошибок, которые ты отказался делать дважды.
Это не то же самое, что контекстная инженерия. Контекстная инженерия управляет тем, что модель видит. А harness engineering управляет тем, как система действует – через детерминистские механизмы, которые перехватывают, проверяют и при необходимости отменяют действия агента.
Что говорит об этом «context anxiety»
Есть ещё один феномен, который Anthropic назвали context anxiety. По мере того как задача растягивается на десятки шагов и контекстное окно приближается к лимиту, модели начинают вести себя странно – теряют детали, теряют трек цели, ведут себя так, будто торопятся закончить. Они начинают галлюцинировать выводы, пропускать шаги верификации.
Наивное решение – контекстная компрессия: суммировать историю, инжектить резюме, продолжать. Это снижает количество токенов, но не сбрасывает когнитивное состояние или размытие внимания.
Решение, которое работает – более радикальное: рестартовать агента полностью. Anthropic называет это context reflect: взять сжатое резюме и передать его в совершенно свежий инстанс агента – с чистым контекстом, без накопленной путаницы. Это как перезапуск процесса для решения утечки памяти вместо отчаянной сборки мусора.
Как это делают в продакшене
Интересно сравнить, как разные платформы решают эту проблему.
Claude Code – гибридная модель: CLAUDE.md-файлы загружаются в начале каждой сессии для фундаментального контекста, затем just-in-time навигация по кодовой базе через glob и grep. Автосжатие на 95% заполненности контекста с сохранением архитектурных решений и пяти последних файлов. Может запускать дочерних агентов для сложных подзадач.
Manus* – более инфраструктурный подход. Их вклад – KV-cache-aware context ordering: структурирование каждого контекста так, чтобы префикс оставался стабильным между ходами для максимального переиспользования кэша. Tool masking вместо динамического удаления инструментов. Пайплайн компрессии наблюдений перед входом в контекст агента.
ChatGPT Agent – принципиально другой подход. GUI-first: агент взаимодействует с визуальным браузером. Скриншоты добавляются в контекст как визуальные снимки. Визуальные токены дороги, поэтому агент должен быть избирателен. OpenAI использует reinforcement learning для нахождения оптимальных стратегий использования инструментов.
Google ADK – самый «инженерный» подход с тремя архитектурными принципами: отделить хранилище от представления; использовать явные трансформации (именованные, упорядоченные процессоры); по умолчанию ограничивать контекст (каждый вызов модели видит только минимально необходимую информацию).
Что делать прямо сейчас
Вот конкретный план без лишних движений:
- Заведи CLAUDE.md (или аналог) – добавь хотя бы четыре правила Карпатого.
- Начни вести журнал ошибок агента – каждый раз, когда агент сделал что-то не то, записывай. Через неделю ты увидишь систему.
- Отслеживай заполненность контекста – если работаешь с Claude Code или аналогами, заводи привычку делать контекст-ресет около 40-50% заполненности, не дожидаясь автокомпакции.
- Не пайпь сырые результаты инструментов – фильтруй, парси, суммируй перед тем, как результаты попадут в LLM.
- Структурируй большие задачи на фазы – Research → Compacted Artifact → Planning → Implementation. Каждая фаза начинается с чистого контекста.
И главное: каждый раз, когда агент ошибся – вместо того чтобы просто исправить и двигаться дальше, спроси: в каком из контекстов эта ошибка не сможет возникнуть? Положи фикс туда. Не в чат, а в окружение.
Фикс в чате помогает пять минут. Фикс в harness – навсегда.