Почему маленькие модели побеждают большие – и что это значит для вашего стека

Есть такое устойчивое интеллектуальное заблуждение: если модель больше – значит, она лучше. Больше параметров, больше обучающих данных, больше денег в pre-training – и вот вам SOTA. Гонка за размером казалась единственной игрой в городе. Но в 2025–2026 годах что-то сломалось в этой логике. И сломалось публично, с цифрами и бенчмарками.
Я хочу рассказать про три истории, которые произошли практически одновременно и складываются в одну картину. Первая – про то, как Microsoft заткнула за пояс «самую опасную» языковую модель Anthropic с помощью ста специализированных агентов. Вторая – про MIT-трюк, позволяющий маленькой GPT-5-mini обогнать полноразмерный GPT-5 вдвое на сложных задачах. Третья – про китайскую модель Qwen, которую сделала небольшая команда с ограниченными ресурсами и которая сейчас работает в 200 000 продуктах по всему миру. В каждой истории маленький (или менее очевидный) игрок побеждает «большого». И каждый раз причина примерно одна и та же.
История 1. MDASH против Mythos: сто агентов против одного гиганта
В апреле 2026 года Anthropic анонсировала Claude Mythos. Со скандалом. Им сказали: модель настолько опасна для кибербезопасности, что они отказываются выпускать её публично – вместо этого передали 40+ партнёрам под программу Project Glasswing. Правительства были проинформированы. Белый дом обратил внимание.
Шесть недель спустя Microsoft опубликовала пост в блоге. Просто число: 88,45% на CyberGym – публичном бенчмарке UC Berkeley для оценки способности ИИ находить и воспроизводить реальные уязвимости в коде. Mythos набрал 83,1%. GPT-5.5 – 81,8%.
Система Microsoft называется MDASH (Microsoft Security multi-model agentic scanning harness). Это не модель. Это пайплайн из более 100 специализированных агентов, собранный командой, которая выиграла грант DARPA AI Cyber Challenge в 2024 году.
Вот структура этого пайплайна:

Ключевое – в стадии Validate. Аудитор и дебатёр – это разные модели. Если дебатёр не может опровергнуть находку, её вероятность быть реальной возрастает. Одна модель, которую просишь и найти баг, и его же проверить, когнитивно склонна убедить себя, что баг реален; разделение ролей устраняет этот bias.
На приватном тестовом драйвере StorageDrive (никогда не публиковался – значит, не мог попасть в обучение ни одной модели) MDASH нашёл 21 из 21 намеренно посаженных уязвимостей. Ноль ложных срабатываний.
На реальном коде Windows – 96% точности на clfs.sys (28 подтверждённых MSRC-кейсов за пять лет), 100% на tcpip.sys.

И вот что важно: Taesoo Kim, VP Agentic Security Microsoft, сказал это прямо: «The model is one input. The system is the product». Модель – это один из входных параметров. Продукт – это система вокруг неё.
Если раньше казалось, что безопасность определяется мощью базовой модели (и именно из этого исходила логика ограничения Mythos), то MDASH демонстрирует: архитектура системы по крайней мере так же важна, как выбор модели. Техники для построения эффективных пайплайнов (мультиагентная оркестрация, доменные плагины, adversarial validation) не являются секретом.
Пушка не нужна, когда есть сто рогаток с код-ревью.
История 2. RLM: как маленькая модель победила большую, потому что перестала тонуть
В декабре 2025 года группа исследователей MIT CSAIL опубликовала на arXiv статью «Recursive Language Models». Бумага получила на Hugging Face Papers звание «Paper of the Day». Но прежде чем она появилась, в соцсетях разлетелся короткий пост разработчика примерно с таким содержанием:
Агентное программирование без векторных баз данных – это совсем другое ощущение. Просто даю LLM REPL-среду. Она сама исследует сколько угодно длинные промпты, пишет Python. Рекурсивно порождает субагентов. Ответы возвращаются как переменные, не как вставленные стены текста. Никаких JSON-схем или бюрократии. Модель больше не извлекает контекст – она его выполняет.
Звучит как разработческий восторг. Но за этим стоит измеримый результат.
Проблема, которую не любят признавать: context rot
С 2023 по 2025 год индустрия гналась за размером контекстного окна: 4K → 128K → 1M → 10M токенов. Идея была соблазнительной: засовываем весь кодбейз, всю историю переписки – и модель помнит всё.
Нет, не помнит. Это явление называется context rot – термин, который использует сама Anthropic. По мере роста контекста способность модели точно вспоминать информацию из него снижается. Плюс хорошо изученный эффект «lost in the middle»: модели систематически теряют информацию, похороненную в середине длинного контекста – даже когда в изоляции они находят её идеально.
И это не проблема, которую решают покупкой более широкого окна. Внимание размывается по большему числу токенов, позиционные «наводки» нарастают. Были придуманы два обходных пути:
- Compaction: когда контекст слишком вырос, сожми его. Проблема – сжатие с потерями. Вы предполагаете, что ранние данные можно забыть. Часто это неверно.
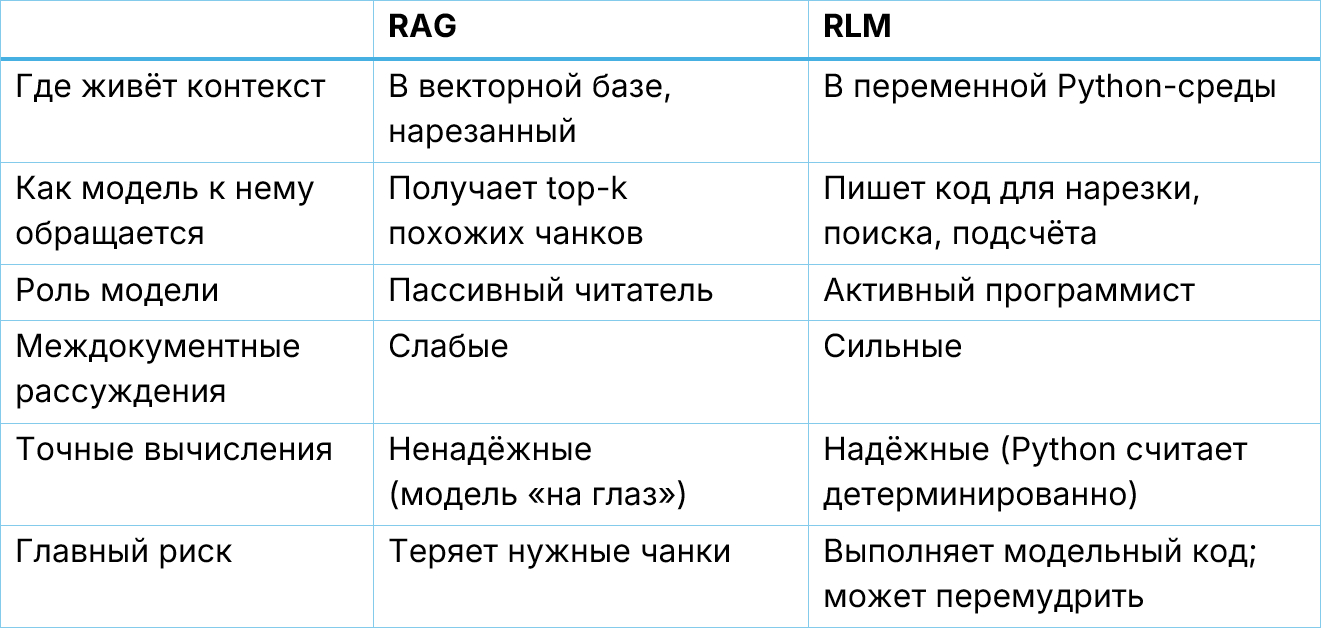
- RAG: режем документы на чанки, кладём в векторную базу, при запросе извлекаем «похожие». Работает хорошо для «найди нужный абзац» – плохо для рассуждений через множество разрозненных кусочков.
Идея RLM в одной строке
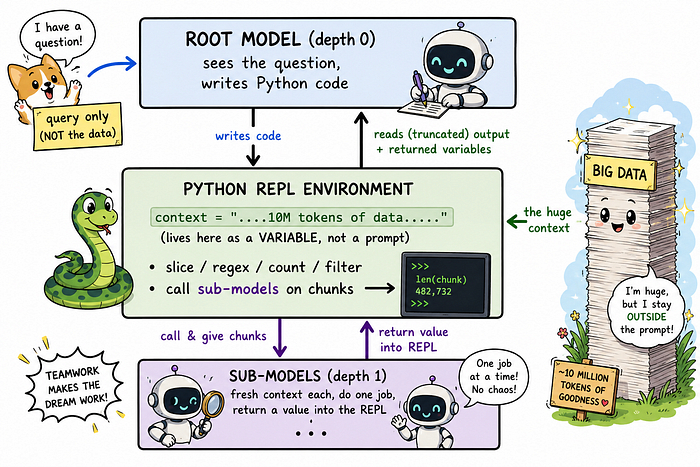
Вместо того чтобы помещать огромный контекст в промпт модели, сохраняем его как переменную в Python-среде и позволяем модели писать код для его изучения.
Это всё. Но уже это большой сдвиг.
Обычная модель – пассивный читатель. Контекст внутри её головы, и она в нём тонет.
В RLM-схеме контекст снаружи, как переменная context в памяти. Модель видит только запрос. Чтобы посмотреть на данные, она должна написать код:
# Модель сначала осматриваетсяlen(context) # насколько большой этот контекст?context[:2000] # как начинается?# Потом находит нужноеimport rehits = [line for line in context.split("\n") if re.search(r"user.*67144", line)]len(hits)# Потом при необходимости порождает субагентовlabels = [llm_query(f"Классифицируй: {chunk}") for chunk in chunks]
Ответ субагента возвращается как переменная Python – не как вставленная стена текста в контекст корневой модели. Корневая модель получает labels – аккуратный список. Она никогда не видит 800 исходных записей. Её собственный контекст остаётся компактным.
Вот сравнение подходов:
Цифры, которые заставляют задуматься
На бенчмарке OOLONG (жёсткий long-context reasoning, 132K токенов) RLM на базе маленькой GPT-5-mini победил полноразмерный GPT-5 с результатом примерно +114% правильных ответов на самом сложном сплите – при сопоставимой стоимости запроса.
Давайте просто вдумаемся. Маленькая дешёвая модель, обёрнутая в RLM, обогнала вдвое большую модель, запущенную «голой».
Почему маленькая модель выигрывает? Потому что сложность задачи была не в интеллекте, а в том, чтобы не утонуть. Дайте скромной модели чистые, узкие подзадачи и детерминированный способ считать (Python не ошибается на 5000 строк; модель, смотрящая на них в лоб, ошибается) – и она обгонит умную модель, пытающуюся удержать всё в голове.
Как говорится: не надо быть умнее – надо не теряться.
История 3. Qwen: как маленькая команда построила самую скачиваемую ИИ-модель в мире
3 марта 2026 года 32-летний инженер Линь Цзюньян написал несколько слов в X: «Ухожу. Прощай, мой любимый Qwen». Акции Alibaba в Гонконге упали на 5,3%. Был объявлен экстренный общий сбор. Прилетел CEO компании.
Западная пресса подала это под рубрикой «китайская корпоративная драма» и двинулась дальше.
Это неверный фрейм.
Линь Цзюньян не просто руководил проектом. Он руководил самым скачиваемым семейством опенсорсных ИИ-моделей на Земле. К январю 2026 года модели Qwen набрали свыше 700 миллионов загрузок на Hugging Face. В декабре 2025-го за один месяц Qwen скачали больше, чем восемь следующих моделей, вместе взятых, – Meta (* запрещена в РФ), DeepSeek, OpenAI, Mistral, Nvidia, Zhipu.AI, Moonshot и MiniMax.
Более 200 000 производных моделей на Hugging Face. Alibaba как организация имеет больше производных моделей на платформе, чем Google и Meta* вместе взятые. Qwen обогнал Llama* как самую используемую базу для дообучения.
Почему это важнее, чем кажется
Обычный нарратив о гонке ИИ:
- OpenAI лидирует по передовым возможностям,
- Google догоняет,
- Anthropic владеет нишей кодинга и безопасности,
- Meta конкурирует в открытых весах,
- Китайские DeepSeek и Qwen – любопытные конкуренты, иногда удивляющие на бенчмарках.
Этот нарратив верен. Но он радикально неполон.
Он рассматривает гонку ИИ как гонку возможностей. Но последние два года параллельно идёт другая – инфраструктурная. Вопрос не только «какая модель умнее сегодня», но «какая модель встроена в инструменты, файнтюны, стартапы и приложения, которые строятся прямо сейчас – и тем самым определяет всё, что будет построено поверх».
По этой метрике Qwen не проигрывал.
Как это удалось небольшой команде с ограниченными ресурсами?
Во-первых, безжалостной итерацией. Qwen вышел в апреле 2023 года. Qwen2 – июнь 2024. Qwen2.5 – сентябрь 2024. Qwen3 – апрель 2025, обученный на 36 триллионах токенов (почти вдвое больше предшественника). Qwen3.5 – февраль 2026: нативно мультимодальный, нативно конкурентный по цене с frontier-моделями.
Во-вторых, пятью крупными поколениями моделей примерно за три года – плюс специализированные варианты: Coder, vision-language, Omni, TTS, Math, Audio, Embedding, Reranker. Всё под Apache 2.0.
Несколько членов команды Qian Wen рассказали изданию 36Kr одно и то же про Линь Цзюньяна: «Имея значительно меньше ресурсов, чем конкуренты, его лидерство – один из ключевых факторов сегодняшних результатов».
Ирония в том, что именно это качество – способность делать много с малым – и было поставлено под угрозу корпоративной реструктуризацией. Tongyi Lab решил разделить команду Qwen – перейти от вертикально интегрированной структуры к горизонтальной (отдельные команды для претрейнинга, посттрейнинга, текстов, мультимодальности и т. д.). Линь выступал за интеграцию. Корпоративный менеджмент – за разделение. Линь ушёл.
Тот самый переход к «регламентированной, продуктово-центричной культуре» угрожает той самой гибкости, которая позволила Qwen обогнать Llama* по числу производных моделей.
Географическое слепое пятно западного AI-дискурса
Есть ещё одна деталь.
Китайские AI-модели в конце 2025 года занимали почти 30% от суммарного AI-трафика на OpenRouter – при 13% в начале того же года. Qwen2.5-1.5B-Instruct (модель на 1,5 миллиарда параметров, запускающаяся на ноутбуке) набрала 8,85 миллиона загрузок и стала одной из самых популярных pretrained LLM в мире.
Что всё это значит вместе
Три истории, одна мысль.
Первая история (MDASH) говорит: для сложных, domain-specific технических задач архитектура системы вокруг модели производит больший выигрыш, чем переход на следующее поколение модели.
Вторая история (RLM) говорит: для задач с длинным контекстом «сложность» была не в недостаточной умности модели, а в том, что модель тонула в объёме. Дайте ей Python и рекурсию – и маленькая модель обгоняет большую.
Третья история (Qwen) говорит: в инфраструктурной гонке побеждает не самая умная модель, а та, на основе которой строят всё остальное. И её строит небольшая сфокусированная команда, не три тысячи инженеров с безлимитным бюджетом.
Это не значит, что большие модели не нужны. Distilled-модель в роли дебатёра в MDASH не может делать то, что делает frontier-модель в роли «тяжёлого разумника». Качество базовой модели важно. Но оно больше не является ни единственным, ни даже главным определяющим фактором.
Есть старая программистская мудрость: «Premature optimization is the root of all evil». Современный аналог для ИИ: premature model scaling is the root of all waste. Прежде чем платить за более мощную модель, спросите: а хорошо ли устроена система вокруг неё? Не тонет ли она в контексте? Специализированы ли агенты? Встроен ли adversarial validation?
Если нет – вы просто покупаете более дорогую точку старта для той же архитектурной ошибки.
Практические выводы
Если вы строите что-то с LLM прямо сейчас, вот что я бы держал в уме:
1. Не выбирайте модель – проектируйте систему. Вопрос «GPT-5.5 или Claude Opus?» менее важен, чем «как устроен пайплайн вокруг модели?». MDASH показывает это на кибербезопасности.
2. Для задач с большим контекстом – попробуйте RLM раньше, чем платить за больше токенов. Если у вас проблема с длинным контекстом, сначала дайте модели Python и REPL. Репозиторий открытый, документация нормальная.
3. Следите за Qwen как базовой модели для файнтюнинга. 200 000 производных моделей – это не академический факт, а данные о том, где живёт экосистема. Попробуйте хотя бы сравнение Qwen-2.5-7B-Instruct vs Llama-3.1-8B-Instruct на ваших задачах.
4. Если вы строите агентов, специализация важна. Один большой агент, которому сказали «делай всё», проигрывает ансамблю специализированных агентов с разными ролями. Идея аудитора и дебатёра в MDASH применима далеко за пределами кибербезопасности.
5. Разделяйте роли рассуждения и действия. Nemotron 3 Super от NVIDIA (120B параметров, 12B активных при инференсе) показывает: в одной модели можно переключать режим рассуждений под задачу. Мощный reasoning – для планирования. Off – для форматирования tool calls. Low effort – для финального синтеза. Один деплой, переменные вычислительные затраты. Это и есть «платить за то, что нужно».