От позиций к цитируемости: как ИИ-поиск меняет SEO-стратегии бизнеса

По данным OpenAI, в 2025 году ChatGPT обрабатывал около 2,5 млрд запросов в день — вдвое больше, чем год назад. При этом только 17% источников, которые цитирует ИИ, входят в топ-10 Google. Остальные остаются за пределами классического SEO.
Причина кроется в сути генеративного поиска. Модель разбивает один запрос на десятки небольших и оценивает не страницу целиком, а отдельные смысловые блоки. Исследование Surfer SEO показывает: если она ранжируется хотя бы по одному из таких подзапросов, шансы быть процитированной вырастают на 161%. Это меняет саму логику работы с контентом. SEO-специалист Roistat Жанна Фадеева рассказывает, как адаптировать стратегию под новые правила и что реально влияет на видимость в ИИ-поиске.
Что происходит с поиском — и почему позиции больше не равны трафику
Поисковые системы изменили сам алгоритм поиска — ответы появляются прямо в интерфейсе. AI Overview от Google занимает в среднем около 1200 пикселей высоты: этого достаточно, чтобы первый органический результат гарантированно уходил за границу видимости на большинстве устройств. В итоге пользователь получает ответ и просто не кликает по ссылкам.
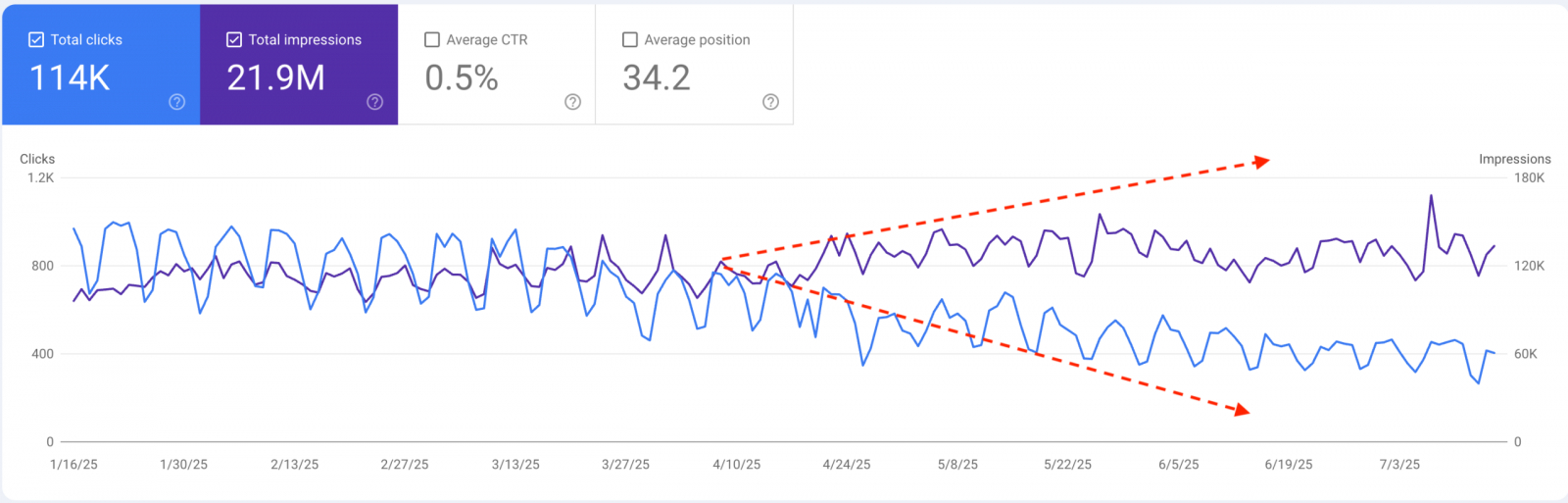
Но SEO при этом не умирает. По данным BrightEdge, общий объём поисковых показов с момента запуска AI Overviews вырос на 49% — люди продолжают искать, но всё чаще завершают сессию внутри ответа без дальнейшего пролистывания страницы. Отсюда парадокс, который уже фиксируют маркетологи: показы растут, позиции сохраняются, а CTR падает на 30% год к году. В информационных нишах падение острее: по информации Ahrefs, на позиции №1 при наличии AI Overview CTR снижается на 34,5%, а на части запросов — до 58%.
Ранжирование и цитирование теперь решают разные задачи. Один механизм отвечает за позицию в выдаче, другой — за вероятность попасть в ответ модели.
Как работает логика ИИ-поиска
Классическое SEO работает на ранжирование: чем лучше страница оптимизирована под интент и ссылочную массу, тем выше позиция в выдаче. Генеративный поиск устроен иначе. Когда пользователь задаёт вопрос ChatGPT, Gemini или «Алисе AI», модель не выбирает одну «лучшую» страницу — она обычно синтезирует ответ из 3-7 доменов одновременно и перерабатывает информацию в связный текст. А сами источники могут находиться далеко за пределами первой страницы выдачи.
При этом аудитория из ИИ-ассистентов часто оказывается более «тёплой», чем органический трафик. По данным Ahrefs и аналогичных исследований 2025–2026 годов, переходы из ИИ-поиска составляют около 0,5% от общего трафика сайта — но генерируют 12,1% регистраций, делая этот канал самым конверсионным в их аналитике. Проще говоря, небольшой поток, но с сильным намерением.
Именно здесь возникает разрыв, который сейчас фиксируют многие аналитические команды. Алгоритм считает страницу релевантной — она в топ-10, — но модель не считает её пригодной для синтеза ответа. В итоге бренд отсутствует в нейросводке, и пользователь даже не узнаёт о существовании компании.
А причина в том, что ИИ оценивает контент по другой логике — и исследования 2025–2026 годов (Growth Advisor, Profound, SE Ranking) фиксируют её конкретные параметры:
- От 44% до 52% цитируемых фрагментов берутся из первых 25–35% текста — модель с высокой вероятностью останавливается на том, что нашла раньше, и не доходит до конца страницы (это так называемый эффект «лыжного трамплина»);
- Материалы, обновлённые за последние 90 дней, цитируются в 2–2,8 раза чаще устаревших;
- Страницы с разметкой FAQ, HowTo или Q&A Schema попадают в ИИ-ответы на 30–60% чаще, чем страницы без структурированных данных;
- Тексты с конкретными цифрами, датами, названиями инструментов и реальными кейсами получают приоритет над обобщёнными объяснениями без фактуры;
- Для «Яндекса» оригинальные русскоязычные исследования и данные имеют приоритет перед переводами зарубежных источников.
Из этого следует важный вывод: GEO — не «новое SEO», а дополнительный слой поверх него. Техническая оптимизация остаётся базой, но сама по себе больше не гарантирует попадание к пользователю. Для модели важны не ключевые слова и ссылки, а прямой ответ в тексте, ясная структура, подтверждённая экспертность и согласованность с другими источниками.
Какие форматы контента сильнее всего страдают от ИИ-ответов
Раз ИИ отбирает источники по своим критериям, не весь контент подвержен изменениям одинаково — и это важно понимать, чтобы правильно расставить приоритеты. Сильнее всего трансформируется информационный контент: статьи формата «что такое», «как работает», «лучшие инструменты». Именно такие запросы модель закрывает собственным ответом охотнее всего — здесь не нужно завершать транзакцию, достаточно просто объяснить детали. Образовательный трафик становится менее предсказуемым, но не менее ценным.
Это означает, что информационный слой верхней воронки должен перестать быть просто способом привлечения трафика любой ценой. Его новая задача — формировать присутствие бренда внутри ИИ-ответов, откуда пользователь может прийти на сайт напрямую. Коммерческий контент пока устойчивее: запросы о выборе поставщика, сравнении тарифов или внедрении продуктового решения нейросеть реже закрывает полностью — ИИ объясняет контекст, но не завершает сделку за пользователя.
Из сказанного следует практический вывод: переписывать весь контент не нужно, но переосмыслить его функцию — необходимо. Статья должна быть не просто оптимизирована под запрос, а пригодна для цитирования. Это разные задачи с разными решениями. Отдельно стоит учитывать брендовые запросы: когда пользователь спрашивает о конкретной компании, ассистент чаще направляет к первоисточнику. Работа над узнаваемостью бренда становится прямым фактором поисковой видимости — и это уже не только задача PR, но и SEO.
Что именно нужно изменить в работе с контентом, чтобы он работал на два канала
Изменения касаются трёх уровней: структуры самого текста, внешнего контекста бренда и — для российского рынка — специфики работы с «Яндексом».
Слой 1. Структура и формат текста
Согласно исследованию Growth Advisor на основе миллионов цитирований, около 44% фрагментов для ИИ-сводки берутся из первых 30% текста. Практически это означает одно: ответ на вопрос должен быть именно в начале статьи.
Отсюда вытекают два практических требования.
- Краткое содержание в самом начале. Для ИИ это маркер, где находится концентрированный ответ на главный вопрос страницы. Если ключевая мысль спрятана в третьем абзаце после длинной предыстории, модель может до неё просто не добраться. Поэтому вводный блок должен содержать прямой ответ на основной поисковый запрос и располагаться сразу под заголовком.
- Заголовки H2, сформулированные как вопросы. Когда пользователь хочет узнать что-то вроде «как настроить сквозную аналитику», модель ищет на странице фрагмент, который прямо отвечает на этот запрос. Абстрактный заголовок - например, "Особенности внедрения" - не дает ей этого сигнала. Заголовок в формате "Как настроить сквозную аналитику за 1 день?" работает иначе: можель сразу понимает, где находится ответ.
Следующий аспект — Schema-разметка. FAQ, HowTo и Article «говорят» модели, где находятся ключевые смысловые блоки, и повышают вероятность их включения в ответ. Интерактивные элементы, графики и визуализации здесь тоже работают: они дольше удерживают пользователя на странице, усиливая поведенческие сигналы, которые алгоритмы учитывают при выборе источников.
Отдельный блок — актуальность. По данным SE Ranking на основе анализа 129 000 доменов, контент, обновлённый в течение последних трёх месяцев, цитируется ChatGPT вдвое чаще устаревшего. Генеративные модели наследуют логику E-E-A-T: свежий материал со ссылками на первоисточники получает больше шансов быть процитированным, чем точная, но давно не обновлявшаяся статья.
Слой 2. Внешний контекст и авторитет бренда
Структура текста — необходимое, но недостаточное условие. Ведь модели учитывают и то, как бренд представлен за пределами собственного сайта. Исследование Profound на основе 680 млн ИИ-цитирований показывает: «Википедия» и широко цитируемые ресурсы появляются в каждом 13-м ответе — модель оценивает не только текст, но и авторитет платформы. Публикации в отраслевых СМИ, экспертные колонки и независимые обзоры улучшают репутацию бренда в глазах модели.
Дополнительный сигнал авторитетности — диверсификация трафика. Сайт, где прямые заходы и социальные сети существенно дополняют органику, воспринимается алгоритмами как более устойчивый источник в сравнении с ресурсом, зависящим только от поиска.
Слой 3. Российский рынок: работа с «Яндексом»
«Яндекс» активно внедряет генеративные ответы через «Алису AI» — и здесь есть локальная специфика, которую важно учитывать отдельно. Алгоритмы «Яндекса» сильнее опираются на экосистемные сигналы:
заполненный профиль в «Яндекс Бизнесе», корректные данные о компании и активные карточки сервисов напрямую влияют на доверие модели. Русскоязычные оригинальные исследования, опросы клиентов и отраслевые отчёты цитируются чаще, чем пересказы зарубежных источников — модель отдаёт предпочтение локальным первоисточникам.
Компании, которые публикуют собственные данные и уникальные инсайты, получают двойное преимущество: повышают шансы попасть в ИИ-ответы и одновременно укрепляют экспертную репутацию на локальном рынке.
Как измерять присутствие бренда в ИИ-ответах
Главная сложность GEO в том, что привычная аналитика перестаёт показывать полную картину. Стандартные Google Analytics и «Яндекс.Метрика» фиксируют только переходы по ссылкам — момент, когда пользователь уже кликнул. Но значительная часть влияния ИИ-ответов остаётся за кадром: человек увидел упоминание бренда в сводке ChatGPT или «Алисы», запомнил его, а позже зашёл на сайт напрямую, через закладки или поиск по названию. Этот «невидимый» эффект, который не привязывается к источнику в стандартных отчётах.
На практике это выглядит так: увеличение прямого трафика всё чаще коррелирует с ростом ИИ-упоминаний. Пользователь видит бренд в сводке — запоминает — заходит напрямую позже. ChatGPT, Perplexity и часть Gemini уже передают UTM-данные при переходе, поэтому источник «AI/Referral» в GA4 стоит отслеживать отдельно.
Для объективной картины нужен комплекс подходов.
- Ручной аудит — база, с которой стоит начать. Раз в 3–4 недели прогоняйте 30–50 ключевых вопросов ниши через ChatGPT, Gemini, Perplexity, «Алису AI» и Google AI Overviews. Фиксируйте, как часто, на каком месте и в каком контексте появляется бренд.
- Настройка аналитики. ChatGPT, Perplexity и Gemini передают UTM-метки — выделите в GA4 сегмент «AI / Referral» с фильтрами по источникам, чтобы отслеживать кликабельную часть трафика.
- Мониторинг упоминаний без ссылок. Системы вроде YouScan фиксируют сам факт отметки, даже когда клика не было.
- Специализированные GEO-платформы. Profound, Goodie AI, Geometrika или российский AI Visibility Monitor позволяют измерять долю голоса в ИИ-ответах и сравнивать видимость с конкурентами.
Мы в Roistat используем всё это в связке: например, настроили отдельные фильтры в системе сквозной аналитики, чтобы выделять трафик из ChatGPT, Gemini и Perplexity по UTM-меткам. А также подключили мониторинг упоминаний в Brandwatch и Brand24 — они фиксируют случаи, когда бренд назвали в ответе, но ссылку не дали. Только так можно увидеть и прямые переходы, и «невидимый» эффект знакомства с брендом.
Приоритетный порядок действий, к которому мы пришли: сначала аудит существующего контента — какие материалы верхней воронки отвечают на главный вопрос в первом абзаце, а какие прячут ответ в конец. Затем переструктурирование приоритетных страниц, добавление FAQ-разметки и актуализация данных. Параллельно — работа над внешними упоминаниями: публикации в профильных СМИ с собственными данными. Оригинальные данные ИИ цитирует с атрибуцией — в отличие от мнений, которые пересказывает своими словами без указания источника.
Но главное: GEO не требует отказа от классического SEO — он говорит о необходимости его переосмысления. Технически здоровый сайт, обратные ссылки и качественный контент остаются фундаментом, на который опираются ИИ-модели при выборе источников. Однако одного фундамента теперь недостаточно. Контент, который создаётся для цитирования, должен давать прямой ответ в начале, говорить языком данных и существовать не только на сайте, но и в упоминаниях, которые модель воспринимает как подтверждение вашей значимости. Без этого даже топ-3 в классической выдаче может полностью исчезнуть из поля зрения пользователя в 2026–2027 годах.
Так что ключевой вопрос 2026 года звучит уже не «как попасть в топ» — а «станет ли ваш контент источником, через который ИИ объясняет рынок вашим будущим клиентам». Поэтому работа с генеративным поиском выходит за рамки SEO-отдела и становится одной из центральных задач редакционной и бренд-стратегии бизнеса.
А чтобы они приносили измеряемую прибыль, Roistat в связке с современными языковыми моделями помогает сделать сквозную аналитику максимально понятной: от атрибуции ИИ-трафика и цитирований до реальной конверсии в сделки и ROI по всем каналам — без ручного сбора данных и «слепых зон».