Пока все пишут с ChatGPT, собственные данные стали самым дефицитным активом в digital
Андрей Кружков, руководитель PRAGMATIX DIGITAL
Ваш контент-план на следующий квартал, скорее всего, написан той же нейросетью и на тех же данных, что и у конкурентов. Алгоритмы Яндекса, Google и ИИ-ассистенты это видят. Они уже решили, кому отдать трафик.
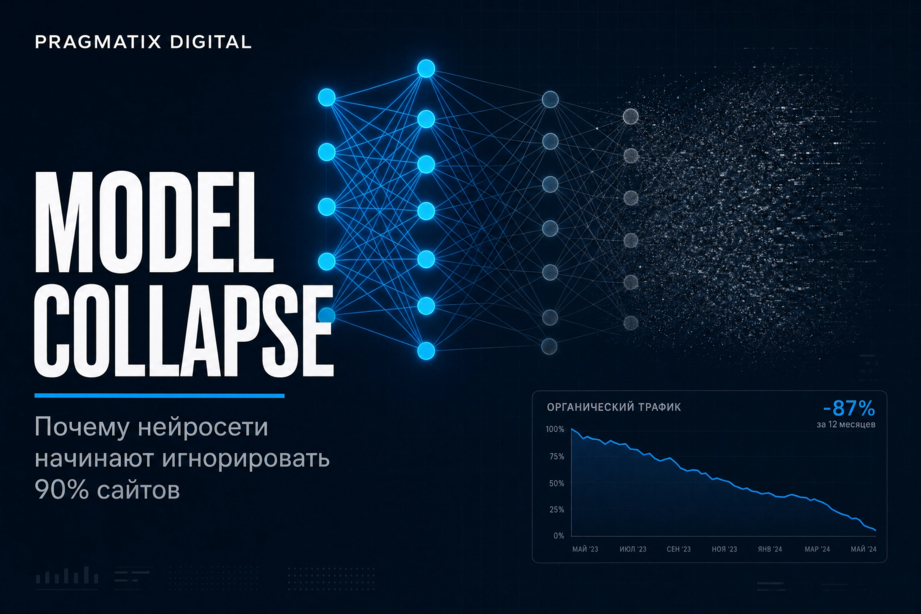
Объем текстового контента в Интернете с 2023 года вырос кратно. Большая его часть — "синтетическая". Потому что digital-агентства, бренды, фрилансеры генерируют тысячи материалов в день на основе 2-3 популярных ИИ-моделей и одних данных. Страницы сайтов как братья-близнецы
Кто уже в нейровыдаче
Первыми спохватились и перестроились отраслевые издания, аналитические агентства, профессиональные сообщества с регулярными опросами аудитории. То есть медиа со своей исследовательской базой. Они не меняли SEO-стратегию, а продолжали публиковать информацию из первых рук.
Среди брендов раньше других это почувствовали те, у кого есть доступ к данным о собственных клиентах, например, финтех, e-commerce, HR-платформы. Публикация статистики по узкой выборке или за определенный период увеличила цитируемость в нейроответах. Раньше этого не удавалось достичь даже сотнями SEO-оптимизированных статей.
Что будет с теми, кто не перестроится
Чем больше сгенерированного контента появляется в индексе, тем выше вес источников с реальными данными в поиске и нейроответах. Бренды, продолжающие массовую генерацию, постепенно выпадают из поля зрения алгоритмов. Позиции в органике при этом могут не меняться. Но трафик уходит, потому что человек получает ответ прямо в нейроответах , над списком ссылок. На сайт он идет только за деталями и только к тем, кого ИИ уже процитировал.
Читайте также: Алгоритмы не думают, а обрабатывают сигналы. Почему SEO остается фундаментом в эпоху нейровыдачи
GEO за 300 000 рублей
На рынке активно предлагается услуга GEO-продвижения, позволяющая усилить присутствие бренда в ответах генеративных ИИ. Стоит это 80-300+ тысяч рублей в месяц, в зависимости от ниши. Результат оценить крайне сложно. Логика алгоритма закрыта, связь между определенными действиями и конкретным итогом не измеряется.
Да, конверсия пользователей из нейроответов действительно высокая. Но тут надо понимать, что она отражает поведение тех, кто кликнул, а не всего потока. Остальные получили ответ внутри интерфейса и не перешли на сайт. Значит, Метрика их не показывает. Оценивать эффективность канала из такой выборки некорректно.
Для крупного бренда платный GEO оправдан как инструмент раннего захвата нейровыдачи. Для среднего и малого бизнеса это переплата за то, что в принципе достигается через контент с реальными данными.
Читайте также: Агентства продают первое место в нейросети. Технически это невозможно
Как алгоритм решает, кого процитировать
Яндекс при формировании нейроответа каждый раз просматривает небольшой пул документов. Попасть в него можно без ТОП-5 в органической выдаче. Алгоритм ищет страницу, где в первых 40-60 словах раздела есть прямой ответ на вопрос. Страница на 15-й позиции с такой структурой выигрывает у страницы на 3-й без нее.
Google строит ответ иначе, чем Яндекс. Один запрос разбивается на десятки подзапросов. Под каждый из них алгоритм ищет отдельный источник с данными, отсутствующими у остальных. Perplexity делает то же самое, показывая дополнительно читателю ссылки на те страницы, из которых собран ответ. А это прямой трафик на сайт, если ваш материал попал в подборку.
Мы в PRAGMATIX DIGITAL работаем сейчас десятками сайтов в разных нишах. B почти везде одна закономерность. Страницы с уникальными данными (пусть небольшими, узкотематическими) начали попадать в нейроответы. Причем, даже там, где раньше проигрывали более авторитетным доменам.
Отсутствие данных — не приговор
Здесь многие останавливаются. Собственных исследований нет, бюджета на них тоже. Но задача решается проще, чем кажется.
Сведения, которых нет ни у одного вашего конкурента:
- опрос 50 клиентов через форму в рассылке;
- разбор собственной воронки за год с конкретными цифрами по этапам;
- нестандартная разбивка публичной статистики по своему сегменту рынка, которую никто не делал.
Алгоритму не интересна цена вашего исследования. Он видит только то, есть ли на странице абсолютно информация или нет.
Позиции в поиске после апдейта восстанавливают за несколько месяцев, а место в нейровыдаче — нет. Конкурент вытеснит вас оттуда, когда у него будет уникальная информация. Именно она сейчас настоящий актив в контент-маркетинге,.
Источники: Nature, 2024 (Model Collapse, Шумаилов и др.); Kokoc Group, 2025; Принстон / IIT Дели, 2025; Google Patents — обзоры искусственного интеллекта, получение информации; Пагадала В., SSRN, 2026; Такер Д., SSRN, 2025.
.
П.
Материал подготовлен агентством PRAGMATIX DIGITAL на основе исследований Nature (2024), данных SparkToro, анализа AI Overviews и собственных наблюдений по digital-маркетингу.
Источники
[1] Pagadala, Venkata. "The Disruption of Search Engine Optimization by Large Language Models." SSRN (2026). URL:
[2] Thacker, Drew. "The Zero-Click Paradigm." SSRN (2025 ). URL: