13 идей для pet-проектов на Python – для аналитиков данных, разработчиков и Data Scientist

Ни для кого не секрет, что IT – одна из самых быстро меняющихся сфер, поэтому чтобы расти в карьере, IT-специалисты постоянно развиваются и учатся новому.
Но есть в IT и вечные тренды. Например, это Python – он появился в 1991 году, в 2000-х стал популярным в веб-разработке, а с началом развития Machine Learning и ИИ буквально поселился в этой отрасли. Да и в целом считается одним из самых востребованных языков программирования.
Благодаря своей универсальности Python используется почти во всех IT-сегментах, а IT-специалисты, чтобы оставаться востребованными, в свою очередь, заинтересованы в том, чтобы постоянно оттачивать навыки работы в Python. Одним из способов, которые могут в этом помочь, являются пет-проекты. О них сегодня и пойдет речь.
Мы изучили интересные и перспективные идеи для пет-проектов на Python, отобрали 13 из них, которые будут интересны разработчикам, аналитикам и дата-сайентистам. Этот материал будет полезен тем, кто только начинает изучать Python, стремится улучшить знание языка, показать свои навыки с выгодной стороны и получить новый грейд или классный оффер.
Проекты для разработчиков
Идеи для пет-проектов часто выбирают из интереса или ради развлечения, основанием может стать желание разобраться в инструменте на практике или создать сервис мечты, которого пока нет в интернете.
Иногда проект может пересекаться с карьерными планами. Особенно это актуально для junior-разработчиков: перекос на рынке труда, связанный с большим количеством выпускников IT-школ, вынуждает компании выбирать преимущественно опытных специалистов. Интересные и перспективные пет-проекты для Python могут помочь выделить новичка из десятка других кандидатов и доказать уверенное владение языком.
Далее мы поделимся пятью пет-проектами: тремя для начинающих и двумя для более опытных разработчиков.
Новичкам
Бот для мессенджера
Для junior-специалиста пет-проект на основе бота – отличный способ набраться опыта в работе с API и HTTP-запросами. В качестве примера мы возьмем алгоритм, присылающий длину светового дня, время рассвета и заката в любой день и в любой точке мира.
Описание проекта: соберем геоданные через API Яндекс.Карты или Google Maps, а данные светового дня – через Sunrise-Sunset API или Open-Meteo API. Последний сервис позволяет настроить и выдавать не только длину светового дня, но и полноценный прогноз погоды – при желании можно вбить в API дополнительные параметры и расширить проект. Обработаем информацию с учетом часового пояса, вычислим длину светового дня и отформатируем всё для вывода.
В нашем блоге мы уже публиковали статью о том, как создать свой чат-бот в Telegram, используя Python, а затем развернуть его на VPS. Если вы тоже решите разместить свой проект на сервере, облачная платформа Beget может подойти: при создании VPS вы можете развернуть бесплатные готовые решения для работы с Python в один клик, например, Django пригодится для развертывания веб-приложений, а PostgreSQL и MongoDB – для хранения и управления данными.
Простая игра
Если GameDev – это ваша сфера мечты, алгоритм для создания простой детской игры может стать кандидатом в портфолио начинающего разработчика.
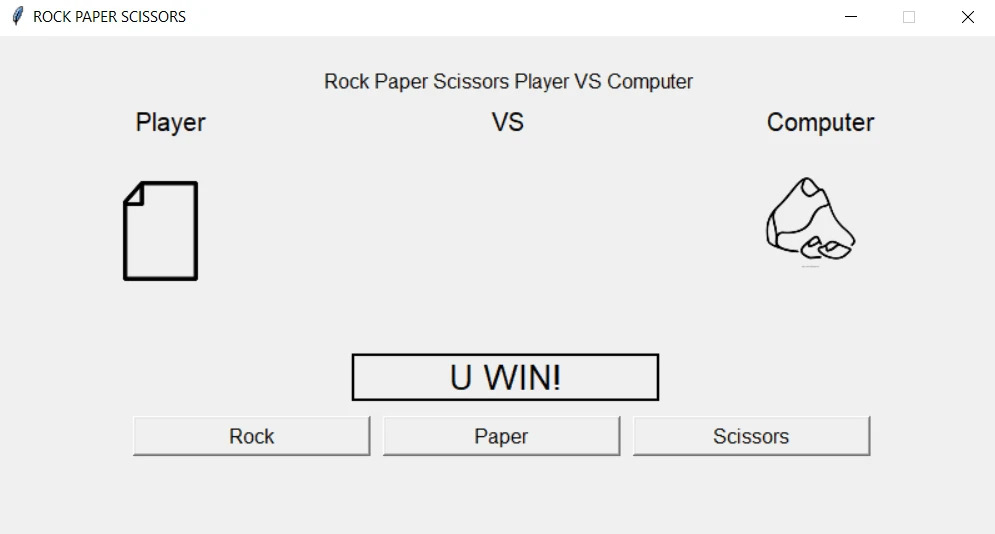
Описание проекта: реализуем игру “Камень-ножницы-бумага”, в которую можно играть в одиночку против программы. Пользователь вводит свой выбор с клавиатуры, а программа рандомно генерирует выбор компьютера. Затем сравниваются ходы и определяется победитель.
Вот какие навыки он помогает прокачать: генератор случайных чисел, ввод/вывод в консоли, работа с циклами (while), условные операторы (if/else), базовая логика игры, обработка пользовательского ввода.
Так может выглядеть интерфейс простой версии игры:
Парсинг сайта
Парсинг – процесс автоматического сбора и структурирования данных из внешних источников. Разработчики сталкиваются с ним уже на младших позициях, поэтому джуну в IT будет полезно его освоить.
Для примера возьмем сайт “Авито”.
Описание проекта: создаем алгоритм, который будет заходить на сайт, просматривать объявления по запросу – например, “Снять дом в Ленинградской области посуточно”. А затем – записывать данные из объявлений в текстовый файл.
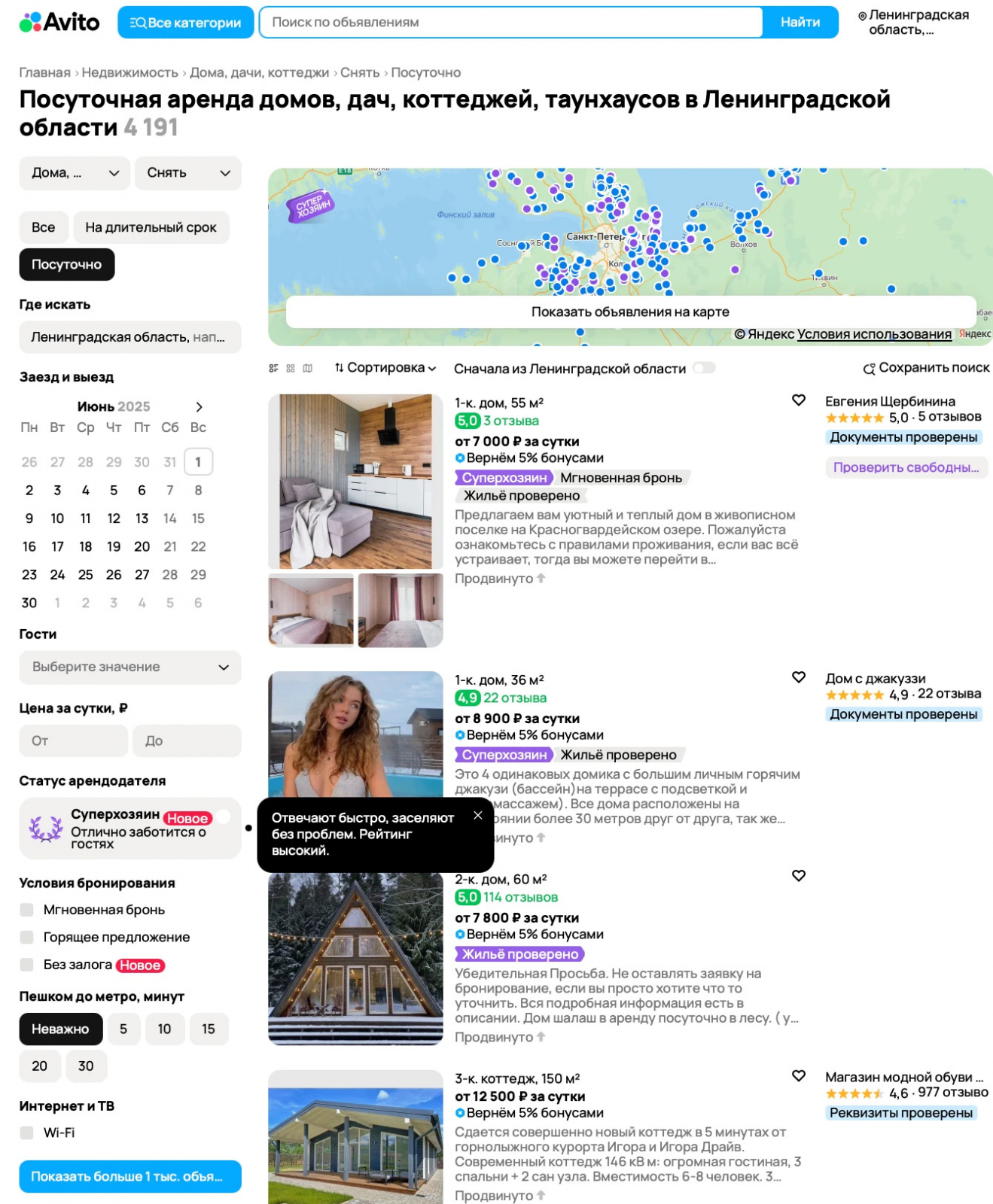
Для работы с сетевыми запросами понадобится модуль requests, для разбора и получения информации из HTML-кода сайта – библиотека BeautifulSoup. Разработка парсера позволит прокачать знание сетевых протоколов HTTP/HTTPS, формата JSON, HTML/CSS-кода, семантики, DOM-модели веб-страницы и многих других технологий.
Опытным
Интерактивная карта цен
Работа с картами – важное умение Python-разработчика. Они нужны не только в условном “2ГИС”, но и в различных приложениях и на сайтах.
Описание проекта: создадим приложение – интерактивную карту цен на любимый вид кофе в городе. Соберем цены путем парсинга сайтов-агрегаторов кофеен (например, restoclub.ru или afisha.ru), а преобразовать адреса в координаты помогут API Яндекс.Карт, OpenStreetMap или Google. Сохраним всё в таблицу CSV или JSON и построим карту с Folium.
Если вам захочется продемонстрировать еще и навыки работы с БД, можно поднять на VPS базу данных на базе SQL, записать в нее данные и продолжать проект уже в ней.
Проект поможет прокачать навыки парсинга, работы с API и с данными через Pandas, знание CSV, JSON и умение создавать карты через Folium.
Сканер покупки
А этот pet-проект тренирует навыки обработки естественного языка, распознавания символов и работы с Machine Learning.
Описание проекта: возьмем алгоритм, сканирующий ценники на товарах и оценивающий выгоду от покупки. Для сбора данных подключим парсинг сайтов нескольких магазинов для сравнения.
Бот считает цену за 100 г или 1 л и говорит: “Дорого!” или “Выгодно!” и может предложить приемлемый вариант покупки в другом месте.
Проект позволяет прокачать навыки работы с изображениями и OCR, обработки естественного языка и текстов, математической логики, автоматизации и парсинга сайтов.
Проекты для аналитиков
Основные рабочие процессы дата-аналитиков – это составление прогнозов, классификация данных и, само собой, глубокий анализ.
Пет-проекты для аналитика данных интересны тем, что дают возможность поработать с реальной информацией, сделать собственные выводы, которые могут быть полезны организациям или обычным пользователям.
Разберем четыре таких проекта, два для начинающих и два – для опытных специалистов.
Новичкам
Анализ частоты использования слова
Дата-аналитикам часто приходится обрабатывать большие массивы данных, вытаскивая оттуда слова-маркеры для их классификации. В работе этот навык используется, чтобы выделить удачные формулировки в рекламе и письмах, определить, по каким запросам пользователи приходят на сайт из поисковых систем и т. д.
В качестве примера такой задачи узнаем, как часто используется слово “убить” в “Преступлении и наказании”.
Описание проекта: извлекаем html-файл произведения с любого сайта, используя пакет Python requests, а через библиотеку BeautifulSoup – текст из веб-данных. Анализируем распределение слов с Natural Language ToolKit (nltk), удалив из текста стоп-слова и через стемминг приводим их к основной словарной форме, удаляя окончания и суффиксы.
В ходе работы над проектом можно прокачать знание HTTP-запросов, навыки парсинга html-страниц, Natural Language Processing и визуализации данных.
Подобный проект, только на основе романа “Моби Дик”, вы можете найти на сайте обучающей IT-платформы DataCamp.
Алгоритм, предсказывающий зарплату для вакансий со скрытым доходом
Прогнозирование чего-либо на основе имеющихся данных – типичная задача дата-аналитика, которая может стать основой для пет-проекта.
Описание проекта: алгоритм, предсказывающий зарплату для вакансий на hh.ru, если она не указана. Берем одну позицию, через hh.ru API собираем данные о вакансиях с прописанным доходом и без него.
Преобразовываем текстовые поля через TF-IDF векторы или Embeddings (например, через SentenceTransformers). Кодируем категориальные данные с помощью One-Hot Encoding или Label Encoding. Строим модель: разбиваем датасет на 2 выборки, выбираем базовую модель, задаем целевую переменную, обучаем на тренировочных данных и прогоняем скрытые вакансии через модель. Этот путь может повторяться многократно, пока вы не найдете модель, которая лучше всего работает на тесте и не переобучена.
В ходе работы вы прокачаете знание API, умение чистить и готовить табличные и текстовые данные, работать с ML-моделями, интерпретировать и визуализировать данные.
Опытным
Алгоритм, анализирующий и классифицирующий виды птиц
Этот pet-проект на Python прокачает умение работать с базами данных, изображениями, навыки Pandas и Machine Learning.
Описание проекта: ваша задача – создать алгоритм, который анализирует и классифицирует виды птиц. Для работы соберем данные с БД eBird или GBIF (Global Biodiversity Information Facility), изображения и метки-названия видов. Затем обработаем данные – очистим их, уменьшим изображения и, если надо, создадим метки для изображений с Pandas.
Используем модели нейросетей ResNet, VGG16 или MobileNet для классификации полученных картинок.
Анализ новостей на предмет “фейковости”
Если раньше отделить правду от вымысла в СМИ было непросто, то сегодня у нас есть IT-алгоритмы – один из них на основе Python мы возьмем как инструмент для пет-проекта.
В качестве источника подойдут наборы данных Fake News от Kaggle. Обрабатываем датасет с библиотекой Pandas. Дальше нам поможет класс моделей глубокого обучения для работы с последовательностями данных Sequence to Sequence.
Данные мы предварительно очистим, векторизируем текст и обучим модель на тренировочной выборке. Точность классификации можно проверить на тестовом датасете.
Проект помогает прокачать навыки Machine Learning, обработки текста (NLP), Pandas, Scikit-learn, PyTorch или TensorFlow, визуализации данных и работы с Kaggle.
Проекты для дата-сайентистов
Учитывая, что Python – один из ключевых языков для AI и Machine Learning, он открывает огромное поле для экспериментов. Здесь можно моделировать различные сценарии, искать зависимости, проверять гипотезы и т. д.
Разберем четыре Data Science проекта, с помощью которых новички и опытные специалисты прокачают умение строить модели и делать прогнозы на основе данных.
Новичкам
Алгоритм, прогнозирующий лучшее время для покупок на маркетплейсах
Алгоритм способен проанализировать данные предыдущего периода, увидеть закономерности и предсказать лучшее время для покупок в интернет-магазинах.
Описание проекта: выбираем категорию, парсим данные из маркетплейса, строим временной ряд (дата – цена), анализируем закономерности, строим модель прогнозирования (например, скользящее среднее или ARIMA) и делаем дашборд.
Проект поможет улучшить навыки парсинга, работы с временными рядами, визуализации данных, feature engineering и базовых алгоритмов ML/DS.
Прогнозирование оттока клиентов
Это стандартный для рабочей рутины Data Science специалиста тип пет-проектов. Он продемонстрирует умение работать с Pandas, проводить EDA (исследовательский анализ данных), строить и оценивать модели.
Описание проекта: берем данные из Telco Customer Churn Dataset (из Kaggle) или Churn Prediction Dataset, загружаем с Pandas, очищаем, проводим EDA и анализ целевой переменной (Churn), строим модель (дерево решений, случайный лес или логистическая регрессия), оцениваем модель и интерпретируем результаты.
Опытным
Алгоритм, прогнозирующий вероятность лесных пожаров
Лесные пожары – мировая проблема, над решением которой работают разные специалисты, включая дата-сайентистов. На Github можно найти пет-проект, прогнозирующий пожары в Алжире, мы же потренируемся на России.
Описание проекта: собираем информацию о пожарах с сайта “Рослесхоз” или МЧС России, а метеорологические данные – с Gismeteo. Затем – данные о лесах, их типах и плотности. Очищаем данные, обрабатываем временные ряды, кодируем типы лесов или местоположение с помощью One-Hot Encoding или Label Encoding.
Анализируем зависимость пожаров от погоды, времени года, визуализируем с Folium или Geopandas, строим корреляционные матрицы для оценки взаимосвязи. Строим модель Machine Learning – например, логистическую регрессию, Случайный лес (Random Forest), Градиентный бустинг (XGBoost, LightGBM), ARIMA или Prophet, LSTM или GRU.
Наконец, оцениваем модель с помощью метрик: Accuracy, Precision, Recall и F1-Score для классификации.
Исследование потребительской корзины
Еще одна типичная для дата-сайентистов задача. В рамках рабочих процессов она помогает принимать правильные для бизнеса решения и корректировать работу разных отделов.
Описание проекта: берем данные из Dataset с покупками (например, Kaggle OpenML), загружаем через Pandas и очищаем. С помощью метода ассоциативных правил (Apriori и FP-Growth) находим часто встречающиеся товары, покупаемые вместе.
Строим модели для вычисления Support, Lift и Confidence для каждого набора товаров, чтобы определить сильные ассоциации между ними. Используем полученные данные для построения рекомендаций и анализа покупательских предпочтений. Результаты можно визуализировать с помощью Matplotlib или Seaborn для дальнейшего анализа.
Заключение
Пет-проекты используют для перехода из одной сферы в другую – например, из администрирования в DevOps или разработку, раскрытия творческого потенциала, тренировки навыков и закрепления знаний.
Для ряда специалистов проект может даже закрыть потребность в чем-либо, если никто пока этого не придумал. Так было с GitHub: работая над репозиторием по выходным и ночам, создатели сервиса снимали собственную “боль”, не зная, что в будущем их разработка привлечет миллионы пользователей.
Неважно, по какой причине вы выбираете проект, главное – чтобы он привлекал и вдохновлял вас, а нужное применение ему точно найдется 🙂
Если у вас возникли какие-либо вопросы, свяжитесь с нами удобным для вас способом – и мы обязательно ответим. Также ждем вас в нашем официальном Telegram-канале, а обсудить статью или просто пообщаться на любую тему с коллегами по цеху и сотрудниками Beget вы можете в нашем чате.