Как понять, что IT-продукт после релиза работает успешно: основные метрики
Привет! Это Атвинта. Рассказываем, как измерить реальный успех IT-продукта после его запуска. Мы собрали главные метрики, которые покажут, приносит ли проект деньги, окупаются ли вложения и довольны ли клиенты.

Что такое метрики в программировании и зачем они нужны
Метрики в IT — это измеримые показатели, которые помогают понять, насколько успешно работает продукт. Они фиксируют результат, дают команде обратную связь и становятся инструментом для принятия решений. Без метрик сложно сказать, есть ли у сервиса ценность и что работает хорошо.
Зачем нужен KPI продукта:
- помогают заметить проблему до того, как она стала критичной;
- показывают, работает ли гипотеза или требуется доработка;
- фиксируют прогресс — насколько улучшился продукт после изменений;
- помогают обосновать дальнейшие шаги — масштабировать, доработать или откатить релиз.
Показатели переводят цель в конкретные цифры и дают объективный способ понять, достигли вы ее или нет.
Какие бывают уровни метрик
Чтобы увидеть полную картину, метрики собирают на нескольких уровнях:
- Бизнес и финансы. Как система влияет на деньги — выручку, окупаемость и сокращение расходов. Например, сколько денег приносит клиент за все время (LTV), сколько стоит привлечь клиента (CAC) и когда окупится вложение.
- Продукт и поведение пользователей. Как люди пользуются системой — быстро находят информацию, возвращаются в приложение и проходят нужные шаги. К примеру: дошел до ключевого действия или вернулся через 7 дней.
- Надежность и производительность. Насколько стабильно и быстро работает система и нет ли ошибок.
- Качество релиза. Как быстро и безопасно команда выкатывает обновления. Например, частота релизов, среднее время до продакшна, доля неудачных релизов и баги на проде.
- Поддержка и клиентский опыт. Что говорят пользователи и насколько они довольны продуктом и обслуживанием. К примеру, оценка удовлетворенности, готовность рекомендовать и время до ответа поддержки.
Выбор показателей зависит от цели проекта. Если нужно сократить затраты — подойдут финансовые метрики, а если повысить вовлеченность — нужны продуктовые и поведенческие.
Корректная метрика:
- отвечает на конкретный вопрос;
- считается однозначно и без двойных трактовок;
- обновляется с нужной частотой;
- отображается на понятном дашборде;
- чувствительна к изменениям, но устойчива к выбросам;
- имеет контрметрику. Если ускорили поставку — проверяем качество, а если растет конверсия — смотрим на жалобы и возвраты.
Разберем пример: вы улучшили сценарий регистрации. Цель — повысить и ускорить активацию новых клиентов. Какие метрики отслеживаем:
- Целевая метрика — Activation rate — сколько пользователей дошли до первого ценного действия.
- Опережающие метрики — Time to First Value (сократилось ли время до пользы) и конверсия в регистрацию (не теряются ли пользователи).
- Запаздывающая метрика — Retention D7 — вернулись ли посетители через неделю.
- Контрметрики — ошибки и брошенные регистрации, а также обращения в поддержку.
Если Time to Value улучшилась, но Retention осталась прежней, значит, ускорение не помогает удержанию. Если Retention падает — возможно, посетители регистрируются быстрее, но не понимают, как дальше использовать приложение.В ERP для сервиса логистики и снабжения мы зафиксировали проблему: 93% заявок создавались в аварийном режиме — со сжатыми сроками и высокой нагрузкой на команду. Чтобы перевести процесс в плановый режим, задали цель — снижение доли таких заявок. Зафиксировали базовые значения, ввели статусы и автоматизировали логику маршрутизации в системе Totum. Это позволило отслеживать заявки на всех этапах и устранить «узкие места».После запуска платформа обеспечила прозрачность процессов, а количество срочных заявок снизилось до 20%. Пример показывает, как четкая цель и правильно выбранные показатели превращают изменения в понятный результат.

Основные метрики в IT: показатели успешности проекта
Чтобы объективно оценить, насколько успешно работает IT-продукт после релиза, одного показателя мало. Нужно смотреть на систему метрик, которые охватывают факторы успеха проекта, потому что только в связке они дают полную картину. Собрали ключевые блоки метрик, пояснения, зачем они нужны и как их правильно считать.
Бизнес и рост
Этот блок отвечает на главный вопрос заказчика: окупается ли продукт и приносит ли он ценность бизнесу.
LTV — пожизненная ценность клиента
Lifetime Value фиксирует, сколько маржинальной прибыли приносит один клиент за весь срок жизни. Это основа юнит-экономики, которая показывает, насколько ценно привлекать и удерживать клиентов.Для подписочных продуктов формула выглядит так:LTV = (ARPA × CM%) / Churn Rate, где:
- ARPA (Average Revenue per Account) — средний доход на аккаунт в месяц;
- CM% (Contribution Margin) — маржа, выручка минус переменные издержки обслуживания — хостинг, комиссии, поддержка;
- Churn rate — месячный отток клиентов.
В транзакционных моделях (e-commerce) LTV считается иначе — через средний чек (AOV), частоту покупок и маржу:LTV = AOV × среднее число заказов × CM%.
CAC — стоимость привлечения клиента
Customer Acquisition Cost — сколько в среднем стоит привлечение одного клиента. Формула: CAC = затраты на маркетинг и продажи / число новых клиентов за период.
ARPU и ARPPU — доход на пользователя или платящего клиента
Average Revenue per User — доход на одного активного пользователя.Average Revenue per Paying User — только на тех, кто платит.Формулы:
- ARPU = общий доход за период / количество активных пользователей за период;
- ARPPU = общий доход за период / количество платящих пользователей за период.
Если ARPU растет — возможно, вы успешно продаете дополнительные функции или повышаете цены. Если падает — стоит проверить структуру пакетов и ценовую политику.
Payback — срок окупаемости клиента
Метрика показывает, сколько месяцев нужно, чтобы вернуть вложения в одного клиента. Чем быстрее Payback, тем проще масштабировать продукт.Формулы:
- Для B2C — Payback = CAC / (ARPA × CM%);
- Для B2B — Payback = CAC / (ARPPU × CM%).
Если маржа отрицательная (вы тратите больше на обслуживание клиента, чем зарабатываете), payback не имеет смысла — сначала нужно пересчитать юнит-экономику.
MRR или ARR — повторная выручка
Monthly Recurring Revenue — это ежемесячная повторяющаяся выручка. Она показывает, сколько вы зарабатываете на подписках и регулярных платежах. Annual Recurring Revenue — годовая версия той же метрики.Формула: ARR = MRR × 12.
Churn — отток клиентов или выручки
Churn — это скорость потери клиентской базы. Бывает двух видов:
- Logo churn — доля ушедших клиентов. Формула: (ушедшие клиенты / все клиенты на начало месяца) × 100.
- Revenue churn — доля потерянной выручки. Формула: (потерянный MRR / MRR на начало месяца) × 100.
В корпоративном lean-сервисе мы внедрили систему расчета экономического эффекта инициатив. Благодаря прозрачной аналитике клиент получил подтвержденную эффективность на 20 млрд рублей, охват 34 предприятий и 1 700 пользователей, а собственная разработка решает больше задач по сравнению с зарубежным продуктом.

Продукт и поведение пользователей
Метрики показывают, как именно люди используют продукт, на каких этапах теряются и что можно улучшить.
Activation rate — доля активации
Метрика показывает, какой процент новых пользователей дошел до первого полезного действия.Формула: Activation rate = (пользователи, достигшие первой активации / новые регистрации) × 100.Если из 100 зарегистрировавшихся только 40 начали использовать сервис по назначению — нужно дорабатывать онбординг или сценарий первого запуска.
Time to Value — время до ценности
Отслеживает, сколько времени в среднем проходит от регистрации до первого полезного действия. Чем меньше TTV, тем выше шанс, что пользователь останется.Например, пользователь зарегистрировался в таск-трекере и создал первую задачу через 15 минут — это и есть его Time to Value.
Retention — удержание
Метрика показывает, сколько пользователей вернулось через 1, 7, 30 или 90 дней после первого визита.Формула: Retention = (пользователи на день Х / пользователи в первый день) × 100.Связь с оттоком: Churn% = 100% − Retention%.Если Retention D7 = 20%, значит только 20 из 100 пользователей вернулись через неделю — выясните, почему остальные ушли.
DAU/MAU и stickiness — липкость
Липкость продукта измеряет, как часто аудитория им пользуется.Формула: Stickiness = DAU / MAU.Если значение ближе к 1 — сервис используется ежедневно.
Feature adoption — принятие функции
Показатель измеряет, насколько активно функционал используется в реальности.Формула: Adoption rate = (количество пользователей, использовавших функцию / активные пользователи) × 100.Если adoption <10%, стоит пересмотреть реализацию, расположение или подачу новой возможности.
Engagement depth — глубина вовлечения
Метрика показывает, как активно пользователь работает в продукте: сколько создает задач, отправляет сообщений или загружает документов. Обычно используют медиану действий в неделю или месяц, чтобы отделить активных пользователей от однодневных.
Completion rate — завершение сценария
Данные помогают понять, сколько пользователей завершили ключевой процесс: оплатили заказ, прошли курс или отправили заявку.
Формула: Completion rate = (завершившие / пользователи, достигшие первого шага сценария) × 100.Если на старте 100 человек, а до финиша доходит 30 — ищем и устраняем барьеры в сценарии.
В EdTech-платформе СМИТАП мы реализовали личные кабинеты, элементы геймификации и визуальные дашборды. Это позволило отследить путь ученика от регистрации до первого домашнего задания и повысить ежедневную активность до 8 000 пользователей. Завершение курсов стало управляемым за счет наглядных подсказок, удобного интерфейса и аналитики прогресса.
Надежность и производительность
Метрики тестирования помогают контролировать качество технической стороны продукта.
Availability — доступность
Это доля времени, когда продукт был доступен для пользователей. Метрика рассчитывается как:Availability = (доступное время / общее время) × 100.
Latency p95 и p99 — задержка отклика
Среднее время отклика может скрывать реальные проблемы: один ждал 3 секунды, а второй — 2 минуты. Чтобы понять, как чувствует себя большинство пользователей, используют p95 и p99 — значения, в которые укладываются 95% и 99% запросов.Например, p95 = 500 мс означает, что 95% пользователей получили ответ быстрее, чем за полсекунды.
Crash-free — стабильность ПО
Стабильность приложений. Метрика отвечает на вопрос: сколько пользователей или сессий не столкнулись с ошибками. Формула: Crash-free = стабильные сессии / все сессии.Например, если из 10 000 сессий только 100 закончились сбоем, crash-free = 0,99.
MTBF, MTTD или MTTR — надежность и реакция на проблемы
Три ключевых метрики, характеризующие техническую зрелость:
- Mean Time Between Failures — среднее время между сбоями. Чем больше — тем стабильнее система.
- Mean Time To Detect — сколько времени уходит на то, чтобы заметить сбой.
- Mean Time To Recovery — сколько времени требуется на восстановление после сбоя.
Чем быстрее команда замечает и устраняет сбои, тем меньше негативный эффект для бизнеса и пользователей.В интерфейсе медицинской установки «Плазморан» мы внедрили механизмы самотестирования, защиту от ошибочных действий и крупные элементы управления, адаптированные под полевые условия и работу в перчатках. Такой подход обеспечил устойчивость сценариев даже в стрессовой среде, снизил количество ложных нажатий и повысил надежность интерфейса.

Качество изменений
Метрики качества — это то насколько оперативно, аккуратно и предсказуемо команда выпускает изменения.
Deployment frequency — частота релизов
Метрика показывает, как часто команда выкатывает изменения в продакшн. Чем чаще релизы — тем быстрее продукт откликается на запросы пользователей и бизнеса.Также необходимо соблюдать качество: при высокой частоте релизов нужно быть уверенными в безопасности изменений.
Lead time for changes — время до продакшна
Какое количество времени в среднем проходит от первого коммита до момента, когда функционал или багфикс доходит до продакшна. Если изменения застревают на этапе тестирования или на согласованиях, это тормозит процессы и развитие продукта.
Change failure rate — доля неудачных релизов
Метрика показывает, сколько запусков вызывают инциденты или баги. Чем ниже CFR, тем безопаснее процессы релизов.Формула: CFR = (релизы с инцидентами / общее число релизов) × 100.
Defect escape rate — утечка дефектов в продакшн
Какая доля багов обнаруживается уже после релиза, то есть проскочила мимо тестирования. Формула: Escape Rate = баги на проде / (баги на тесте + баги на проде).Чем выше показатель, тем хуже работает тестовая среда. Метрика позволяет отследить эффективность QA.
Test coverage — покрытие тестами
QA-метрика показывает, какая доля кода покрыта автотестами. Это не гарантия отсутствия багов, но страховка от регрессий и способ безопасно ускорять релизы.
Bug backlog age — возраст багов
Медианное время, которое баги проводят в открытом статусе. Если дефекты висят неделями или месяцами, это сигнал — ошибки плохо приоритизируются либо команда не успевает их закрывать.Например, средний возраст багов в багтрекере — 40 дней. Это может говорить об отложенных технических долгах или слабом фокусе на качестве.
Клиентский опыт и поддержка
Метрики этого блока помогают понять, как пользователи воспринимают продукт и насколько качественно работает поддержка.
CSAT — оценка удовлетворенности
Customer Satisfaction Score показывает, насколько пользователи довольны конкретным взаимодействием: работой поддержки, интерфейсом, процессом оформления заказа и так далее. Метод: после ключевого действия пользователю предлагают оценить опыт по шкале — от 1 до 5 или от 1 до 10.Формула: CSAT = (сумма ответов с высокой оценкой / количество ответов) × 100.
NPS — индекс лояльности
Net Promoter Score оценивает готовность пользователя рекомендовать продукт другим. Вопрос: «С какой вероятностью вы порекомендуете сервис друзьям или коллегам?» — шкала от 0 до 10. Ответы делятся на 3 группы:
- Промоутеры (9-10) — лояльные пользователи, скорее всего, порекомендуют сервис.
- Нейтралы (7-8) — довольны, но не настолько, чтобы делиться опытом.
- Критики (0-6) — скорее всего, будут отговаривать от сотрудничества или использования продукта.
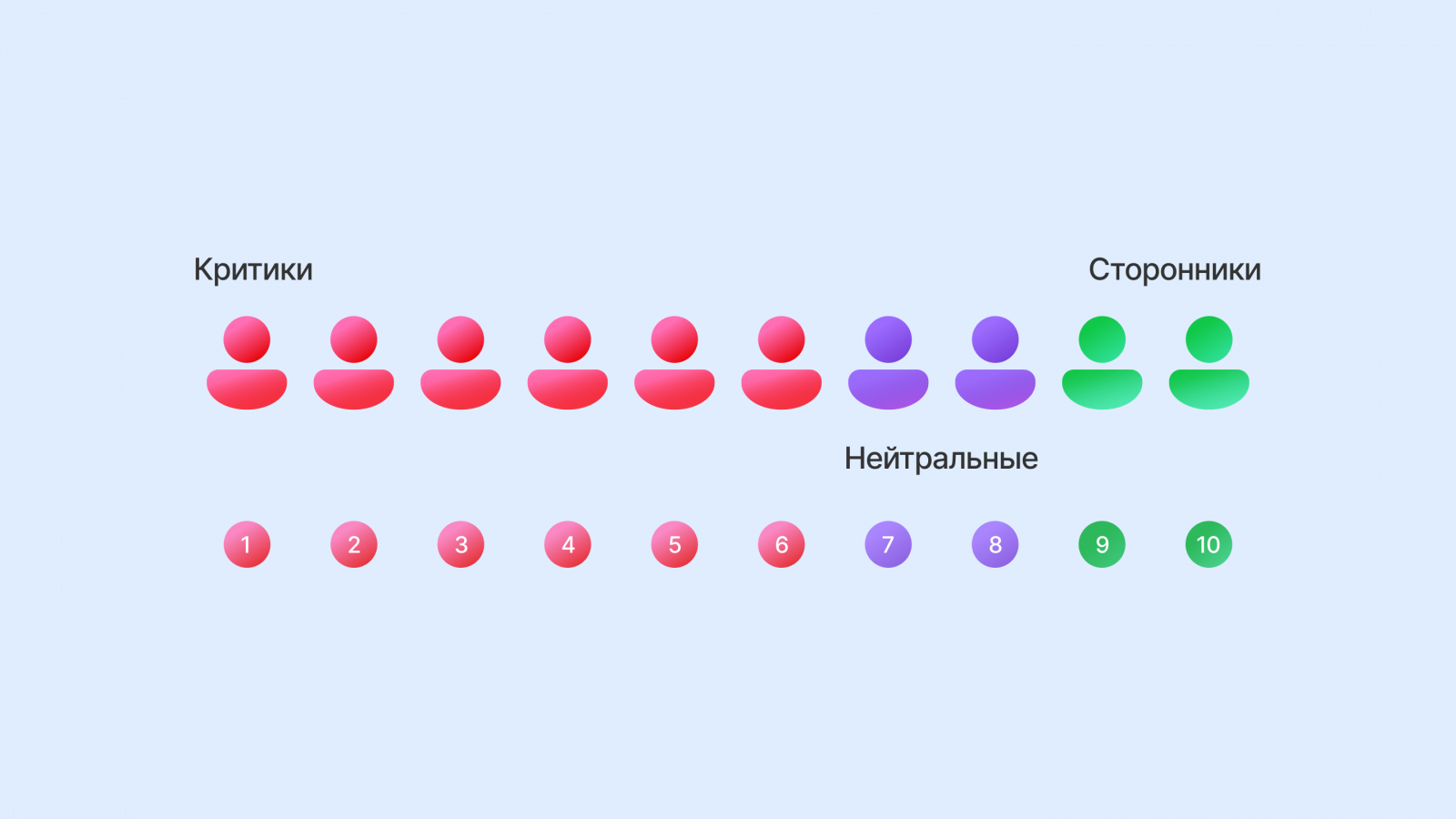
Формула: NPS = % промоутеров − % критиков.
CES — усилие пользователя
Customer Effort Score показывает, насколько просто пользователю было выполнить нужное действие: найти информацию, получить помощь или пройти онбординг. Чем меньше усилий — тем выше шанс, что человек вернется.Пример вопроса: «Насколько легко было решить ваш вопрос?» — шкала от 1 (сложно) до 5 (очень просто).
FRT или ART — время до первого ответа или до решения
- First Response Time — среднее время, за которое поддержка впервые отвечает на запрос клиента.
- Average Resolution Time — среднее время, за которое запрос полностью закрывается.
Чем быстрее поддержка реагирует и решает проблему, тем выше доверие и лояльность пользователей.
Contact rate — частота обращений
Показывает, как часто пользователи обращаются в поддержку.Формула: Contact Rate = (число обращений / количество активных пользователей за период) × 100.Если метрика растет, это может указывать на:
- проблемы в приложении;
- недостаточную документацию;
- сложные интерфейсы или бизнес-процессы.
В модуле планировщика интерьеров для ГК ФСК мы реализовали сохранение и редактирование проектов. Пользователь мог спроектировать интерьер и вернуться к изменениям позже. Это повысило вовлеченность аудитории, снизило нагрузку на отдел продаж и позволило компании анализировать предпочтения клиентов — от популярных планировок до часто выбираемой мебели.
Как выбрать ключевые показатели эффективности
Метрики помогают команде и бизнесу принимать решения: масштабировать продукт, дорабатывать слабые возможности и останавливать то, что не работает. Чтобы получить пользу и не запутаться в цифрах, нужно осознанно подбирать показатели.
1. Сформулируйте цель релиза
Ответьте на простой вопрос: что именно должно измениться после релиза? Это может быть поведение пользователя, чтобы он быстрее находил информацию, повышение конверсии или снижение нагрузки на поддержку.Корректная цель звучит как конкретный результат:
- «Сократить среднее время до первого действия на 20%»;
- «Увеличить конверсию до 4%»;
- «Снизить количество обращений в поддержку по сценарию X на 30%».
2. Переведите цель в измеримую метрику
Далее нужно понять, как вы увидите, что цель достигнута. Если цель — упростить регистрацию, метрикой может быть:
- Time to value (TTV) — сколько времени проходит от первого входа до первого полезного действия;
- Completion rate — процент тех, кто завершил регистрацию;
- CSAT — средняя оценка удобства процесса.
Задайте контрметрику — она покажет, нет ли обратного эффекта. Например, если вы упростили регистрацию, а Retention D7 (удержание на 7-й день) просел — значит, пришла не та аудитория, и изменения требуют доработки.
3. Добавьте 2-3 причинные метрики
Целевая метрика показывает итог, а причинные — помогают понять, почему результат получен.Если вы хотите повысить выручку, причинными метриками могут быть:
- ARPU — средний доход на пользователя;
- Conversion Rate на отдельных этапах;
- Churn rate — отток пользователей после первого действия.
Причинные метрики помогают найти узкие места или точки роста, даже если итоговая цель пока не достигнута.
4. Проверьте доступность данных
Прежде чем включать метрику в план, убедитесь, что она может быть рассчитана. Ответьте на следующие вопросы:
- Откуда можно получить данные?
- Какие события нужно отслеживать и где их собирать?
- Есть ли нужные отчеты в BI-инструментах?
Если данных нет — подумайте, как их внедрить. Например, настроить события и подключить мониторинг.
5. Установите базу, целевые значения и границы
Для каждой выбранной метрики задайте три ключевые точки:
- Базовое значение — как метрика выглядит до релиза.
- Целевое значение — на что вы ориентируетесь.
- Границы — допустимый диапазон, что считать улучшением, нормой и ухудшением.
Пример: Time to Value = 2,5 дня. Ваша цель — снизить до 36 часов. Граница — не более двух дней. Если остается выше — пересматриваем подход или делаем откат.Когда заранее известно, что делать при отклонении, время на реакцию сокращается, а управляемость проекта растет.
6. Разделяйте данные по сегментам
Агрегированные показатели маскируют реальные проблемы. Чтобы увидеть слабые места и точки роста, анализируйте метрики по отдельным группам пользователей:
- платформам;
- типам пользователей — новые и вернувшиеся;
- каналам привлечения;
- регионам.
Сегментация помогает точнее понимать поведение разных групп, выдвигать гипотезы и принимать обоснованные продуктовые решения.
7. Сформируйте набор метрик на релиз
Итогом работы становится управляемый набор метрик:
- одна целевая метрика — итог;
- две-три причинные — что влияет;
- одна контрметрика — что может пострадать.
Набор метрик позволит отслеживать эффект от изменений, управлять рисками и принимать решения о масштабировании, доработке или откате.
Как оценить результаты метрик
Сами по себе цифры ничего не решают. Чтобы понять, успешен ли релиз, метрики нужно интерпретировать в контексте целей и других данных. Это позволяет принимать обоснованные решения: улучшить, масштабировать или остановить.Данные становятся полезными только тогда, когда вы понимаете:
- что именно изменилось после релиза;
- насколько результат соответствует ожиданиям;
- как это влияет на пользователей и бизнес;
- что стоит делать дальше — масштабировать, переделывать или откатывать.
Для каждой ситуации формулируйте следующий шаг. Например:
- Пользователи теряются на одном шаге — упростите форму и добавьте подсказки.
- Падает удержание — пересмотрите онбординг и добавьте триггеры для возвращения.
- Увеличились ошибки — приостановите продвижение и исправьте баги.
Как оценить эффективность продукта
Эффективность IT-продукта невозможно оценить без метрик. Чтобы они работали на результат, их нужно подбирать исходя из целей проекта. Правильно выбранные показатели показывают, что действительно изменилось: в поведении пользователя, выручке или стабильности системы.Фиксируйте значения до релиза, задавайте пороги успеха и сценарии на отклонение. Анализируйте результаты по сегментам и в динамике — это поможет принять верное решение.
FAQ по метрикам после релиза
Зачем вообще измерять KPI IT-проектов после релиза, если «и так видно, что работает»?
Метрики показывают масштаб и причину изменений: где теряются пользователи, как сдвинулась выручка и выросла ли нагрузка. Без цифр невозможно обоснованно решить, что делать дальше.
Какой минимальный набор метрик взять на один релиз?
Одна целевая метрика (главный эффект), две-три причинные (что влияет на результат) и одна контрметрика (что может пострадать: стабильность, жалобы и ошибки).
Как часто смотреть метрики качества продукта и кто за это отвечает?
В первую неделю — ежедневно, затем по спринтам команды. За мониторинг отвечают продакт и аналитик, за реакцию на технические риски — DevOps. Набор метрик пересматривают минимум раз в квартал и после значимых релизов.
Что делать, если метрики противоречат друг другу?
Изучите данные по сегментам аудитории, проверьте их качество и приоритезируйте по бизнес-целям. Например, сейчас важнее скорость роста или стабильность.
Когда масштабировать, а когда дорабатывать или откатывать?
Масштабировать — когда эффект стабилен в нескольких сегментах и контрметрики не просели. Дорабатывать — если рост локальный или нестабильный. Откатывать — если целевая метрика просела и растут жалобы, а техриски увеличились.