Способы и методы машинного обучения

В 2023 году трудно представить новостную ленту без понятия «машинное обучение». Предполагается, что рынок этой технологии к 2030 году достигнет 225 млрд долларов. Для сравнения — на 2023-й прогнозировался рост до 26 млрд.
То есть Machine learning с нами надолго. Технология будет и дальше внедряться в сферы человеческой жизни: прогнозировать, классифицировать, генерировать объекты. Поэтому важно не отставать и понимать, что такое машинное обучение, как ML появилось, какие методы и способы использует. Об этом расскажем в нашей статье.
Суть машинного обучения
Machine learning (машинное обучение) — направление развития искусственного интеллекта, которое имитирует процессы мышления человека. Здесь не задаётся чёткая последовательность действий, которую, к примеру, выполняет программное обеспечение, а происходит постоянное «размышление», как бы это делал мозг.
Машинное обучение — это прогнозирование на основе огромных объёмов данных, в которых алгоритмы находят закономерности. Понятие связано с нейросетями, которые входят в один из типов ML и работают через глубинное обучение.
Алгоритмы машинного обучения применяются для создания сервисов, которые:
- Рекомендуют продукты, услуги и контент, в том числе на основе действий пользователя. К примеру, так работают онлайн-кинотеатры, которые предлагают фильмы и сериалы, исходя из просмотренных.
- Прогнозируют будущее: возможные тренды, объёмы продаж, заболевания клиентов медклиник по их анамнезу, события и так далее. Модели машинного обучения определяют кредитный рейтинг в банках и предугадывают поведение клиентов, которые, возможно, не смогут выплачивать займ.
- Распознают объекты на изображениях и видео, понимают речь и анализируют текст. Это ускоряет рутинные процессы, упрощает работу человека и даже обеспечивает безопасность. Например, определение номеров автомобилей по камерам видеонаблюдения — дополнительный контроль.
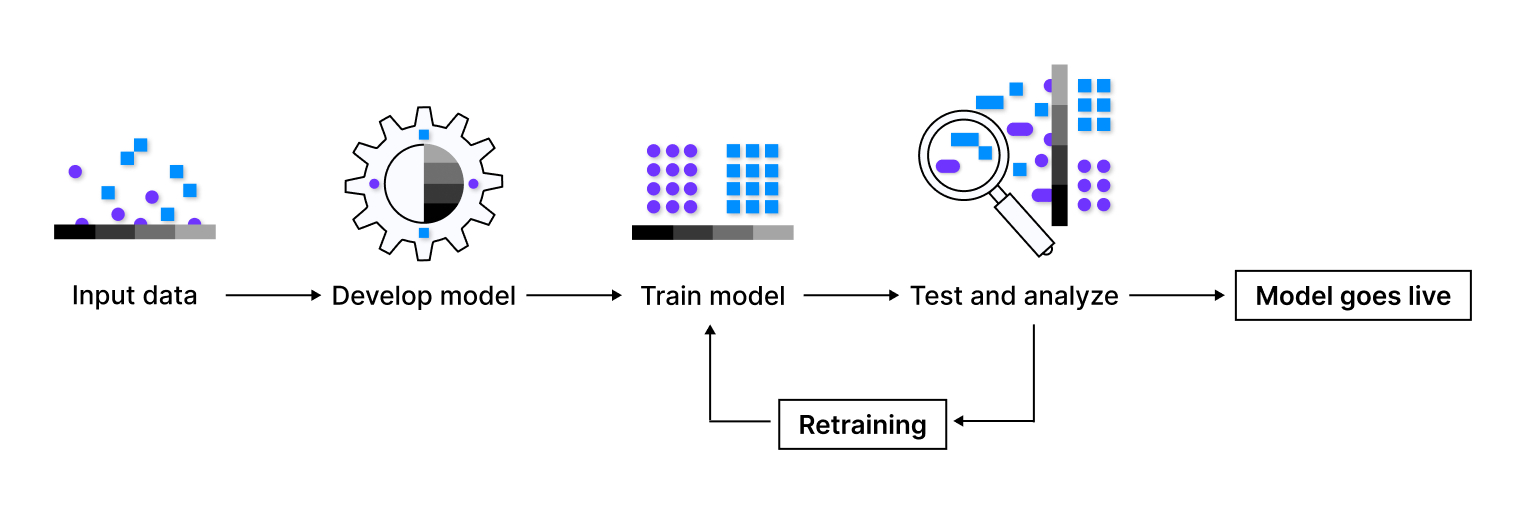
Как работает машинное обучение
- Определение критериев для отбора и сбор данных. Это огромные объёмы информации.
- Подготовка сведений — разграничение их метками, которые важны для распознавания алгоритмами ML нужных элементов. Сейчас разметка проводится специалистами и реже автоматизируется, поэтому процесс этот долгий.
- Проверка данных и поиск закономерностей. Здесь находят ошибки, чтобы их исправить и сделать следующий этап наиболее точным.
- Выбор модели и начало обучения. Алгоритм обрабатывает данные и выдаёт результаты.
- Получение и оценка работы алгоритмов. На этом этапе исправляются ошибки, меняются алгоритмы для дальнейшей работы
История Machine Learning
XX век
Первые примеры использования машинного обучения встречаются в середине прошлого века. Скопировать нейрон впервые смогли учёные Уолтер Питтс и
Уоррен Мак-Каллок ещё в 1943 году. Далее известен секретный проект армии США 1946 года для программного создания таблиц, которые улучшали меткость стрельбы.
Временем расцвета машин лернинг стали 50-е, когда появилась Checkers-playing — программа Джозефа Вейцбаума, Фрэнка Розенблатта и Артура Сэмюэля, которая умела играть в шашки.
В этот же период стала известной модель нейросети (Mark I Perceptron), имитировавшая работу мозга человека, изобрёл её Розенблатт. В конце 50-х появилась SNARC — нейронка, которая выполняла комплексные задачи. Её создателем выступил американец Марвин Минский.
Само понятие «машинное обучение» обозначилось только в 1959 году, его озвучили на конференции в колледже Дартмута (США).
Прототип первого виртуального ассистента запустили в 60-х. Это была система ELIZA, которая воспроизводила как бы диалог с психотерапевтом. В это же десятилетие изобрели алгоритм, который умел распознавать и классифицировать данные. А в конце десятилетия Бернард Уидроу и Себастьян Трун создали алгоритм обратного распространения ошибки — это был большой шаг в улучшении работы нейронок.
В 80-е учёные снова использвали технологии для игры. На этот раз — в шахматы. Молодые учёные из университета Карнеги-Меллон придумали систему ChipTest. На основе этой разработки в конце 90-х появился суперкомпьютер Deep Blue, который обыграл знаменитого шахматиста Гарри Каспарова. Это было одно из первых противостояний машины и человека, которое показало силу машинного обучения в прогнозировании действий роботом.
XXI век
В наше время выросла мощность компьютеров и увеличились объёмы данных, что подтолкнуло ML к новой стадии развитии. В 2000-х появилось понятие «глубокое обучение». Начало 2010-х стало эпохой открытия новых проектов по нейросетям, в частности — в гонку вступает Google, и уже в 2012-м — алгоритм от команды Google X Lab научился узнавать котиков на картинках и в видео. Появился также Google Prediction API — сервис для аналитики и работы Machine learning.
Не отставали гиганты Amazon, Microsoft, Facebook*, у которых появились свои платформы, где работали методы машинного обучения. А технология компании Марка Цукерберга DeepFace научилась распознавать лица с высокой точностью.
В 2020-х роль машинного обучения растёт. Технологии уже работают в сферах финансов, здравоохранения, в промышленности, используются в транспорте и будут всё дальше срастаться с повседневной жизнью людей.
Способы машинного обучения
Методы Machine Learning
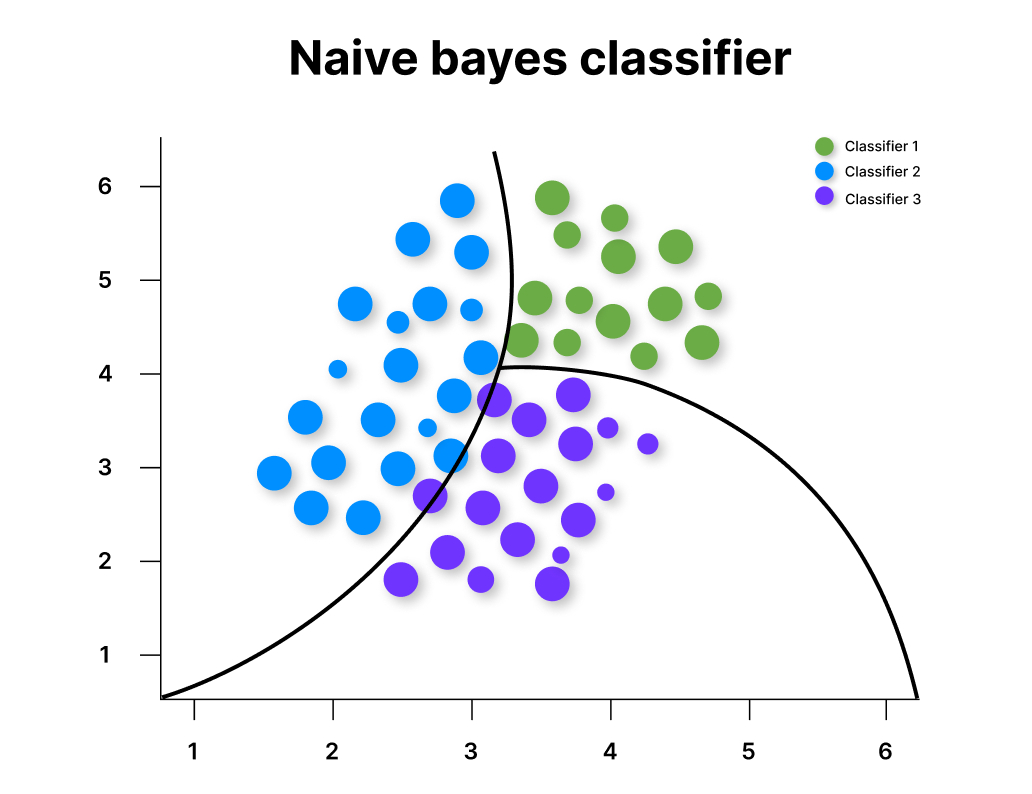
Байесовский классификатор
Метод получил название от из теоремы Байеса. В основе — определение класса объекта по его признакам. Считается одним из самых простых и используется для рубрикаторов, распознавания объектов на изображениях, определении спамных писем.
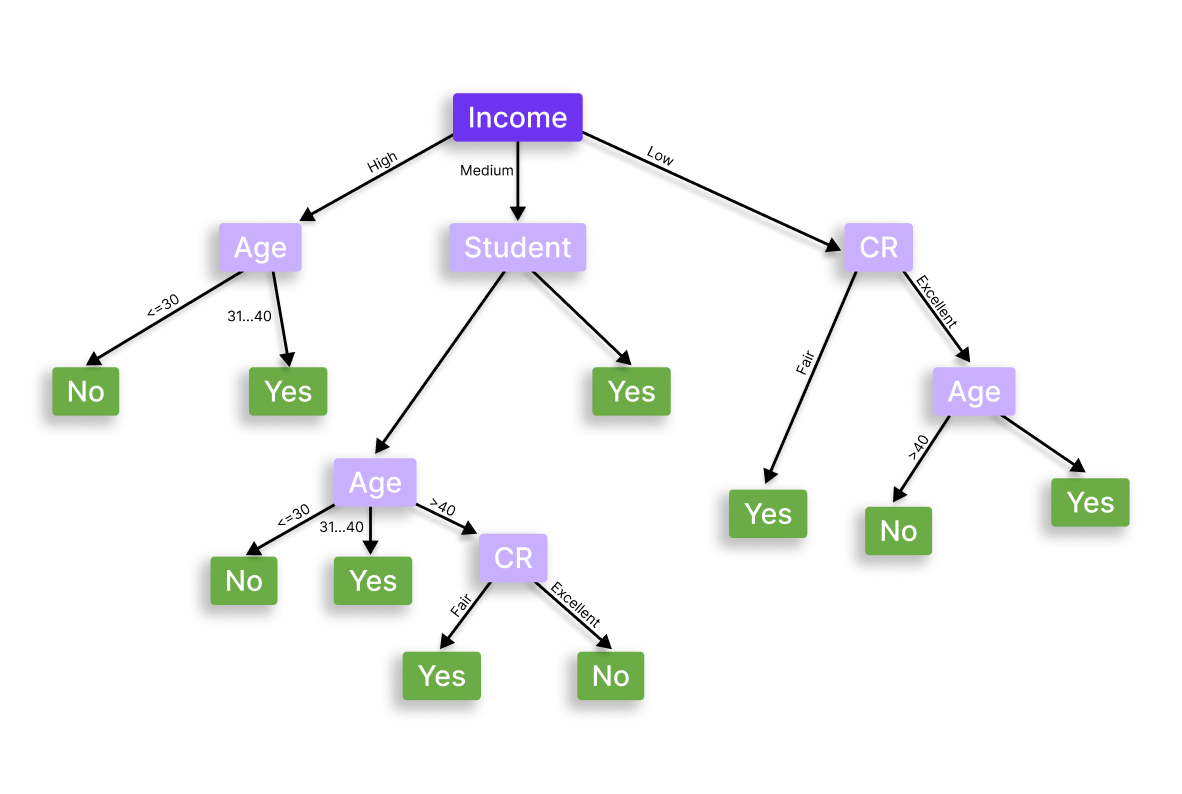
Деревья принятия решений
В этом методе модель выявляет взаимосвязь одних событий и объектов с другими и последствия их взаимодействия. Визуально эту схему можно изобразить в виде «разветвлений дерева», где представлены разные варианты развития событий в зависимости от выбора. Это похоже на тесты-алгоритмы с ответами «да» или «нет», которые приводит к результату. Плюс метода — в его системности, но применяется он не везде.
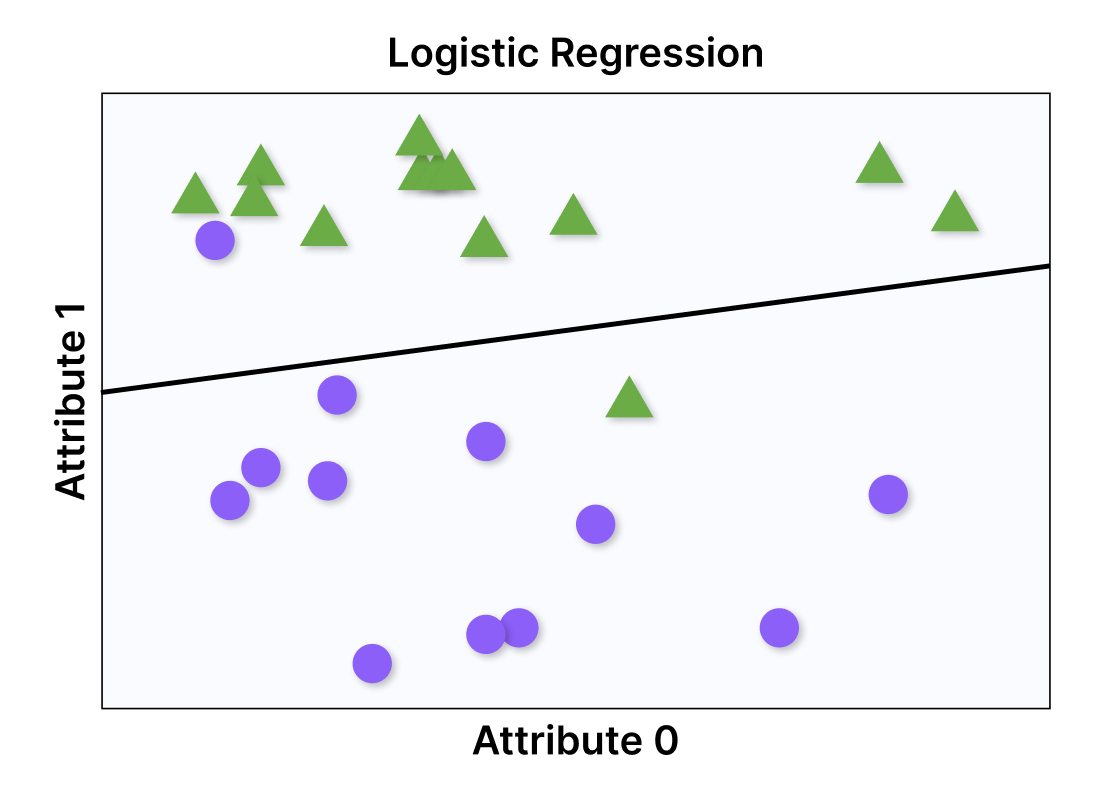
Логистическая регрессия
Статистический метод, который стал использоваться в машинном обучении. Логистическая функция определяет зависимость между одной или несколькими переменными. Объекты разделяются по двум классам по определённым значениям в диапазоне 0-1.
Определение кредитного потенциала, прогнозирование успешности продаж, рекламных кампания и другие верноятностные события выявляют через метод логистической регрессии.
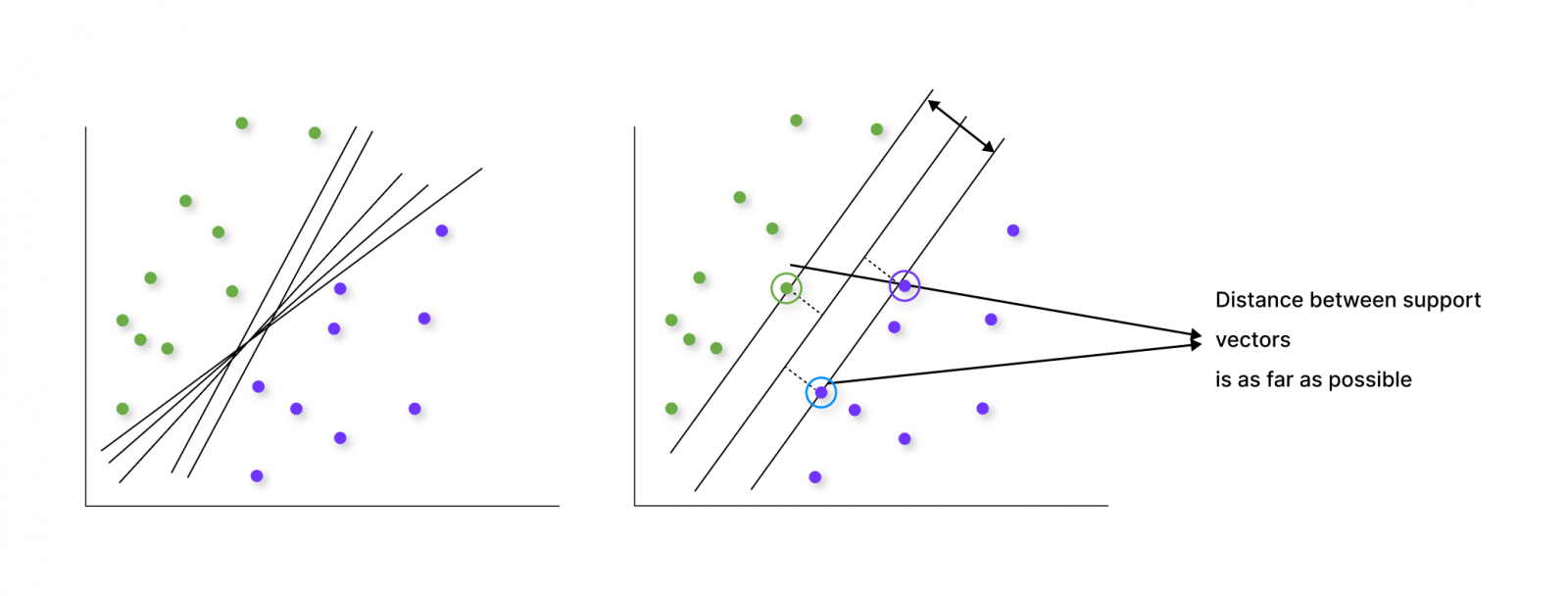
Опорные векторы
Включает несколько алгоритмов, которые классифицируют объекты в гиперплоскости, разделяемую векторами. И задача системы — найти наиболее правильное расположение линии в плоскости для лучшей классификации.
Этот метод решает достаточно сложные задачи и может определить: мужчина или женщина на фото, какую рекламу показывать на сайте пользователю и так далее.
Линейная регрессия
Смысл метода в том, чтобы соотнести одну переменную N с другой переменной или несколькими. Условно на плоскости есть точки данных, для которых нужно найти наиболее подходящую линию, которая их соединит.
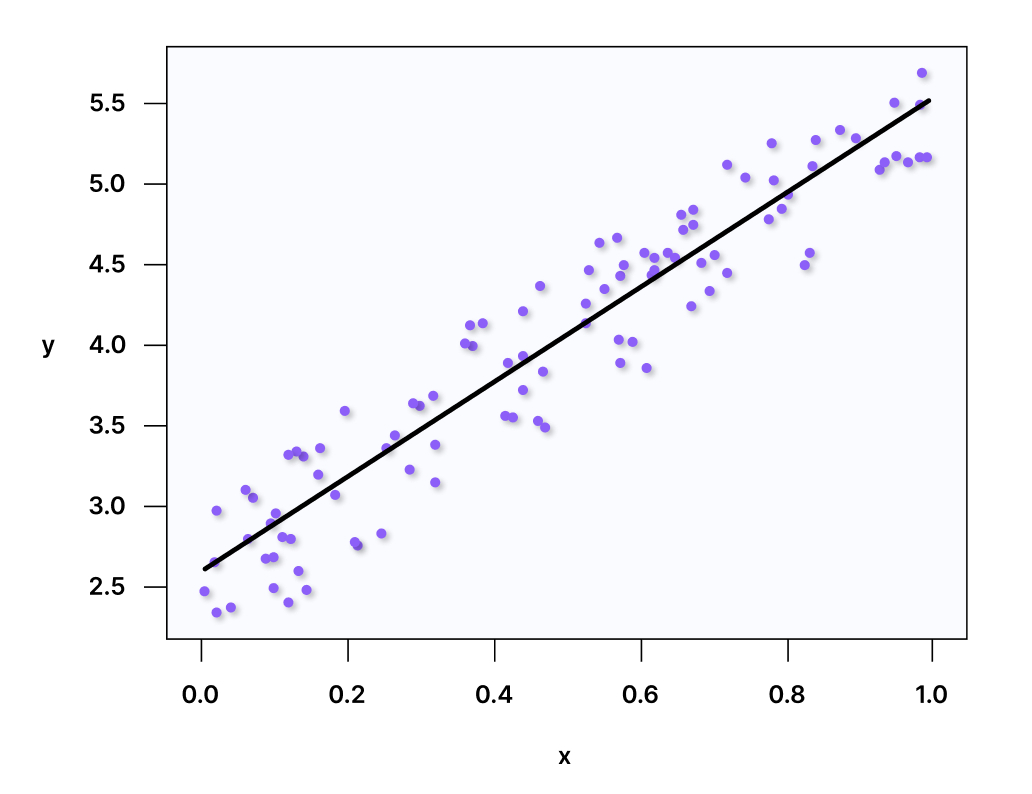
Такой алгоритм легко предсказывает тренды, определяет, какой информации не хватает в простых линейных рядах. Например, что нужно добавить в последовательности 10, 20, 30, 40, 50…
Ассамблейные методы
Набор методов, где происходит генерация различных классификаторов и разделение данных по принципу усреднения или голосования. Такой подход уменьшает вероятность ошибок.
К ассамблеям относят:
- Бэггинг — базовые модели обучаются параллельно со сбором усложнённых классификаторов.
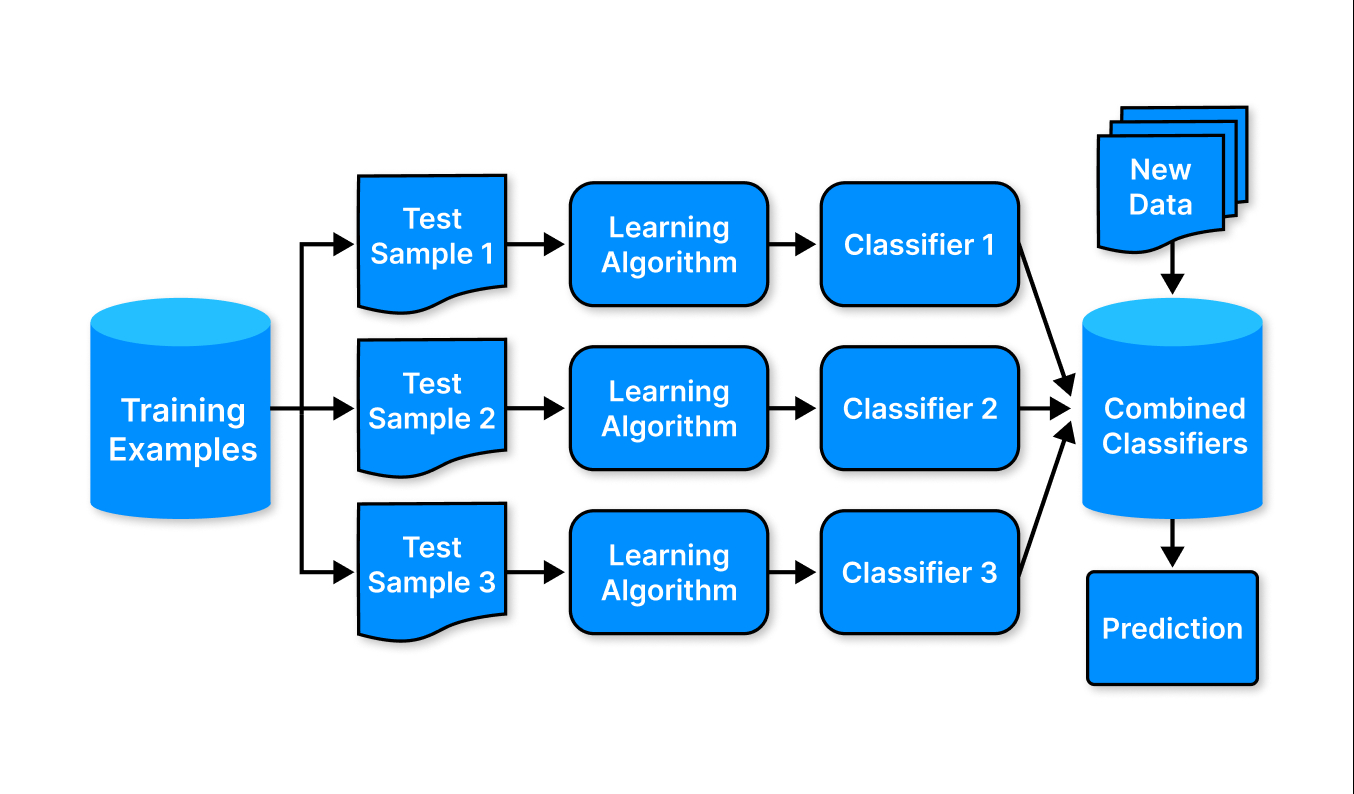
- Бустинг — сильные модели создаются при помощи слабых. Происходит обучение на предыдущих классификаторах, чтобы улучшить и исправить ошибки для следующих.
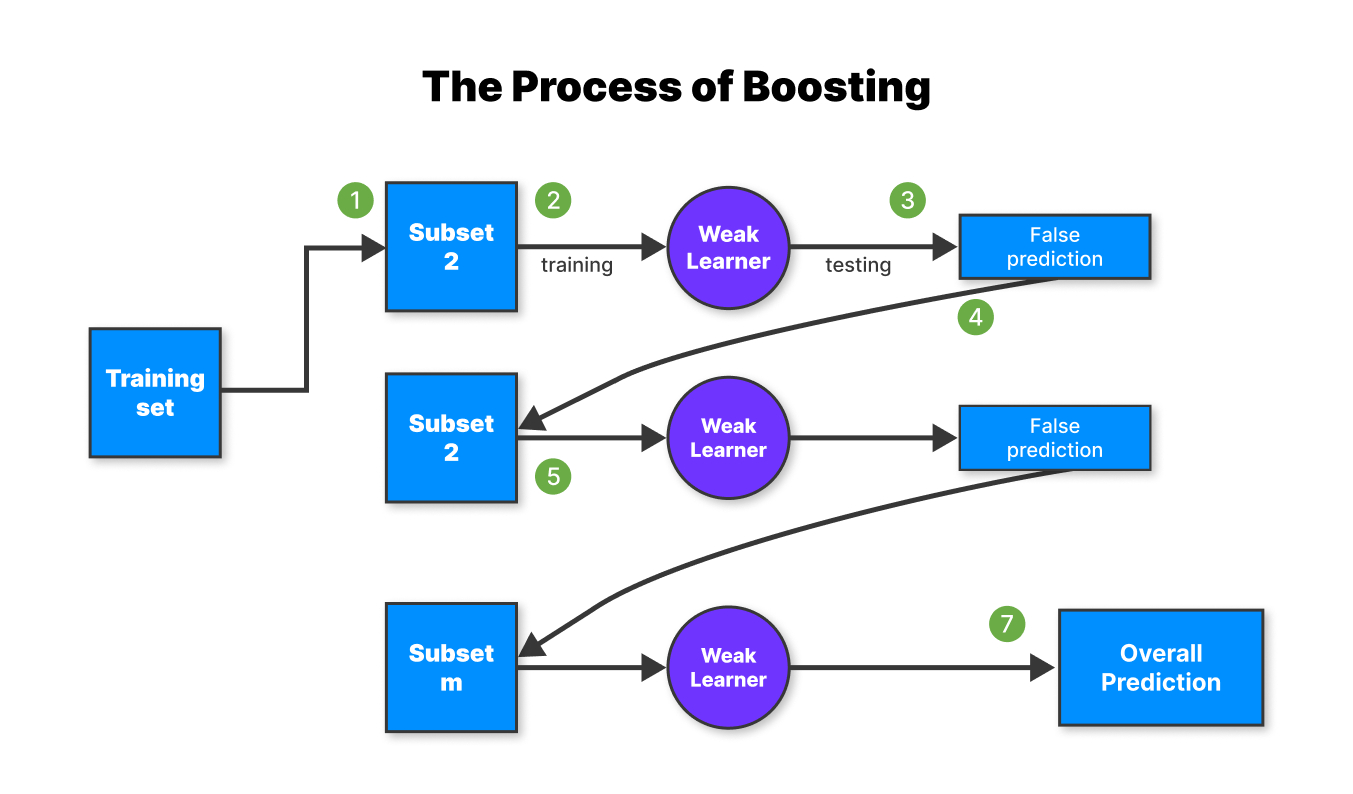
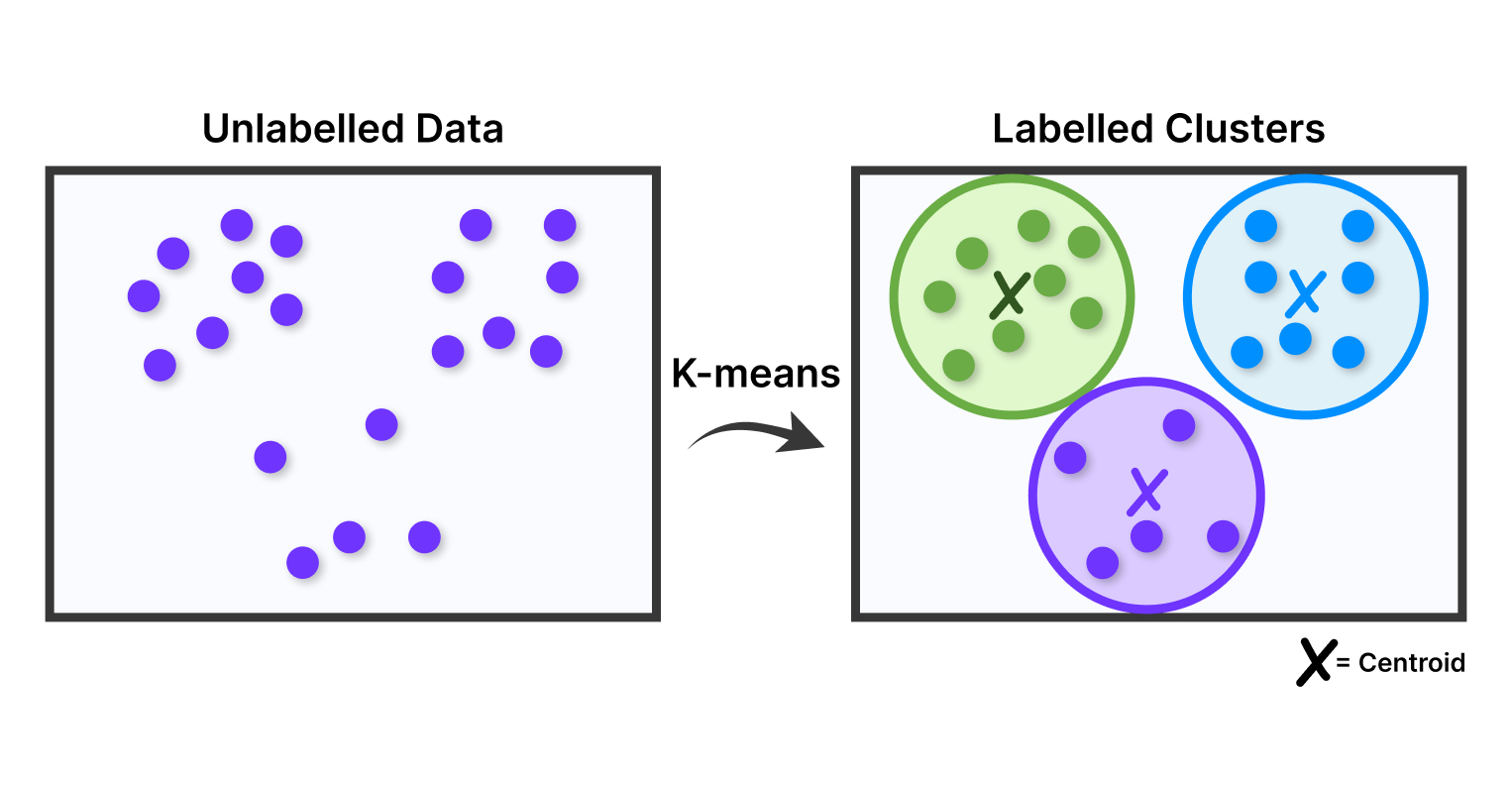
Кластеризация к-средних
Один из методов кластеризации в машинном обучении. В работе алгоритма используется некоторое рандомное число кластеров K. Для каждого свой центр (точка), от которой считается расстояние до каждой точки данных в группах. Потом центр каждого кластера перечисляется, векторы снова разбивают точки данных на кластеры. Это происходит до того, как изменений больше не происходит.
Кластеризация полезна для биологических исследований, в IT-технологиях и социологии.
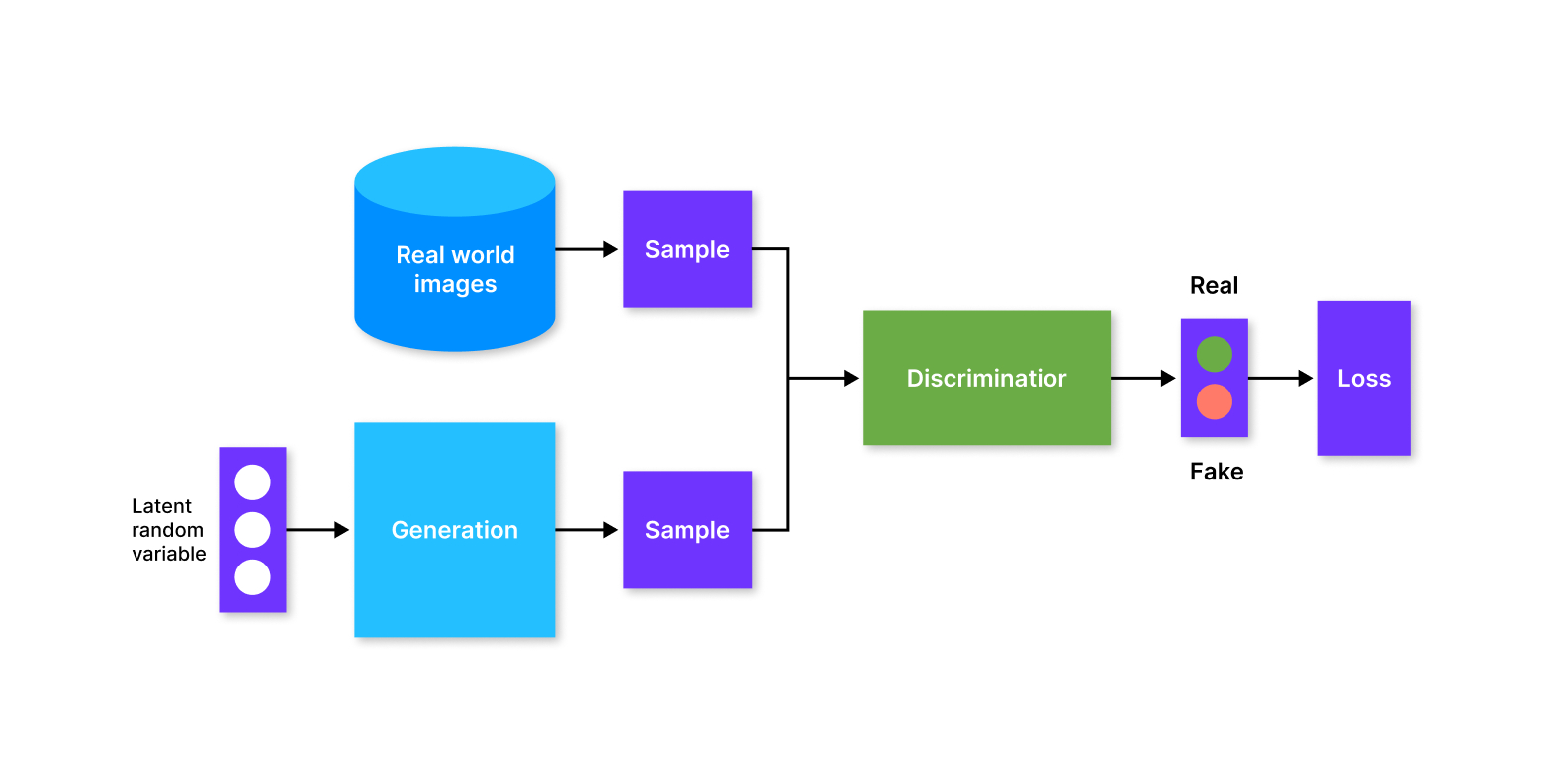
Состязательно-генеративное обучение
Этот метод основан на работе нейросетей, которые как бы вступают в борьбу друг с другом (так появилось название). Внутри алгоритмы дискриминатора и генератора. Первый пытается классифицировать входящие данные и соотносит их с категориями. Второй, наоборот, стремится выбрать образы, которые подходят к категориям. То есть генератор создаёт объекты, а дискриминатор их проверяет на подлинность. Именно такой алгоритм умеет создавать изображения несуществующих людей, которые похожи на реальных.
Резюме
Машинное обучение — вид искусственного интеллекта и имитация деятельности человеческого мозга. Первые алгоритмы Machine learning появились в 40-50-х годах прошлого века, но значительного роста достигли в XXI веке и используются сейчас во многих сферах человеческой жизни.
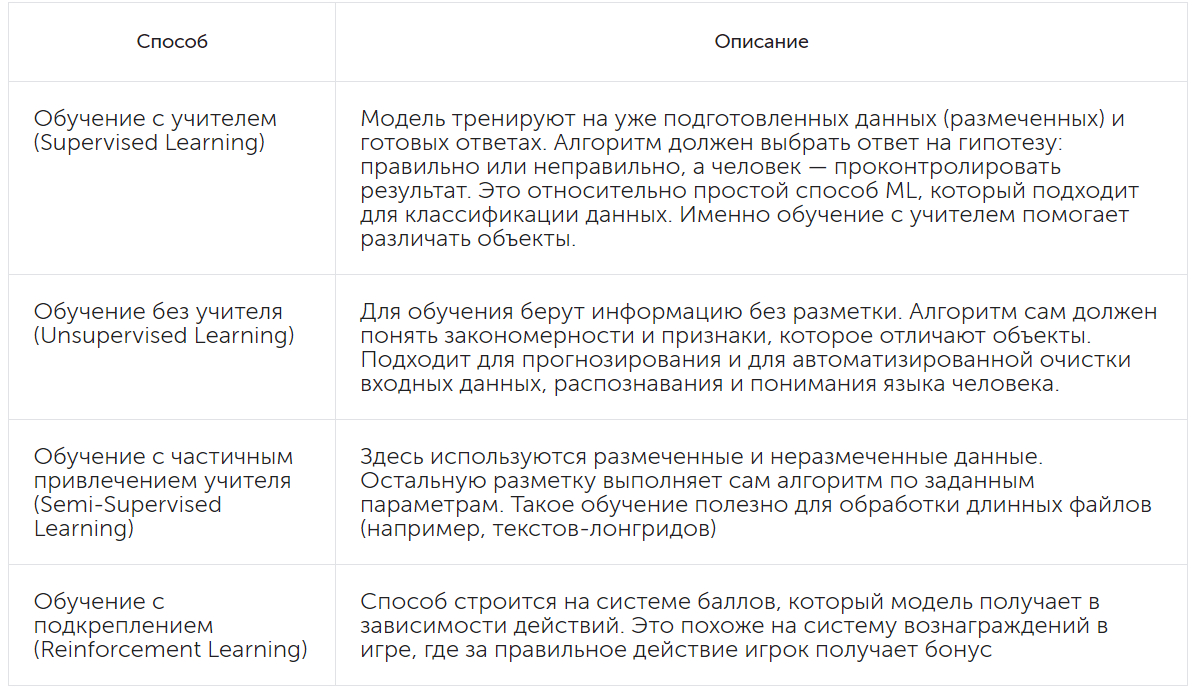
Способы ML классифицируются в зависимости от участия в нём человека. Существует машинное обучение с учителем, без учителя, с частичным привлечением учителя и с подкреплением.
Также есть методы, которые разделяются по принципу работы алгоритма. Выделяют байесовский классификатор, деревья принятия решений, логистическую регрессию, ассамблейные методы (бэггинг, бустинг), кластеризацию к-средних, состязательно-генеративное обучение и другие.
* продукт компании Meta, запрещённой на территории РФ
Подписывайтесь на наш телеграм-канал. Там вы найдёте актуальные новости в области digital-маркетинга, полезные статьи и интересные исследования. Будьте в теме вместе с нами :)