Как SAFe в разработке IT-оборудования помог повысить предсказуемость на 40%

SAFe — сложный фреймворк, так как подразумевает трансформацию процессов во всей компании. Его внедрение часто ассоциируется с Jira и сторонними плагинами системы, но одна инженерная компания доказала, что это не единственный путь. Она реализовала SAFe в Kaiten без внешних интеграторов и добилась ощутимых результатов.
Мы не можем раскрыть название компании, но можем рассказать о ее деятельности и деталях внедрения. Всем этим поделится Сергей, под чьим контролем и начался переход SAFe. Ниже Сергей расскажет, как устроена разработка внутренних продуктов и что позволило поднять предсказуемость поставок с 35% до 75%.
Компания искала инструмент для реализации SAFe
Наша компания занимается производством IT-оборудования, например систем хранения данных для дата-центров. В штате около 7000 сотрудников.
Мы не занимаемся сборкой оборудования, а в основном разрабатываем его и производим на своих же площадках.
Одно из направлений в компании — внутренние продукты: инфраструктура, безопасность, цифровые сервисы вроде личного кабинета и учетных систем. В сумме — около 40 продуктов.
Для разработки внутренних сервисов мы применяем продуктовый подход, который позволяет быстро реагировать на изменения требования заказчиков и развивать продукты.
Раньше команды были небольшие, а горизонт планирования — буквально две недели.
В 2023 году мы поняли, что пора расти, и начали вдобавок к продуктовому подходу использовать фреймворк SAFe — Agile-методологии для крупных компаний с упором на масштабирование и взаимодействие между командами. Все ради роста предсказуемости, аптайма и команд.
Разработкой внутренних продуктов занимаются около 500 сотрудников. 200 из них работают в Kaiten. Также таск-трекер используют 50–70 ключевых заказчиков — стейкхолдеры, которые запускают IT-инициативы.
Jira и Excel-таблицы не подошли для SAFe: слишком сложно и долго
Дивизионы компании, которые разрабатывают внешние продукты, ведут процессы и задачи в Jira, но для SAFe-подхода она не годится. У системы сложный интерфейс, поэтому даже незначительные изменения вносятся медленно. Рассматривали Miro: не устроило то, что в этом сервисе элементы — по сути статичные стикеры, и синхронизацию артефактов пришлось бы проводить вручную.
Также в других программах мешали отсутствие единого PI-борда (Planning Interval-борд) и долгие SLA на изменение схемы, конфликт версий файлов. Для Jira есть плагины, которые заточены под SAFe-подход и частично решают проблемы, но эти решения слишком дорогие. Такой вариант не подходил, особенно на старте.
Без быстрой настройки досок SAFe-трансформация невозможна, поэтому нам были важны гибкость, простота администрирования и ежедневные корректировки. Также не последнюю роль играла бюджетная стоимость решения, поскольку мы запускали фреймворк внутренними силами.
Сначала мы пробовали оцифровывать и вести процессы в Excel, описывали фичи и пользовательские истории в табличном формате. Но это оказалось неудобно, особенно когда пользователей стало много.
В итоге подошел Kaiten. Нас привлекли следующие особенности:
- Гибкость и наглядность досок. Мы хотели использовать канбан не только классическим способом, где колонка — это «статус» задачи, но и для статичного визуального отображения, например как PI Board в Agile.
- Интерактивность. С любыми элементами можно взаимодействовать и таким образом настроить систему под себя.
- Быстрые корректировки. Простой интуитивно понятный интерфейс позволяет вносить изменения сходу, в режиме реального времени.
Почти полностью перешли в Kaiten за год
Мы начали работать по SAFe-фреймворку в конце 2023 года.
Старт SAFe — октябрь 2023. Начали в Excel, но быстро отказались от таблиц — в таком формате воспринимать фичи и другие артефакты было неудобно. Решили попробовать Kaiten.
Переход на Kaiten — ноябрь 2023. Протестировали сервис — сначала использовали пилотную версию, затем развернули полноценную On-Premise лицензию.
Начали готовить бэклоги и моделировать цифровые доски для ближайшего квартального планирования. За 2–3 месяца «своими руками» оцифровали процессы и настроили основную структуру — без внешних интеграторов. Создали несколько типов элементов, например Features и User Stories.
Первое PI-планирование — февраль 2024. Провели его на 200 участников с помощью досок в Kaiten.
Дальнейшая миграция — лето 2024. Более 20 команд переехали в Kaiten и стали использовать его как единственный инструмент, в Jira остались всего 5-6.
Портфельная доска с Timeline и BI-дашборды — январь 2025. На ней находятся Epic.
У сотрудников было сопротивление — многие не понимали, зачем нужен Kaiten, если есть старая добрая Jira. Мы постепенно преодолевали этот барьер, обучали команды. В течение года почти все команды перешли в Kaiten и отказались от Jira.
В Kaiten у нас достаточно сложная структура, например несколько уровней бэклогов, чего нет в Jira. Чтобы помочь сотрудникам разобраться, мы привлекали Scrum-мастеров. А еще разработали подробные инструкции по постановке задач и работе с карточками.
Уложили иерархию SAFe в Kaiten и создали пять уровней досок
У SAFE-фреймворка есть определенная иерархическая структура, классическая для Agile — вот как она устроена сверху вниз:
- OKR — стратегия компании;
- Epic — инициативы, которые поддерживают OKR;
- Features — крупные функции;
- User Story — элементы, которые реализуют фичи.
Мы переложили эту структуру в Kaiten: для каждого уровня — свой бэклог. В итоге получились такие пространства и доски:
Уровень 1. ART — общая доска всех команд, на котором объединены все Upstream и есть общий Downstream. Сюда стекаются все идеи и карточки. Доска устроена по нетипичной механике. Столбцы визуализируют не стадии, а периоды, а строки — это команды. При планировании задачи на квартал мы помещаем сюда карточку и не двигаем.
Уровень 2. Strategy — сюда дублируем OKR из Jira.
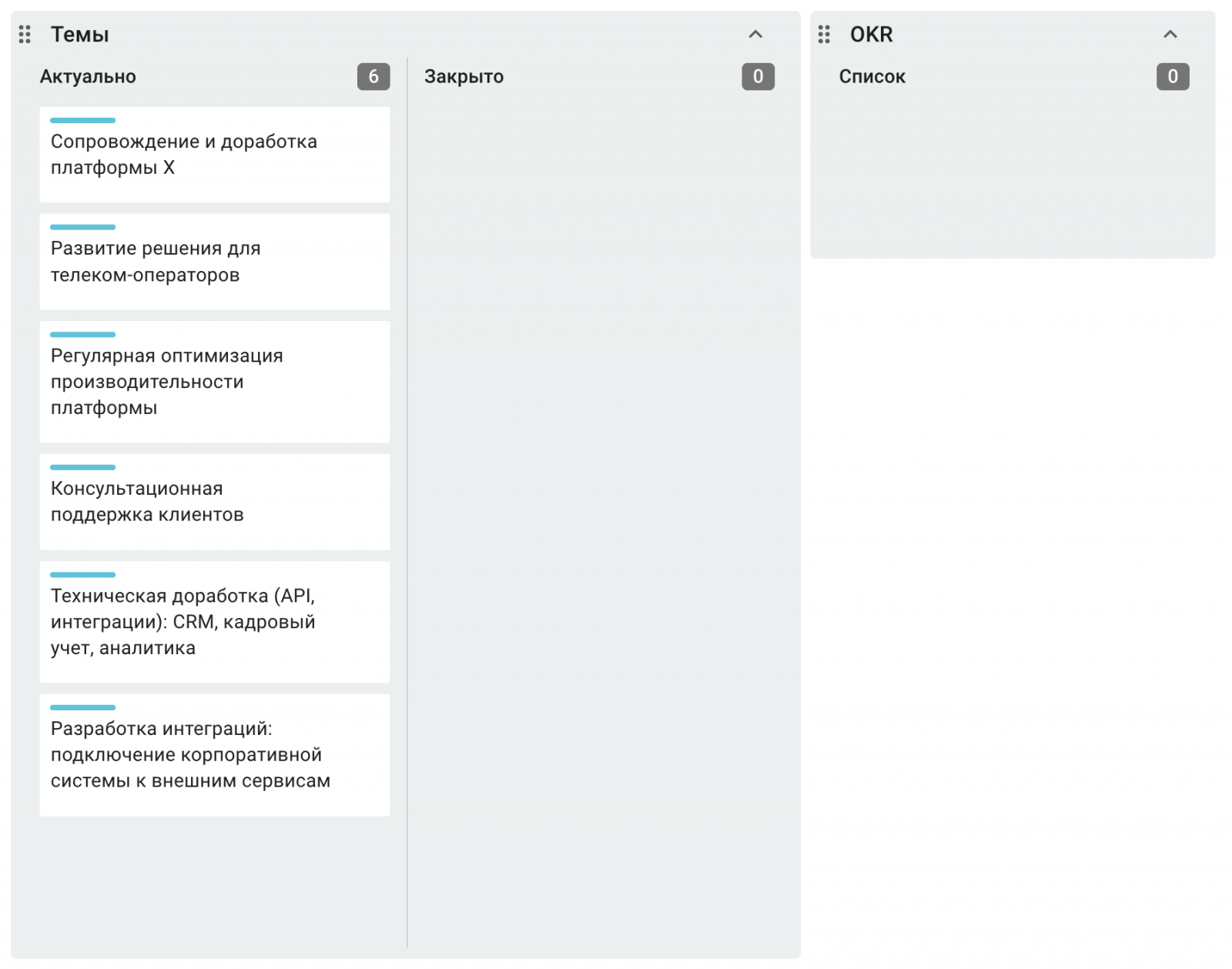
Уровень 3. Portfolio, или дорожная карта — отдельная канбан-доска, которая связывает стратегию с крупными Epic на уровне собственников и руководства. В дальнейшем разбиваем эпики на более мелкие. Карточки проходят несколько этапов.
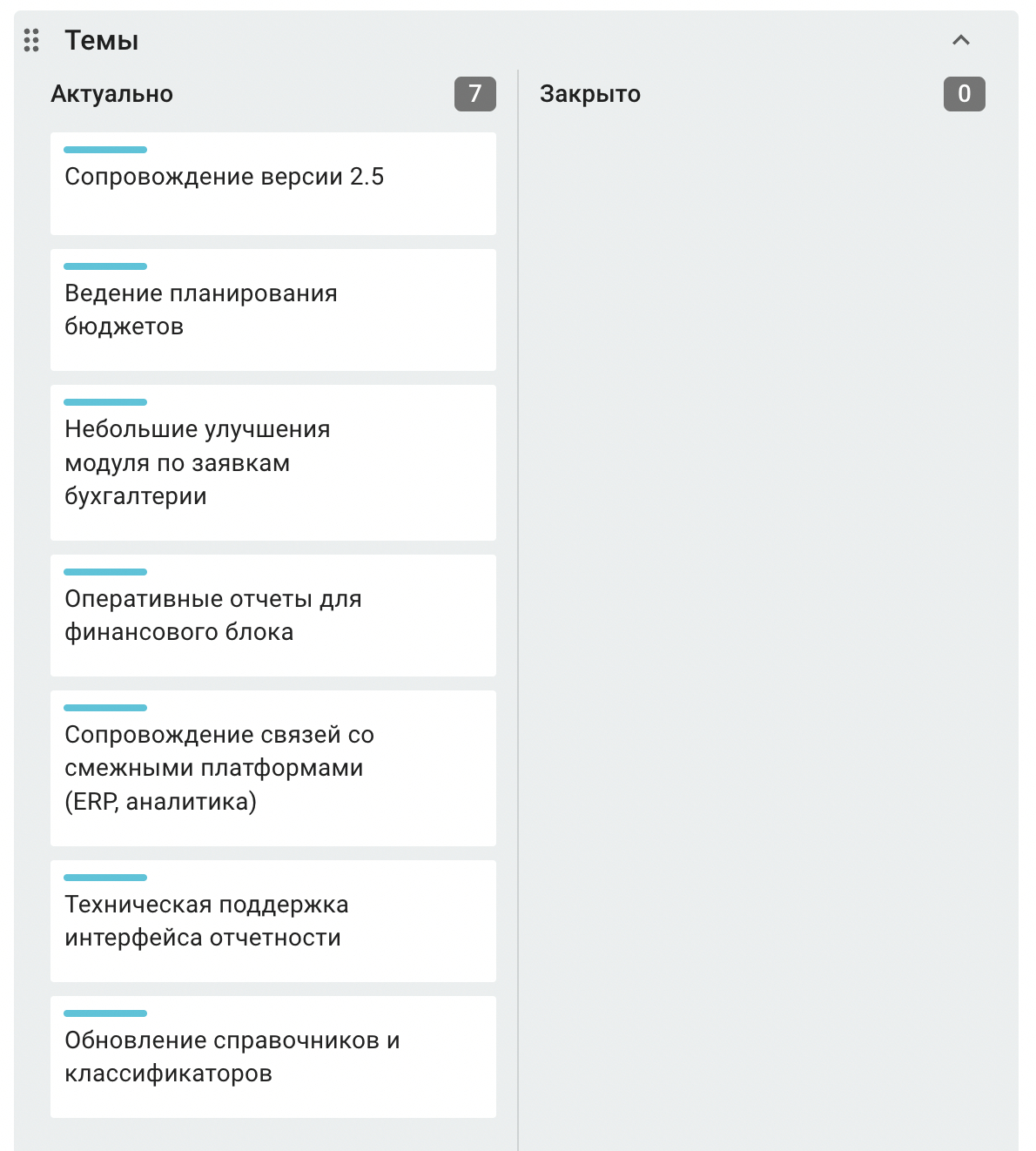
Для Epic есть отдельный Upstream: идеи проходят ревью, анализ и подготовка к постановке в очередь.
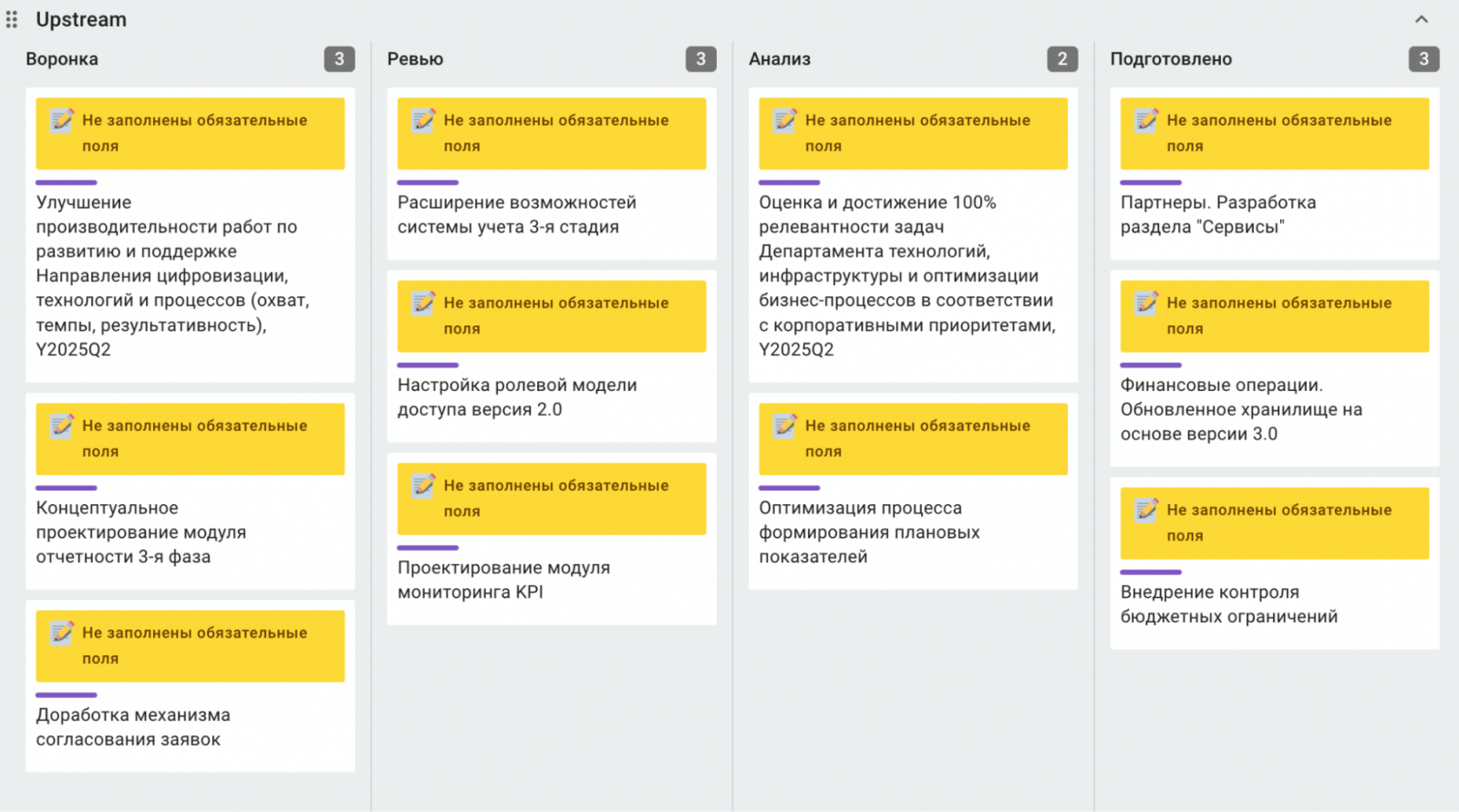
А также Downstream, в который входят стадии реализации, продолжения и развития MVP. Иногда мы прекращаем разработку идей — они попадают в колонку «Отменен». А если продукт запущен — в столбец «Завершен».
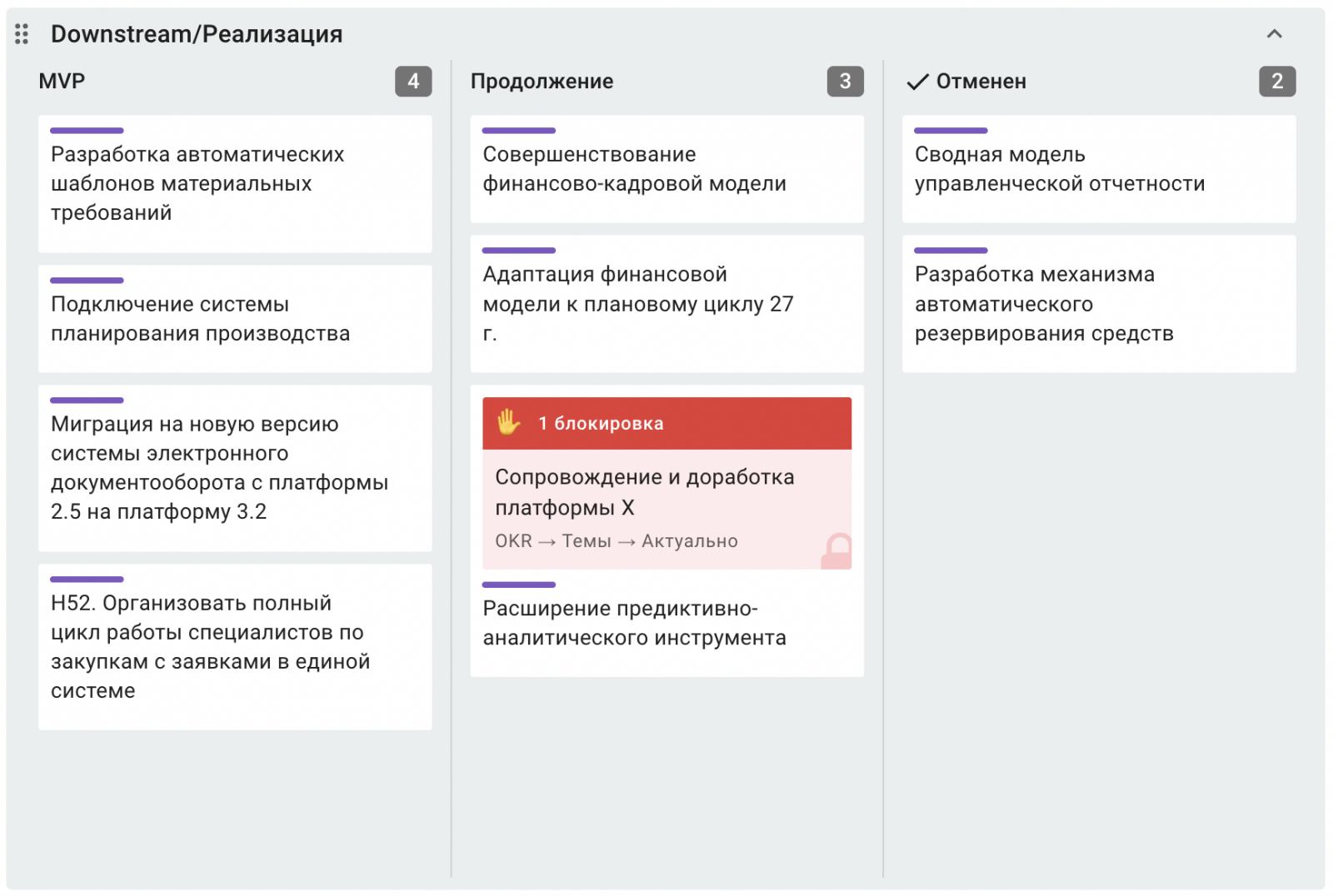
Уровень 4. Квартальный PI-Board — здесь объединены в группы от 5 до 12 команд — от 100 до 150 разработчиков. Мы называем каждый элемент Train, например Agile Release Train HR Tech занимается задачами, связанными с внутренними сервисами для сотрудников.
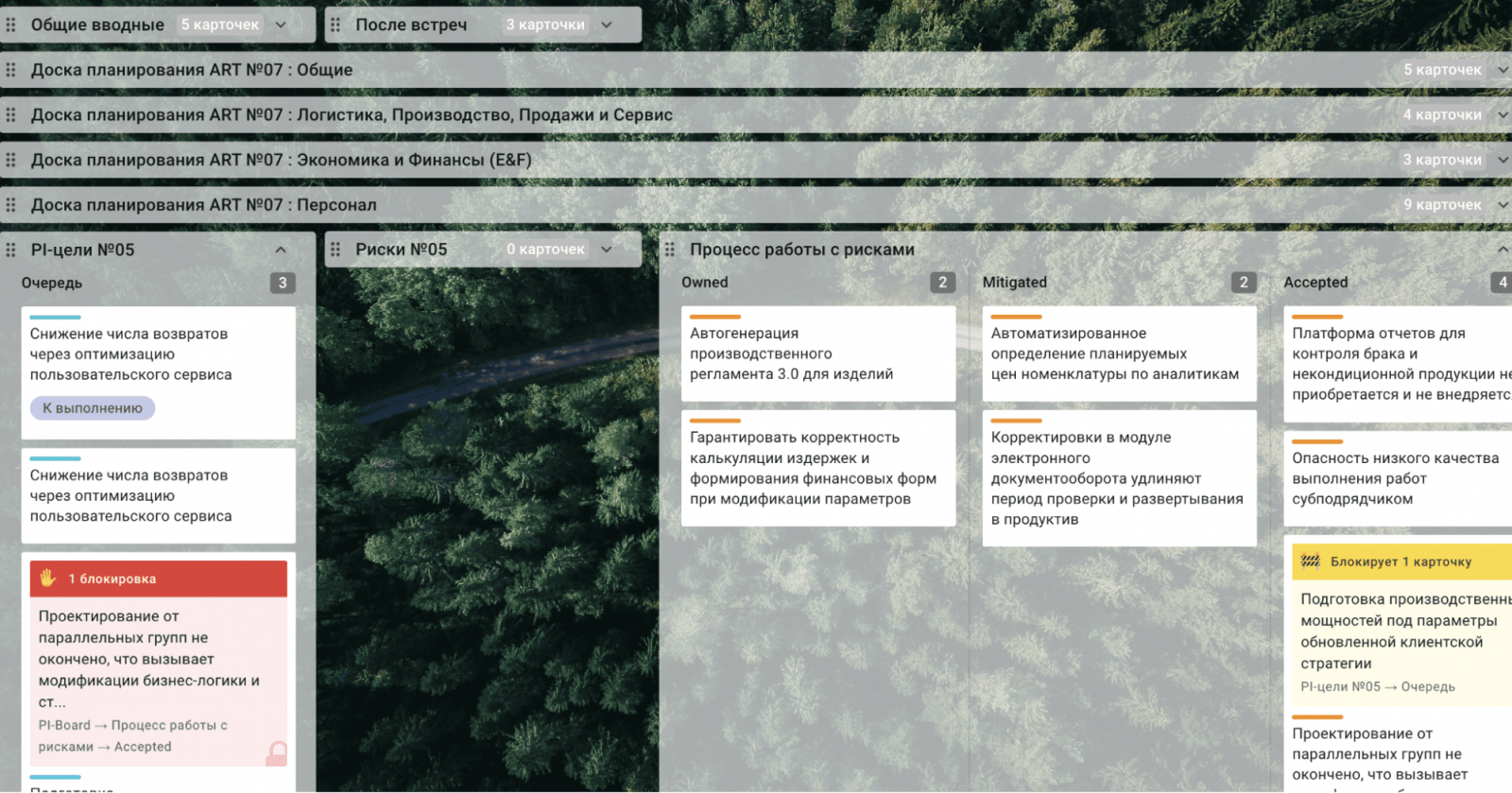
У каждой команды свой уровень бэклога. В нем находятся карточки-Features, которые на канбан-доске проходят три стадии: идея, анализ, подготовка к приоритизации. Сюда попадают основные идеи. Тут же ставим цели и прогнозируем риски на квартал.
Уровень 5. Командный канбан — классическая доска со столбцами-этапами. Здесь мы с помощью встроенной механики Kaiten декомпозируем Features на User Stories, которые двигаются по стадиям: от идеи до реализации.

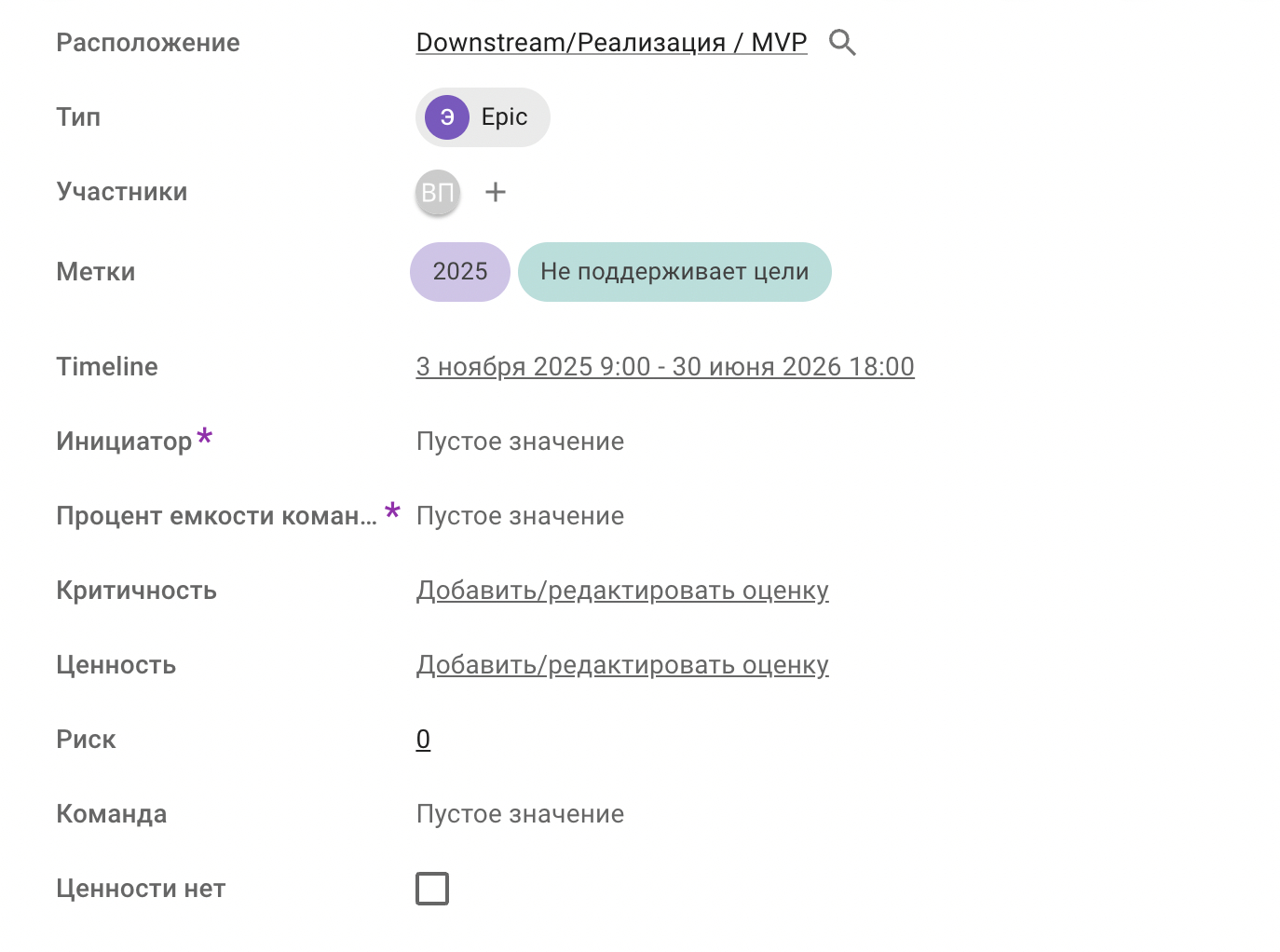
Epic, Feature и User Story мы также разделили на два подтипа: бизнесовые и вспомогательно-технические. У каждого — свой набор полей в карточках, классический для SAFe-подхода. Например:
- для User Story — описание и оценка в Story Points.
- для Features — описание будущей функции, приоритизация по WSJF, риски, критерии приемки, метрики для измерения гипотезы, оценка в Story Points.
- Epic — гипотеза, финансовые показатели.
Epic, Feature и User Story связаны между собой родительско-дочерней связью — так наглядно видно соответствия между элементами.
В нашей системе карточки Feature ведут «двойную жизнь», то есть существуют одновременно на двух разных досках:
- Первая — классическая канбан-доска, на которой двигают карточки по этапам.
- Вторая — статичный PI-Board для визуализации периодов, где статус задачи меняется в поле. Эта доска существует в течение квартала, а когда он заканчивается, перемещаем ее в архив.
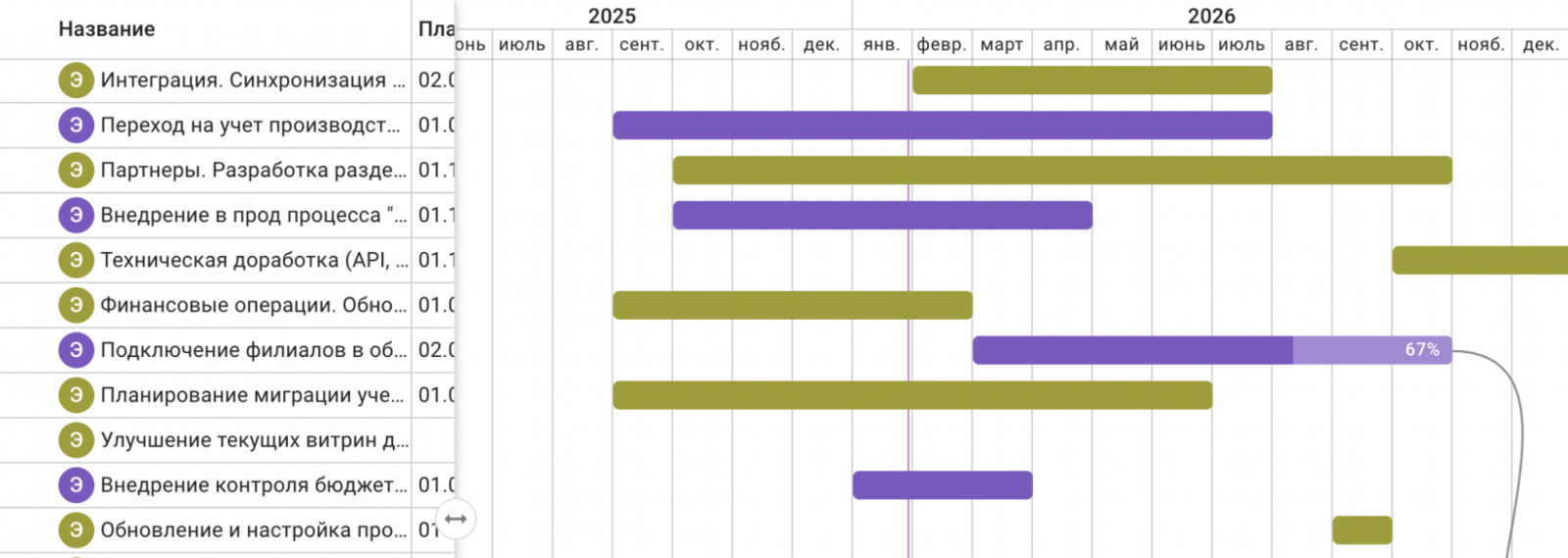
Также мы просматриваем Features и Epic на диаграмме Ганта, но не по методике классического проектного управления. Раскладываем карточки по периодам — это позволяет понять, сколько ресурсов на каком этапе потребуется и когда будет реализован тот или иной Epic. Также видим здесь процент реализации.
Повысили предсказуемость и масштабировали команду: результаты перехода на SAFe
Благодаря Kaiten мы 1,5 года реализуем SAFe-подход в разработке. Вот к чему пришли за это время:
- Plan-to-Fact, или предсказуемость, повысилась с 35% до 75%.
- Uptime — с 75% до 99,95%.
- Количество разработчиков выросло с 45 до 220.
Мы делали трансформацию с целью масштабирования и повышения управляемости, и добились ее. Kaiten помог запустить этот процесс, например наладить управление бэклогами.
Кроме того, за 2024 год мы ввели полноценные процессы, например конвейеры сборки, десятки тысяч тестов еженедельно перед релизом. Это повысило качество продуктов, доступность выросла до 99,95%, несмотря на стремительное увеличение команд.
Есть и узкие места: ручное дублирование Feature и ограниченные автоматизации. Из-за них приходится тратить много времени на рутинную работу в Kaiten, но мы надеемся, что в будущем это исправят.
Планируем внедрить новые метрики и дашборды
На будущее мы запланировали несколько векторов развития. Продолжим формировать практику портфельного управления: бэклоги, принципы описания артефактов. Kaiten играет в этом ключевую роль, поскольку мы реализуем SAFe-подход именно там.
Хотим с помощью метрик наладить связи OKR с Epic вплоть до команд: что именно делается, для чего, с какой скоростью. Сложность в том, что OKR компании только формируется, но наша цель — сделать так, чтобы они приносили максимум пользы.
Кроме того, хотим ввести flow-метрики — Lead Time, Throughput — на всех уровнях бэклогов, чтобы системно управлять потоками. Сейчас с ним есть сложности, в основном мы просто наблюдаем, эмпирически вносим изменения и получаем некий результат. Также в будущем откроем дашборды self-service.