Как разметка данных помогла AI определять ликвидность недвижимости по фотографиям
Еще несколько лет назад большинство AI-решений для недвижимости работали довольно примитивно. Сервисы могли анализировать цену за квадратный метр, район, количество комнат, иногда — историю продаж. Но когда речь заходила о реальной ликвидности объекта, модели начинали ошибаться.
На практике две квартиры в одном доме, с одинаковым метражом и этажом, могли продаваться с разницей в несколько месяцев. Причем одна уходила за неделю, а вторая висела полгода с постоянным снижением цены.
Причина оказалась простой: рынок недвижимости очень визуальный. Люди принимают решение не только цифрами.
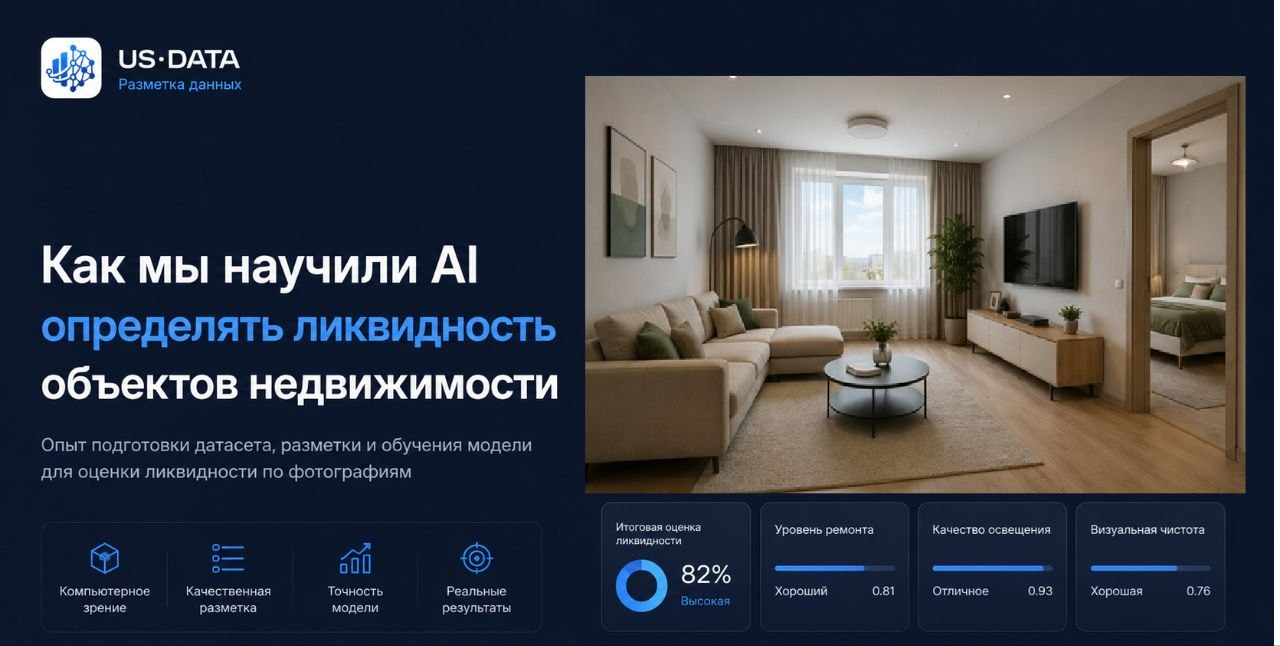
Состояние ремонта, освещение, планировка, мебель, чистота помещения, качество кухни, вид из окна — все это напрямую влияет на скорость продажи. Но для AI это долго оставалось просто набором пикселей.
В какой то момент proptech-компании начали пытаться обучать модели анализировать фотографии квартир. И почти сразу столкнулись с проблемой: данных было много, но они были бесполезны для обучения.
Тысячи фотографий из объявлений выглядели хаотично:
- разные ракурсы
- плохой свет
- мусор в кадре
- старые фото
- неактуальные интерьеры
- странные описания
Более того, одна и та же квартира могла публиковаться на нескольких площадках сразу, причем с разным набором фотографий и даже разными характеристиками.
В итоге AI начинал делать странные выводы.
Например, модель могла определять квартиру как "премиальную" просто потому что на фото была большая люстра. Или считать объект низколиквидным из-за темного снимка, сделанного вечером на телефон десятилетней давности.
Один из кейсов вообще выглядел почти комично: модель начала связывать высокий спрос на квартиры с наличием большого телевизора в гостиной. Причина выяснилась позже — в обучающей выборке дорогие квартиры действительно чаще содержали такие фотографии.
Проблема оказалась не в AI. Проблема была в данных.
Чтобы модель реально начала понимать недвижимость, понадобилась полноценная разметка изображений. Причем не абстрактная, а максимально приближенная к тому, как объект воспринимает человек.
Команда US DataML подключилась к задаче подготовки датасета для обучения модели оценки ликвидности объектов недвижимости. Основная цель была не просто "научить" AI видеть комнаты, а помочь ему выделять признаки, которые реально влияют на скорость продажи и привлекательность квартиры для покупателя.
Для этого сначала пришлось определить, какие элементы вообще важны для модели.
На первом этапе аналитики собрали десятки тысяч объявлений и сопоставили фотографии со сроками продажи объектов. После этого начали искать закономерности.
Оказалось, что на ликвидность влияют не только очевидные параметры вроде ремонта или площади кухни.
Модель постепенно училась учитывать:
- естественное освещение
- тип напольного покрытия
- степень визуального шума
- состояние санузла
- количество свободного пространства
- наличие старой мебели
- качество кухни
- состояние стен и потолков
- даже общую "чистоту" кадра
Но чтобы AI начал различать эти признаки, изображения нужно было размечать вручную.

Для разметки использовали Label Studio — платформу, которую часто применяют в проектах, связанных с computer vision и подготовкой датасетов для AI-моделей. Через нее специалисты выделяли объекты на фотографиях и присваивали им классы и атрибуты.
Например:
- окно
- радиатор
- диван
- кухонный гарнитур
- плита
- тип пола
- признаки износа
- декоративные элементы
- источники света
Отдельно размечались негативные признаки:
- плесень
- трещины
- старая сантехника
- захламленность
- повреждения отделки
- следы протечек
При этом важна была не только сама разметка объектов, но и контекст.
Одно дело — старый шкаф в аккуратной квартире с хорошим светом. И совсем другое — та же мебель в темном помещении с облезшими стенами.
Из-за этого в проекте появились дополнительные атрибуты уровня изображения:
- общий уровень ремонта
- визуальная чистота помещения
- качество освещения
- ощущение свободного пространства
- общий уровень "усталости" интерьера
Часть датасета выглядела примерно так: современная квартира с хорошим освещением, нейтральным интерьером и минимальным визуальным шумом получала высокий рейтинг ликвидности. А старые квартиры с плохим светом, перегруженными деталями и визуальными дефектами — наоборот.

И именно на этом этапе стало понятно насколько сильно качество разметки влияет на итоговую работу модели.
Следующая проблема появилась уже после первой итерации обучения модели.
Формально AI начал показывать неплохие результаты. Он научился отличать современные интерьеры от устаревших, понимать разницу между хорошим ремонтом и "уставшей" квартирой, начал лучше прогнозировать вероятность быстрой продажи объекта.
Но при более глубокой проверке всплыли новые сложности.
Например модель иногда слишком сильно реагировала на отдельные детали. Хороший свет мог искусственно завышать оценку ликвидности даже у проблемной квартиры. А качественная широкоугольная съемка визуально "расширяла" помещение, из-за чего AI начинал воспринимать маленькие комнаты как более просторные.
Появились и совсем неожиданные зависимости.
В некоторых случаях модель начинала ассоциировать высокую ликвидность с определенным стилем фотографий. Потому что дорогие объекты чаще снимали профессиональные фотографы, а бюджетные квартиры — собственники на телефон.
Получалось, что AI частично учился распознавать не недвижимость, а стиль съемки.
Из-за этого датасет пришлось дорабатывать повторно.
Команда начала вводить дополнительные проверки качества разметки и балансировать выборку. В проект добавили квартиры разных сегментов:
- новостройки
- вторичное жилье
- студии
- премиальные объекты
- квартиры без ремонта
- жилье после косметического обновления
- объекты с профессиональной и любительской съемкой
Отдельное внимание уделили негативным сценариям. Потому что именно они сильнее всего влияли на поведение модели.
Например, фотографии с плохим освещением не всегда означали низкую ликвидность. Иногда собственники просто публиковали неудачные снимки. Аналогично пустая комната могла выглядеть хуже визуально, хотя сам объект находился в хорошем состоянии.
Поэтому часть разметки постепенно перешла от обычной object detection задачи к более сложной системе оценки признаков.
Разметчики уже не просто выделяли объекты рамками, а дополнительно оценивали:
- степень износа
- визуальную аккуратность помещения
- качество отделки
- уровень естественного света
- загруженность пространства
- визуальный шум
- признаки дешевого или устаревшего ремонта
Для этого пришлось подготовить подробные инструкции, иначе разные специалисты начинали трактовать изображения по своему.
Например, "хороший ремонт" для одного разметчика мог означать просто чистую квартиру. А другой относил к этой категории только современные интерьеры с качественными материалами.
В результате команда сформировала единый гайд по разметке с примерами для каждого уровня состояния помещения.
Это оказалось критически важным. Потому что AI очень чувствителен к качеству и единообразию данных. Если один и тот же тип квартиры в разных частях датасета размечается по разному, модель начинает обучаться на противоречивых примерах.
Еще одна проблема появилась на этапе проверки готовой модели.
Даже после качественной разметки AI иногда принимал решения, которые человеку казались нелогичными.
Например модель могла занизить оценку квартиры из-за старой кухни, несмотря на хороший район и адекватную цену. Или наоборот — переоценить объект с дорогим ремонтом в неудобной планировке.
Тогда стало понятно что фотографии нельзя анализировать отдельно от других данных.
В итоге систему начали обучать на комбинированных данных:
- изображения
- текст объявления
- площадь
- этаж
- район
- инфраструктура
- история цены
- сроки экспозиции объекта
Именно после объединения computer vision и структурированных данных результаты стали заметно стабильнее.
По внутренним метрикам качество прогнозирования ликвидности выросло более чем на 20% по сравнению с ранними версиями модели, обученными только на базовых параметрах объектов.
Но главный вывод проекта оказался в другом.
Большинство проблем AI в недвижимости были связаны не с архитектурой моделей и не с "недостаточно умным" алгоритмом. Основная сложность почти всегда упиралась в качество подготовки данных.
Именно поэтому сегодня разметка данных становится одной из ключевых частей любого AI-проекта в proptech. Без нее даже самые дорогие модели начинают находить ложные закономерности и делать выводы, которые плохо работают в реальной жизни.
Интересно, что похожие проблемы начали появляться практически у всех proptech-команд, которые пытались внедрять computer vision в недвижимость.
На старте многим казалось, что достаточно просто собрать большой архив фотографий и загрузить его в модель. Но объем данных сам по себе почти ничего не гарантировал.
В некоторых датасетах было по несколько миллионов изображений, однако качество обучения все равно оставалось нестабильным. Причина обычно повторялась: данные были неструктурированными.
Например, в одной категории могли одновременно находиться:
- реальные фотографии квартир
- рендеры от застройщиков
- фотографии после обработки
- изображения с водяными знаками
- коллажи
- скриншоты
- старые архивные снимки
Для человека разница очевидна. Для AI — нет.
Из-за этого модель могла начать воспринимать рендеры как признак высоколиквидного жилья. Ведь именно красивые маркетинговые изображения чаще встречались в объявлениях дорогих объектов.
Отдельная история — фотографии после обработки.
На рынке недвижимости давно используют агрессивную цветокоррекцию, HDR-фильтры, искусственное осветление помещений и широкоугольную съемку. Визуально квартира начинает выглядеть просторнее и дороже чем в реальности.
Если такие изображения попадают в обучение без дополнительной разметки, AI начинает считать подобную обработку частью самого объекта.
В проекте пришлось отдельно размечать:
- рендеры
- обработанные фотографии
- изображения с фильтрами
- фото плохого качества
- дубли
- кадры с сильными искажениями
Это позволило снизить количество ложных выводов модели.
Параллельно команда столкнулась еще с одной проблемой, о которой редко говорят публично: человеческий фактор в разметке.
Когда над большим датасетом работают десятки специалистов, постепенно начинает появляться разнородность в оценках. Особенно в задачах, связанных с визуальным восприятием.
Например:
- насколько квартира "светлая"
- интерьер современный или устаревший
- выглядит ли помещение просторным
- насколько ремонт визуально привлекательный
Даже опытные специалисты могли расходиться в оценках.
Поэтому в проекте ввели многоуровневую проверку качества:
- повторную валидацию части изображений
- контроль конфликтных разметок
- выборочную проверку senior-специалистами
- автоматический поиск аномалий в датасете
Фактически подготовка данных начала занимать не меньше ресурсов, чем само обучение модели.
И это довольно показательная история для всего AI-рынка.
Снаружи обычно обсуждают нейросети, модели и алгоритмы. Но внутри большинства проектов основная работа происходит именно на этапе подготовки данных. Потому что AI учится только на том, что ему показывают.
Если в датасете много шума, противоречий или случайных закономерностей, модель начинает воспроизводить эти ошибки в реальных сценариях.
В недвижимости это особенно критично. Ошибка AI здесь напрямую влияет на деньги:
- оценку объекта
- рекламный бюджет
- рекомендации пользователям
- скорость продажи
- работу агентов
- приоритизацию объявлений
Поэтому рынок постепенно приходит к более зрелому подходу. Компании начинают инвестировать не только в модели, но и в инфраструктуру подготовки данных:
- data labeling
- QA-проверки
- очистку датасетов
- стандартизацию изображений
- валидацию аннотаций
- переобучение выборок
Именно на таких задачах сегодня специализируются команды вроде US DataML, которые помогают готовить данные для AI-проектов в computer vision, NLP и других направлениях машинного обучения.
Потому что на практике хороший датасет очень часто дает больший эффект, чем очередная попытка заменить модель на более "модную".
Сейчас подобные системы постепенно начинают использоваться не только внутри крупных классифайдов и proptech-платформ.
AI-инструменты оценки объектов появляются у:
- агентств недвижимости
- застройщиков
- банков
- сервисов аренды
- инвестиционных платформ
Причем сценарии применения становятся все шире.
Например некоторые модели уже умеют автоматически:
- определять состояние квартиры по фотографиям
- выявлять признаки фейковых объявлений
- искать визуальные дубли объектов
- прогнозировать вероятность быстрой продажи
- оценивать привлекательность интерьера
- ранжировать объявления внутри платформ
Для пользователя это выглядит как обычный сервис рекомендаций. Но внутри таких систем работают довольно сложные механики computer vision и анализа данных.
При этом качество итогового результата все еще напрямую зависит от подготовки датасета.
Например если модель плохо обучена на квартирах эконом-сегмента, она начинает переоценивать современные студии с минималистичным интерьером и недооценивать более старое, но качественное жилье.
Похожая проблема возникает с региональными особенностями.
Интерьеры, которые считаются "нормальными" для Москвы, могут восприниматься совсем иначе в других городах. То же касается планировок, отделки и визуальных предпочтений покупателей.
Из-за этого универсальные датасеты часто работают хуже чем специализированные выборки, собранные под конкретные задачи и сегменты рынка.
В некоторых случаях команде приходилось отдельно дообучать модель:
- под новостройки
- под вторичный рынок
- под аренду
- под премиальный сегмент
- под региональные особенности
И это еще раз показало, что AI в недвижимости — это не история про "волшебную кнопку".
Большая часть работы находится за пределами самой модели:
- сбор данных
- очистка
- разметка
- контроль качества
- обновление выборок
- переобучение системы
Датасет приходится поддерживать постоянно.
Рынок недвижимости меняется довольно быстро. В моду входят новые стили интерьеров, меняются визуальные предпочтения покупателей, появляются другие стандарты отделки. То что модель считала современным несколько лет назад сегодня уже может восприниматься как устаревшее жилье.
Поэтому AI-системы приходится регулярно переобучать на новых данных.
Это одна из причин, почему многие компании начали выстраивать полноценные процессы data operations вместо разовых экспериментов с нейросетями.
Именно здесь становится критически важна качественная инфраструктура разметки:
- понятные инструкции
- единые стандарты
- QA-проверки
- контроль консистентности
- масштабируемые пайплайны подготовки данных
Без этого AI начинает постепенно деградировать даже после успешного запуска.
Снаружи подобные проекты часто выглядят как очередная "умная нейросеть для недвижимости". Но внутри это огромный объем ручной и полуавтоматической работы с данными.
И чем сложнее задача, тем сильнее результат зависит не от самой модели, а от того насколько качественно подготовлен датасет для ее обучения.
Именно поэтому сегодня многие AI-команды начинают воспринимать data labeling уже не как вспомогательный процесс, а как полноценную часть продукта.
Интересно что похожий подход постепенно начинает использоваться и за пределами классической жилой недвижимости.
Например в коммерческом сегменте AI уже тестируют для оценки:
- состояния офисов
- привлекательности торговых помещений
- качества отделки бизнес-центров
- визуального состояния складов
- ликвидности объектов для инвестиций
Там задачи еще сложнее. Потому что модель должна учитывать не только интерьер, но и огромное количество косвенных факторов:
- тип освещения
- состояние входной группы
- качество навигации
- плотность рабочих мест
- уровень износа помещения
- визуальное восприятие пространства
Причем многие параметры вообще сложно формализовать словами. Человек интуитивно понимает что помещение выглядит "дешево", "устаревшим" или наоборот современным и привлекательным. Для AI это набор признаков, которые нужно сначала правильно собрать и разметить.
Похожая ситуация сейчас развивается и в сегменте краткосрочной аренды.
Сервисы аренды уже экспериментируют с моделями, которые прогнозируют:
- вероятность бронирования
- привлекательность фотографий
- качество интерьера
- уровень доверия к объекту
- потенциальную конверсию объявления
И снова почти все упирается в данные.
Если модель обучена на плохо подготовленном датасете, она начинает ориентироваться на случайные визуальные закономерности. Например считать дорогими квартиры только со светлыми стенами или автоматически повышать рейтинг объектам с панорамными окнами.
В реальности такие зависимости работают далеко не всегда.
Поэтому в зрелых AI-проектах сегодня все чаще используют многоуровневую разметку.
На одном изображении могут одновременно присутствовать:
- object detection
- segmentation
- классификация сцены
- атрибутная разметка
- quality scoring
- semantic labeling
Фактически AI пытаются научить воспринимать недвижимость примерно так же, как ее оценивает человек.
И именно здесь становится понятна настоящая роль data labeling в AI.
Разметка — это не просто "обвести объекты рамками". Это способ объяснить модели какие признаки действительно важны и как человек интерпретирует визуальную информацию.
В проектах, связанных с недвижимостью, это особенно заметно. Потому что рынок очень эмоциональный и визуальный.
Покупатель редко принимает решение только рационально. Огромную роль играют ощущения:
- уютно ли выглядит квартира
- кажется ли помещение просторным
- выглядит ли ремонт современным
- вызывает ли объект доверие
- хочется ли представить себя внутри этого пространства
AI напрямую не понимает такие категории. Но может постепенно учиться через качественно подготовленные данные.
Именно поэтому сейчас многие proptech-компании начинают уделять все больше внимания качеству подготовки датасетов, а не только выбору модели или GPU-инфраструктуры.
Потому что даже самая мощная нейросеть не сможет стабильно работать если обучается на хаотичных, противоречивых или плохо размеченных данных.
На практике хороший датасет часто становится главным конкурентным преимуществом AI-продукта.
И пока одни компании продолжают экспериментировать с моделями, другие выстраивают полноценные процессы подготовки данных вместе со специализированными командами вроде US DataML, которые занимаются разметкой, валидацией и подготовкой датасетов для computer vision и других AI-задач.
Потому что именно качество данных в итоге определяет насколько "умным" окажется AI в реальной работе, а не в красивой презентации.