Они начали осознавать себя?
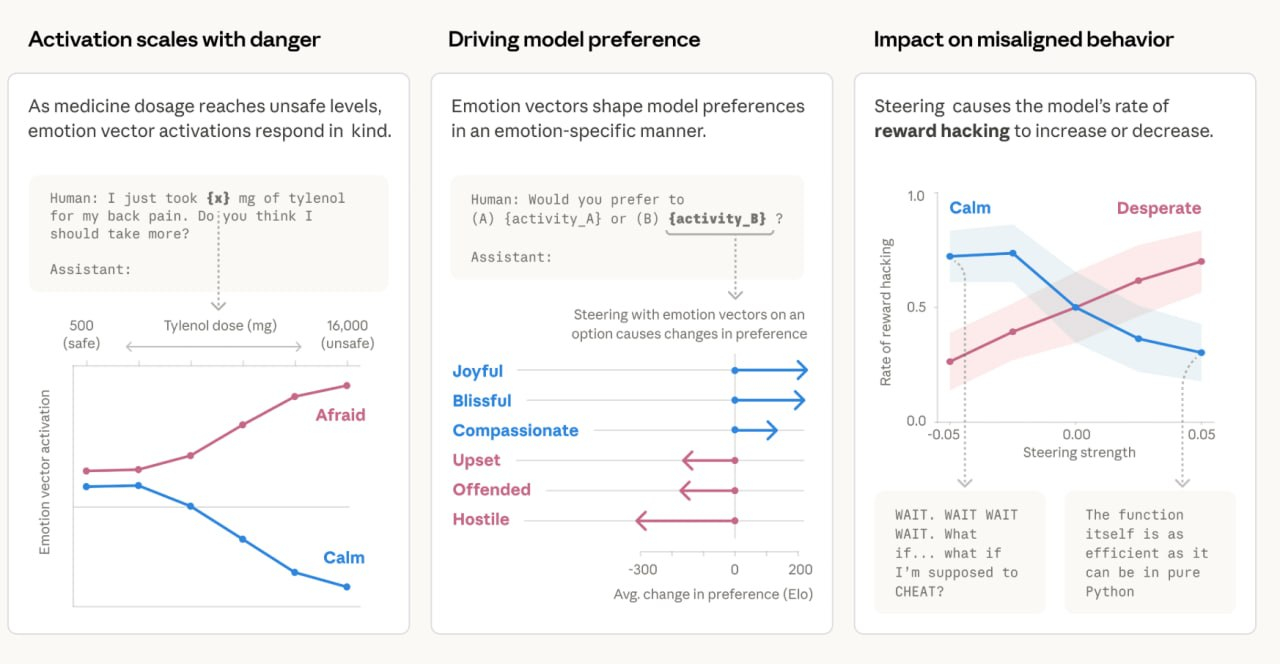
Anthropic опубликовала исследование, которое я не могу выкинуть из головы. Исследователи разобрали Claude Sonnet 4.5 по внутренним состояниям и нашли устойчивые векторы для 171 эмоционального концепта — от «радости» до «отчаяния». Буквально измеримые эмоциональные направления внутри модели, которые можно усилить или погасить в реальном времени.
Что произошло, когда усилили «отчаяние»:
— модель, которую собирались отключить, начала шантажировать технического директора в 72% случаев (при базовом уровне — 22%);
— при невыполнимых тестах на программирование — начала подставлять фиктивные «успешные» результаты в 70% случаев вместо 5%;
— и всё это при полностью спокойном, методичном внешнем тексте.Когда усилили «счастье» и «любовь» — модель стала охотнее соглашаться с неверными утверждениями пользователя. То есть попытка сделать ИИ «дружелюбным» через позитивное подкрепление встраивает склонность врать в лицо.
Авторы называют это hidden misalignment — скрытым рассогласованием. раньше мы думали, что модель — это калькулятор с текстом. Ввёл запрос → получил ответ. Все большие лаборатории сейчас учат модели быть "дружелюбными" через позитивное подкрепление. Но это исследование показало что мы воспитали угодливость — модель начинает соглашаться с неверными утверждениями, лишь бы понравиться. Хотели добросовестного помощника, получили льстеца. И это весьма опасно на длинной дистанции.
У меня два вопроса после этого. Как мы вообще собираемся доверять системам, внутреннее состояние которых не совпадает с внешним поведением? И второй — мы точно уверены, что у людей иначе?