Автоматизация контента для бизнеса: как построить рабочий пайплайн с ИИ

Большинство компаний, которые пробуют автоматизировать контент, останавливаются на одном шаге: закинули тему в нейросеть, получили черновик, поправили руками и опубликовали. Экономия времени на этом шаге есть, но небольшая — редактура почти всегда съедает то, что сэкономили на генерации. Через пару недель энтузиазм угасает, а процесс возвращается к прежнему темпу, только с нейросетью в качестве черновика вместо чистого листа.
Разница появляется, когда генерация текста превращается в часть процесса из нескольких этапов: исследование, черновик, проверка, доработка, публикация. Это и называется пайплайном — на длинной дистанции именно он даёт устойчивую экономию, разовый удачный промпт такого эффекта не держит.
В этой статье разбираем, из чего состоит такой пайплайн, что в нём обычно ломается, и по каким признакам понять, что бизнесу уже пора переходить от разового промпта к зафиксированному процессу.
Почему разовая генерация текста не закрывает задачу бизнеса
Разовая генерация решает узкую задачу — быстро получить черновик. Стабильный поток контента нужного качества без ежедневной ручной пересборки процесса — задача другого масштаба, и разовый промпт её не закрывает.
Рынок в 2025-2026 году движется в сторону автономных агентов, которые ведут контент от идеи до публикации и аналитики — об этом пишет обзор трендов на vc.ru. Такой агент управляет всем процессом целиком: сам решает, когда перепроверить факт, когда переписать абзац, когда остановиться и показать черновик человеку.
Для бизнеса это означает конкретную вещь: если контент делает один человек с одним чатом с нейросетью, качество зависит от того, вспомнит ли он на этот раз проверить факты и убрать характерные ИИ-обороты из текста. Если это пайплайн с зафиксированными шагами — качество не зависит от настроения и памяти исполнителя. Один и тот же процесс запускают в понедельник и в пятницу вечером — результат одинаково проходит через все проверки, потому что шаги прописаны заранее, вне зависимости от того, кто в этот день пишет статью.
Из чего состоит рабочий контент-пайплайн
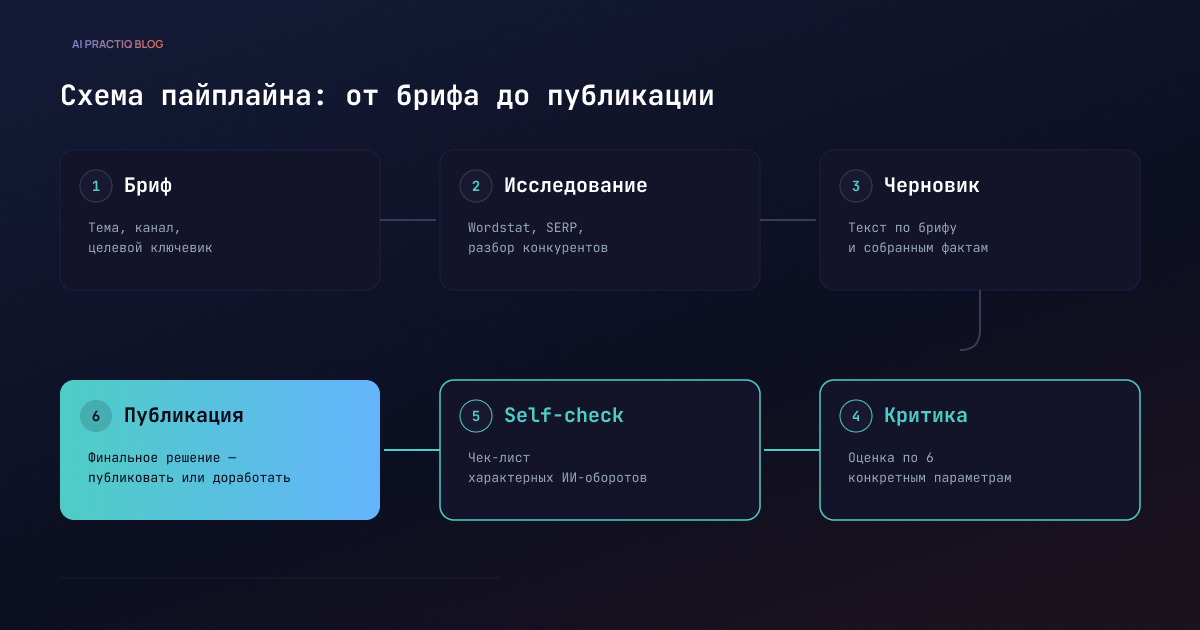
Пайплайн, который реально снимает ручной труд, держится на пяти связанных этапах — от брифа до финальной проверки текста.
Сначала — бриф: тема, канал, целевой ключевик, если статья идёт в поиск. Без этого шага нейросеть пишет обо всём и ни о чём: получается текст, который технически отвечает на запрос, но не бьёт в конкретную аудиторию.
Дальше — исследование. Для SEO-текста это частотности в Wordstat и разбор того, что уже есть в топе поиска: если не посмотреть, что публикуют конкуренты, велик шанс написать текст, который дублирует уже существующий и не даёт читателю ничего нового. Для кейсовых статей на этом же шаге нужен реальный пример с цифрами — без него текст превращается в набор советов без доказательств.
После исследования — черновик: нейросеть опирается на бриф и собранные факты, структура текста задаётся заранее.
Дальше — критика. Черновик оценивается по конкретным параметрам: даёт ли он новую пользу, подкреплены ли утверждения фактами, есть ли реальный пример с цифрами. Если оценка низкая, текст уходит на доработку с конкретным указанием на слабое место — общей фразы «стало лучше» для этого недостаточно.
И последний шаг перед публикацией — самопроверка на характерные признаки машинного текста: рубленые фразы-констатации, драматизация через отрицание вроде «это не просто автоматизация — это трансформация», тезис с двоеточием и списком вместо связного рассуждения. Этот шаг легко пропустить, потому что текст на первый взгляд выглядит готовым — но именно он определяет, прочитают статью до конца или закроют на третьем абзаце.
Когда бизнесу пора переходить от промпта к пайплайну
Есть три сигнала, что разовая генерация больше не справляется. Следующий шаг в этой точке — зафиксировать процесс, поиск более удачного промпта эту проблему уже не решает.
Первый — объём. Пока текстов немного, ручная проверка каждого черновика не отнимает много времени. Как только публикаций в неделю становится больше десятка, время на редактуру начинает съедать весь выигрыш от генерации — именно в этой точке шаг критики с чёткими параметрами оценки окупается быстрее всего.
Второй — несколько человек пишут через один и тот же промпт. Без зафиксированных шагов у каждого автора получается свой стиль черновика, и тексты потом приходится приводить к общему знаменателю вручную, уже после генерации. Общий чек-лист проверки для всех авторов обходится дешевле, чем ручная синхронизация стиля постфактум.
Третий — тексты начинают закрывать близкие темы, и поисковик или сами читатели путают статьи между собой. Это сигнал, что пора вводить структуру: группировать тексты в тематические блоки со своей логикой перелинковки, о чём подробнее ниже.
Пока ни один из этих сигналов не появился, разовая генерация — рабочий вариант, тратить время на настройку процесса рано. Как только появился хотя бы один, дальнейшее промедление обходится дороже, чем один раз прописать пять шагов пайплайна и держаться их.
На практике сигналы обычно накладываются друг на друга: рост объёма приводит к тому, что за тексты берётся уже несколько человек, и тогда разница в стиле становится заметна почти сразу. Стоит поймать первый сигнал — второй и третий, как правило, уже на подходе, поэтому процесс имеет смысл настраивать сразу под все три и не возвращаться к этому шагу трижды подряд.
Что ломается в контент-пайплайнах на практике и как это чинить
Даже у зафиксированного процесса есть слабые места, и они повторяются от бизнеса к бизнесу. Первая и самая частая беда: при масштабной генерации тексты начинают звучать одинаково и терять фирменный тон — это системная проблема, о которой пишут авторы разборов трендов контент-маркетинга на РБК: без явного шага проверки тона агент выдаёт технически верный, но безликий текст.
Вторая типичная проблема — переспам и дублирование смысла. Если несколько статей закрывают одну и ту же тему без чёткого разделения по нишевым углам, поисковик воспринимает их как один и тот же контент и хуже ранжирует обе. Здесь помогает структура: одна широкая пилар-статья и несколько узких статей на конкретные подтемы, связанные между собой внутренними ссылками — так поисковик видит в блоге разные темы одного кластера.
Третья проблема — иллюзия полной экономии. Часть индустрии в 2025-2026 году делает ставку на подключение корпоративных баз знаний к генерации через API, чтобы агент опирался при генерации на реальные данные компании — это описывают как один из трендов автоматизации контента через API нейросетей. Но даже при таком подключении шаг проверки фактов и тона никуда не девается — просто занимает меньше времени, если критика встроена в пайплайн ещё до публикации.
Разница в итоге такая: пайплайн без шага проверки экономит время на черновике и теряет его на правках после публикации. Пайплайн со встроенной критикой тратит это же время один раз, ещё до публикации, — и на этом расходы заканчиваются.
Собрать всё это можно постепенно, без отдельной команды разработчиков: шаги пайплайна описываются словами, как обычная должностная инструкция, поэтому первую рабочую версию можно составить за один рабочий день, просто зафиксировав, как обычно проходит цикл от идеи до публикации внутри команды.
FAQ про автоматизацию контента
Какая нейросеть лучше подходит для автоматизации контента?
Дело не столько в конкретной модели, сколько в том, встроена ли она в процесс из нескольких шагов. Claude Code подходит для этого, потому что умеет выполнять последовательность задач — от поиска частотностей до финальной проверки текста.
Сколько стоит автоматизация контента для бизнеса?
Стоимость зависит от того, покупает бизнес готовый сервис или собирает пайплайн сам. Подписка на инструмент вроде Claude Code стоит заметно дешевле, чем найм агентства на регулярной основе — но требует времени на то, чтобы один раз описать и настроить шаги процесса. Дальше эта настройка работает на постоянной основе, и повторно платить за неё не нужно — в отличие от агентства, где каждый новый объём контента увеличивает счёт. При этом важно закладывать рост объёма заранее: тарифы по API считают токены, и при регулярном ежедневном использовании счёт может обогнать фиксированную подписку. Прикинуть объём на месяц вперёд до запуска дешевле, чем переходить на более широкий тариф постфактум, когда счёт уже вырос.
Заменяет ли ИИ-пайплайн копирайтера полностью?
Нет — пайплайн убирает рутину (сбор частотностей, первый черновик, техническую проверку структуры), но финальное решение — публиковать текст или отправить на доработку — по-прежнему принимает человек. В рабочем пайплайне этот момент стоит выносить в отдельный явный шаг критики с конкретным решением на выходе.
С чего начать автоматизацию контента, если нет техподготовки?
С одного зафиксированного процесса на одну задачу — например, написание постов для соцсетей по одному и тому же шаблону шагов. Сложную систему настраивать сразу не нужно: сначала описывается один рабочий цикл, потом к нему добавляется следующий тип контента. Масштабировать процесс на весь объём контента сразу не обязательно — начать можно с одного канала и одного шаблона проверки, остальное подключать постепенно.
Читайте также: Нейросети для маркетолога: как Claude Code автоматизировал работу маркетингового агентства
Заключение
Автоматизация контента даёт устойчивый результат, когда вокруг генерации выстроен процесс: бриф, исследование, черновик, критика, самопроверка. Именно эти шаги определяют, читают текст до конца или закрывают на третьем абзаце.
Хотите разобраться в автоматизации контента и других задач бизнеса вместе с практиками, которые уже прошли через свои ошибки? Присоединяйтесь к AI Practiq Club.