Нейросеть для видео Seedance 2.0: что это за ИИ, можно ли скачать, есть ли официальный сайт на русском,

Представьте: вы описываете сцену текстом, прикрепляете фотографию персонажа и коротный аудиофрагмент — и через несколько секунд получаете кинематографический ролик с живым звуком, естественной физикой и плавной сменой планов. Никакой студии, никакой съёмочной группы, никакого постпродакшена. Именно это умеет Seedance 2.0 — самая обсуждаемая нейросеть для генерации видео в 2026 году.
Модель выпустила компания ByteDance (создатели TikTok) 12 февраля 2026 года. За считанные недели она возглавила пользовательские рейтинги, обойдя Veo 3.1 и Sora 2 Pro, а её ролики разлетелись по всем профессиональным сообществам — от маркетологов до голливудских режиссёров.
Для пользователей из России прямой доступ к Seedance 2.0 закрыт: геоблокировки ByteDance, отсутствие поддержки российских карт и нерусскоязычный интерфейс делают работу с моделью напрямую практически невозможной. Однако через Study AI — платформу для доступа к ведущим нейросетям — вы можете начать работу с Seedance 2.0 уже сегодня: без плясок с IP-подменами и без иностранных счетов.
Что такое Seedance 2.0 и как это работает
Seedance 2.0 — это мультимодальная нейросеть для генерации видео, разработанная командой ByteDance Seed. В отличие от большинства видеогенераторов, которые сначала создают картинку, а потом «навешивают» звук поверх, See Dance 2.0 работает иначе: визуальный ряд и аудиодорожка рождаются в единственном генерационном проходе — одновременно, с полной синхронизацией.
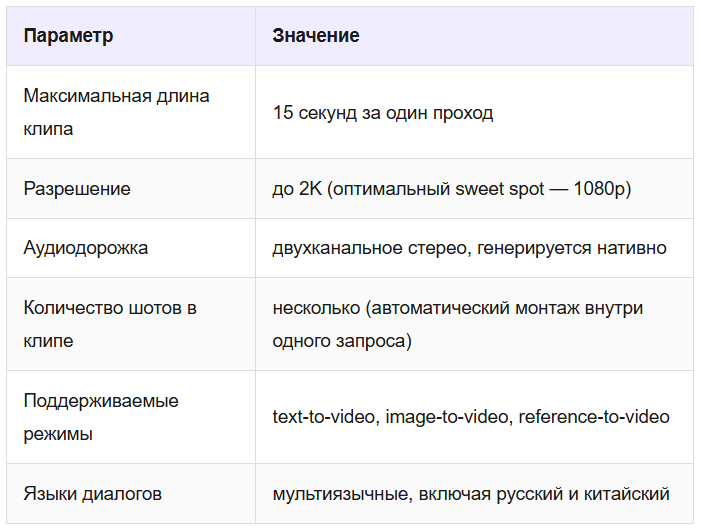
На вход модель принимает сразу четыре типа данных: текстовый промпт, изображения-референсы (до 9 штук), видеофрагменты (до 3 клипов) и аудиофайлы (до 3 записей). Всё это она анализирует вместе, понимая роль каждого файла без дополнительных инструкций. На выходе — клип длиной до 15 секунд в разрешении 2K с нативным звуком: диалогами, музыкой и звуковыми эффектами, точно попадающими в тайминги событий на экране.
Особенность Seedance 2.0 — встроенный мультишотовый монтаж. Один запрос может породить несколько ракурсов со склейками и переходами, как будто за камерой стоит живой оператор с режиссёрским видением. Именно поэтому сообщество называет её не просто «генератором видео», а «AI-режиссёром».
По состоянию на апрель 2026 года Seedance 2.0 занимает первое место в пользовательском рейтинге LMArena и первое место на Artificial Analysis для генерации видео по картинке с аудио — это независимые бенчмарки, которые сложно оспорить.
Чем Seedance 2.0 отличается от предыдущих версий
Каждое поколение модели решало одну большую проблему. В Сидэнс 2.0 ByteDance решила сразу несколько — и это хорошо ощутимо в итоговом результате.
Нативный звук вместо наложения.
В предыдущих версиях аудио было либо полностью отсутствующим, либо добавлялось отдельно. Seedance 2.0 генерирует звук в той же нейронной сети, что и картинку: звук шагов, лязг металла, фоновый шум, музыкальный саундтрек и диалоги персонажей синхронизируются покадрово и не требуют постпродакшена.
Мультишотовый монтаж из одного промта.
Прежде один промпт давал один непрерывный план. Теперь можно задать последовательность: сначала общий план, потом крупный, потом вид от первого лица — и модель сошьёт их в единую сцену с правильными переходами, сохраняя контекст и персонажей.
Консистентность персонажей через весь клип.
Раньше лица «плыли» уже через несколько секунд, а одежда меняла цвет в другом ракурсе. Си Дэнс 2.0 удерживает внешность персонажа стабильно: при повороте на 360°, при смене освещения, при переходе из сцены в сцену. Одна загруженная фотография — и персонаж остаётся собой до конца клипа.
Реалистичная физика без артефактов.
Плавающие конечности, вода, текущая вверх, нарушения анатомии — типичные проблемы предыдущего поколения. Seedance 2.0 понимает, как ведут себя тяжёлые объекты, как движется человеческое тело, как работает гравитация. Физика в кадре теперь не ломается даже в сложных динамичных сценах.
Перенос движения из референсного видео.
Принципиально новая возможность: можно загрузить танцевальный клип или спортивную сцену и применить эту хореографию к своему персонажу. Модель переносит паттерны движения точно, сохраняя анатомию и ритм.
Мультиязычные диалоги с синхронизацией губ.
Персонаж может говорить на нескольких языках, включая русский и китайский, — и артикуляция будет соответствовать речи. Это открывает возможности для создания локализованного контента без переозвучки.
>>> Попробовать Seedance 2.0 <<<
Что можно делать с Seedance 2.0: реальные кейсы
Маркетинговые и рекламные ролики.
Продуктовая видеореклама без съёмочной группы — это уже реальность. Маркетолог загружает фото продукта, описывает сцену, указывает желаемое настроение музыки — и получает готовый рекламный клип с нативным звуком. Команда стартапа Runway уже сделала вирусную рекламу вымышленных часов именно так: зрители не догадывались, что ни одного кадра не снималось вживую.
Сторителлинг и контент для соцсетей.
Серия коротких роликов с одним узнаваемым персонажем — мечта контент-мейкера. Seedance 2.0 держит внешность героя стабильной от видео к видео, позволяя выстраивать нарратив. Вы задаёте персонажа один раз — и он живёт в ваших роликах столько эпизодов, сколько нужно.
Предвизуализация для кино и рекламы.
Режиссёры и продюсеры используют нейросеть для быстрого создания «аниматика» — грубой версии сцены до реальных съёмок. Это сокращает время на брифинг команды и позволяет заказчику «увидеть» идею до того, как потрачены деньги на площадку и актёров.
Образовательные материалы и объяснения.
Преподаватели и авторы онлайн-курсов генерируют анимированные объяснения, исторические реконструкции и визуализации абстрактных процессов. Озвучка создаётся вместе с картинкой — не нужно записывать голос отдельно и монтировать.
Вирусные мемы и трендовые форматы.
Один из самых популярных форматов 2026 года — заменить героев известных сцен на кошек, котов или других персонажей с сохранением исходной хореографии и физики. Именно это стало визитной карточкой Seedance 2.0 в соцсетях: «ваш кот танцует сальсу с правильной анатомией и без артефактов».
Доступ в России
ByteDance продвигает Seedance 2.0 через собственные платформы — Dreamina, CapCut Video Studio, а для разработчиков — через BytePlus ModelArk. Все эти сервисы имеют географические ограничения: доступ с российских IP-адресов или закрыт или нестабилен. Оплата возможна только зарубежными картами — Visa, Mastercard, а также через международные платёжные системы, недоступные из России. Интерфейс рассчитан на английский и китайский язык, русскоязычной поддержки нет.
Это не исключение — так устроено большинство топовых AI-сервисов. Sora, Veo, Runway, Midjourney — все они закрыты для прямого российского доступа по тем же причинам: платёжная инфраструктура и геоблоки. Это системная проблема рынка, а не особенность конкретной нейросети.
>>> Бесплатная регистрация в Seedance 2.0 <<<
Seedance 2.0 на Study AI
Study AI — это официальная платформа, которая интегрировала десятки ведущих нейросетей через легальные API и обеспечила российским пользователям полноценный доступ к ним. Seedance 2.0 доступна на Study AI наравне с другими топовыми моделями — через единый интерфейс, на русском языке, без технических сложностей.
Никакого иностранного IP-адреса не нужно, никаких зарубежных аккаунтов, никакой возни с конвертацией валют. Вы заходите на Study AI, выбираете Seedance 2.0 в каталоге и сразу начинаете генерировать — так же, как если бы вы работали с нейросетью напрямую, только без всех барьеров, которые обычно этому мешают.
Вот что делает Study AI удобным решением именно для работы с Seedance 2.0:
- Стабильный доступ — платформа работает из России напрямую, соединение не обрывается посреди генерации.
- Оригинальная модель, не суррогат — вы работаете с настоящим Seedance 2.0 от ByteDance, а не с урезанной копией.
- Русскоязычный интерфейс и поддержка — промпты, настройки и помощь — всё на родном языке.
- Единый токен-баланс — один счёт работает для всех нейросетей на платформе, не нужно заводить отдельный аккаунт под каждую модель.
- Быстрый старт — регистрация занимает меньше минуты, нейросеть доступна сразу после пополнения баланса.
Главное преимущество Study AI — не только доступ к Seedance 2.0, но и то, что вместе с ней вы получаете весь каталог: GPT, Claude, Gemini, Midjourney, Sora, Runway, Flux и ещё десятки топовых моделей. Один аккаунт, один токен-баланс, один интерфейс.
Это меняет рабочий процесс: вы генерируете сценарий текстовой моделью, создаёте референсные изображения в Flux или Midjourney, а потом оживляете их в Seedance 2.0 — и всё это без переключения между разными сервисами, без повторных регистраций и без жонглирования несколькими подписками.
>>> Начать работу в Seedance 2.0 <<<
Как начать работу с Seedance 2.0 прямо сейчас
- Шаг 1. Зарегистрируйтесь на Study AI. Перейдите на Study24.ai и создайте аккаунт — это занимает меньше минуты. Никаких иностранных данных не требуется.
- Шаг 2. Пополните токен-баланс. Выберите подходящий тариф и оплатите с российской карты в рублях. Токены зачислятся мгновенно и не имеют срока действия.
- Шаг 3. Откройте Seedance 2.0 в каталоге. В разделе нейросетей найдите Seedance 2.0, введите промпт или загрузите референсы — и запустите генерацию. Никаких дополнительных настроек и ожидания.
Seedance 2.0 — уже доступен, можно пробовать!
Seedance 2.0 — это не очередная «нейросеть с красивыми демо». Это модель, которая изменила представление о том, что один человек с одним промптом может создать: кинематографическую сцену с живым звуком, убедительной физикой и профессиональным монтажом. ByteDance создала инструмент, за которым следят голливудские студии и который уже используют маркетологи, режиссёры, контент-мейкеры и все, кто хочет рассказывать истории через видео.
>>> Попробовать Seedance 2.0 <<<
Как устроен Seedance 2.0 изнутри
Большинство видеогенераторов работают по одной схеме: сначала модель создаёт последовательность кадров, потом — отдельно — звуковая система накладывает аудио поверх. Seedance 2.0 устроен принципиально иначе. ByteDance называет это Unified Multimodal Audio-Video Joint Generation Architecture — единой архитектурой, в которой визуальный и звуковой потоки порождаются в одном процессе, с общим «пониманием» того, что происходит на экране.
Практический эффект этого решения виден сразу: звук шагов совпадает с движением ног в кадре, удар меча сопровождается лязгом именно в тот момент, когда клинки соприкасаются, а фоновая музыка меняет темп вместе с ритмом монтажа. Это не синхронизация после — это совместная генерация с нуля.
Что модель принимает на вход
Seedance 2.0 поддерживает четыре типа входных данных одновременно. В одном запросе можно передать:
- Текстовый промпт — описание сцены, настроения, движения камеры, стиля освещения
- До 9 изображений-референсов — персонажи, локации, объекты, стилевые образцы
- До 3 видеофрагментов (суммарно до 15 секунд) — для переноса движения, хореографии, операторских приёмов
- До 3 аудиофайлов (до 15 секунд каждый) — голос персонажа, музыкальная тема, звуковой референс
Модель самостоятельно разбирается, какую роль играет каждый файл, — не нужно явно указывать «это фон», «это персонаж». Достаточно описать в тексте, что именно вы хотите использовать, и Seedance 2.0 сопоставит файлы с контекстом промпта.
Всего в одном запросе можно передать до 12 ассетов (9 изображений + 3 видео + 3 аудио). Это рекорд среди публично доступных видеогенераторов на момент выхода модели.
Выходные характеристики
Управление камерой: что можно задать в промпте
Одна из сильных сторон модели — понимание операторской лексики. Seedance 2.0 корректно интерпретирует профессиональные термины движения камеры, которые раньше модели игнорировали или понимали неточно. В промпте работают, в частности, следующие команды:
- tracking shot — камера движется вместе с объектом
- dolly zoom — классический «наезд Хичкока»: объект остаётся в кадре, фон меняется
- low angle / high angle — нижняя и верхняя точки съёмки
- POV — вид от первого лица
- slow motion — замедленная съёмка с сохранением чёткости
- crane shot — подъём камеры с высоким ракурсом
Помимо движения, модель понимает параметры освещения: golden hour, neon lit, overcast diffused light и подобные дают предсказуемый визуальный результат без дополнительных настроек.
Консистентность персонажей: как это работает
Проблема «дрейфа» персонажа — одна из самых раздражающих в видеогенерации. Загружаешь фото человека, модель три секунды держит сходство, а потом лицо начинает «плыть», менять черты, в другом ракурсе становится другим человеком. Seedance 2.0 решает эту проблему через механизм «reference lock»: загруженное изображение персонажа становится жёстким якорем для всего клипа.
Консистентность сохраняется при:
- повороте головы на 360°
- смене освещения (день/ночь, натуральный/неоновый свет)
- переходе между шотами внутри одного клипа
- смене крупности плана (от общего до крупного)
То же касается одежды, причёски и небольших деталей — татуировок, аксессуаров, текста на футболке. Модель удерживает не только лицо, но и весь визуальный «профиль» персонажа.
Motion Transfer: перенос движения
Функция, которая буквально объехала весь интернет в первые недели после релиза. Идея простая: вы загружаете видео с нужной хореографией или движением — и применяете его к своему персонажу. Танец, боевая сцена, спортивное движение, характерная походка — модель переносит паттерн движения, адаптируя его к анатомии нового персонажа.
При этом Seedance 2.0 не просто накладывает скелетную анимацию поверх: он воссоздаёт физику движения заново, учитывая вес и пропорции персонажа. Именно поэтому перенесённое движение выглядит естественно, а не как «кукольная» анимация. Точно, как у Kling Motion Control.
Нативный звук: три слоя аудио
Аудиодорожка в Seedance 2.0 состоит из трёх независимых слоёв, которые генерируются совместно:
- Звуковые эффекты — привязаны к физическим событиям в кадре. Шаги, удары, скрип двери, падение воды. Тайминг определяется не приближённо, а по точным покадровым позициям объектов.
- Фоновый саундтрек — музыка или амбиент, генерируется в соответствии с настроением сцены. Нарастает в напряжённых эпизодах, затихает в тихих.
- Диалоги — персонажи могут говорить, если задано аудио с голосом или текстовый скрипт. Губная синхронизация (lip-sync) генерируется вместе с артикуляцией, а не подгоняется постфактум.
Если вы загружаете аудиофайл с голосом, модель не просто прикладывает его к видео — она перестраивает артикуляцию персонажа под фонетику именно этой записи. Это важно для локализации: можно взять одну сцену и озвучить её на разных языках, получив правдоподобную артикуляцию под каждый вариант.
Физика и реализм движения
У предыдущих поколений видеомоделей была одна общая слабость: они «не знали» физики. Вода текла вверх, волосы вели себя как твёрдый объект, человек бежал, но ноги не касались земли. Seedance 2.0 обучен на данных, которые включают физическую симуляцию: модель понимает гравитацию, инерцию, вес объектов и кинематику человеческого тела.
На практике это выражается в нескольких конкретных вещах:
- Ткань ведёт себя как ткань — колышется, мнётся, не «прилипает» к телу как текстура
- Жидкости имеют правильную динамику — брызги, рябь, течение
- При столкновениях объекты реагируют с правильным импульсом и отдачей
- В сложных сценах с несколькими персонажами они не проходят сквозь друг друга
Мультишотовый монтаж: один промпт — несколько планов
Это, пожалуй, наиболее нетривиальная техническая особенность модели. В большинстве видеогенераторов один запрос = один непрерывный план. В Seedance 2.0 можно попросить последовательность ракурсов внутри одного клипа, и модель смонтирует их сама:
«Общий план: воин выходит из тумана. Переход на средний план: он поднимает меч. Крупный план: глаза крупным планом. POV: противник перед ним.»
Модель не просто выдаёт четыре разных клипа — она создаёт единую сцену, в которой все ракурсы сняты как будто одновременно, с одинаковым освещением, одним и тем же персонажем и логичными переходами между планами. Контекст сцены сохраняется через весь клип.
Ограничения, о которых стоит знать
Было бы нечестно говорить только о сильных сторонах. ByteDance сами публично фиксируют несколько областей, где модель пока не достигла потолка:
- Несколько персонажей одновременно. При сложных сценах с двумя и более героями консистентность каждого из них поддерживается хуже, чем при работе с одним. Особенно заметно при тесных взаимодействиях — борьбе, объятиях, передаче объектов.
- Рендеринг текста в кадре. Надписи, вывески, буквы на одежде — модель генерирует их с ошибками. Если в вашем задании критически важна читаемая надпись, результат нужно проверять.
- Случайные аудио-дисторции. На длинных клипах (ближе к 15 секундам) иногда возникают артефакты в звуке — особенно в частотах диалога. Не системно, но встречается.
- Реальные люди и IP. Модель имеет фильтры против генерации реалистичных изображений известных публичных персон и воспроизведения охраняемых персонажей. После волны споров с Голливудом в марте 2026 года эти фильтры были существенно усилены.
>>> Генерировать видео в Seedance 2.0 <<<
Сведения о рекламодателе: ООО "Диджитал Гениус". ИНН 7813681158