Когортный анализ на основе сырых данных Яндекс Метрики. Считаем Retention Rate и LTV

Автор: Валерия Чистова, старший веб-аналитик 2 категории, icontext
Введение
Удержание пользователей и их пожизненная ценность — одни из ключевых метрик, которые определяют, насколько успешен ваш продукт. Однако агрегированные отчёты в системах аналитики зачастую не дают всей картины. Для глубокого понимания поведения пользователей нужно копнуть глубже и обратиться к сырым данным.
Что даёт когортный анализ?
Когортный анализ — это инструмент, который позволяет разделить пользователей на группы (когорты) по определенным признакам и наблюдать за их поведением с течением времени. Это поможет ответить на ключевые вопросы:
- Сколько пользователей остаются активными спустя неделю или месяц?
- Какие группы клиентов приносят наибольший доход?
- Как улучшить удержание пользователей и увеличить их ценность для бизнеса?
Эти ответы позволяют принимать решения, которые улучшат продукт, сделают маркетинг более целевым и увеличат доход.
Как мы будем работать с данными?
В этой статье мы рассмотрим:
- Как выгрузить сырые данные из Яндекс Метрики через Logs API.
- Как подготовить их для когортного анализа.
- Как рассчитать метрики Retention и LTV.
В результате вы сможете проводить когортный анализ самостоятельно и принимать обоснованные решения на основе данных.
Прежде чем начать: определяем когорты
Когорты — это группы пользователей, объединенные общим признаком, например, датой первой покупки. Такой подход позволяет отследить, как долго клиенты остаются активными и как изменяется их ценность для бизнеса.
На картинке снизу пример когортного распределения:
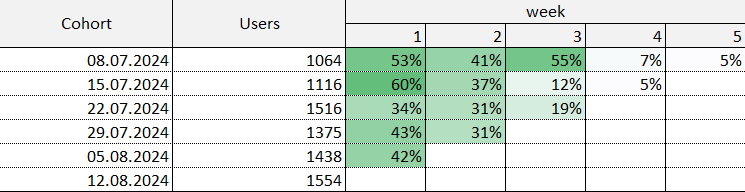
В столбце “Cohort” - когорты по неделям, начиная с 8 июля 2024 года. В столбце “Users” указано число пользователей, пришедших впервые на сайт в каждую неделю. Далее в таблице вы видите доли пользователей, которые вернулись на сайт в течение последующих недель. Например, рассмотрим когорту пользователей, которые впервые зашли на сайт 8 июля. Через неделю из 1064 пользователей снова посетили сайт 53% от их числа. Через 2 недели вернулся 41% от их первоначального числа и т.д.
Чтобы понять, какие данные понадобятся нам для выгрузки и дальнейших расчетов, нужно определить:
- Признак формирования когорт. Это критерий, по которому пользователи объединяются в группы. Например, дата первой покупки, первое посещение сайта или регистрация. В нашем случае мы будем считать изменение Retention и LTV по отношению к дате первой покупки.
- Период анализа. Мы определили, что хотим проанализировать когорты по месяцам и посмотреть возвращаемость покупателей и их ценность в течение года, поэтому нам понадобятся данные за год.
Выгрузка сырых данных из Яндекс Метрики
Чтобы получить эти данные, как было сказано ранее, мы будем использовать сырые данные Яндекс Метрики , выгруженные с помощью Logs API.
Немного о Logs API
Logs API — это интерфейс для доступа к сырым данным о пользователях Яндекс Метрики. В отличие от стандартных отчетов, которые предоставляют агрегированные данные, Logs API позволяет получать детализированную информацию по каждому пользователю, его действиям и событиям в реальном времени. Это дает возможность глубже анализировать поведение пользователей, проводить когортный анализ и рассчитывать такие метрики, как Retention и LTV.
Как получить данные из Яндекс Метрики?
В начале нужно получить OAuth-токен, который позволит подключаться к Logs API Яндекс Метрики. Для этого нужно сделать следующее:
- Создать приложение , инструкция в статье Якова Осипенкова.
- Получить OAuth-токен, инструкция в статье Якова Осипенкова.
После получения токена, используя Python, можно обратиться к Logs API и выгрузить данные. Со списком запросов для выгрузки данных можно ознакомиться в справке.
Для получения нужных данных можно использовать Google Colab. Это удобный инструмент для аналитиков, которым важно быстро и эффективно обрабатывать данные, а также проводить анализ и визуализацию метрик. По этой ссылке делимся с вами блокнотом с кодом по получению данных для дальнейшего расчета LTV и Retention.
Подготовка данных для анализа
После работы с Logs API мы получили таблицу с четырьмя основными колонками:

Далее важно правильно подготовить полученные данные, поэтому этот этап включает их очистку и преобразование в формат, подходящий для когортного анализа.
Очистка данных и приведение их к нужным типам
Сырые данные часто содержат поля с неподходящими форматами. Для анализа важно привести:
- client_id и transaction_id в формат string;
- purchase_date в формат datetime;
- revenue в формат float или int.
# Преобразование дат
logs_df['purchase_date'] = pd.to_datetime(logs_df['purchase_date'])
# Преобразование остальных типов через словарь
logs_df = logs_df.astype({
'revenue': 'float',
'client_id': 'str',
'transaction_id': 'str'
})
# Проверяем типы данных
print(logs_df.dtypes)
Возможно в вашем случае будут наблюдаться дублированные покупки - повторяющиеся строки с одинаковым 'transaction_id' . Их можно убрать следующим образом:
logs_df_clean = logs_df
if logs_df_clean.duplicated(subset=['transaction_id']).any():
# Удаляем дубликаты по указанным столбцам
logs_df_clean= logs_df_clean.drop_duplicates(subset=['transaction_id'])
print("Дубликаты удалены")else:
print("Дубликатов нет")
Также удалите строки с неопределенными значениями, иначе эти строки будут искажать расчеты:
logs_df_clean = logs_df_clean.dropna()
Работа с выбросами
Данные могут содержать выбросы — значения, которые слишком сильно отличаются от общей массы и искажают анализ. Для работы с выбросами можно:
- Удалить строки с некорректными значениями (например, нулевые или отрицательные суммы покупок)
# Удаляем строки с нулевой или отрицательной суммой покупки
logs_df_clean = logs_df_clean[logs_df_clean['revenue'] > 0]
- Исключить аномально высокие значения дохода:
# Построим гистограмму распределения суммы покупок
plt.figure(figsize=(10, 6))
plt.hist(logs_df_clean['revenue'], bins=30, edgecolor='k', color='skyblue')
plt.title('Гистограмма суммы покупок', fontsize=16)
plt.xlabel('Сумма покупки', fontsize=14)
plt.ylabel('Количество', fontsize=14)
plt.grid(True)
plt.show()
На гистограмме редкие значения, сильно удалённые вправо или влево от основной массы, могут считаться выбросами. Для точного анализа выбросов можно дополнить гистограмму статистическими методами, например, определение межквартильных размахов (IQR).
В нашем случае данные имеют экспоненциальное распределение:
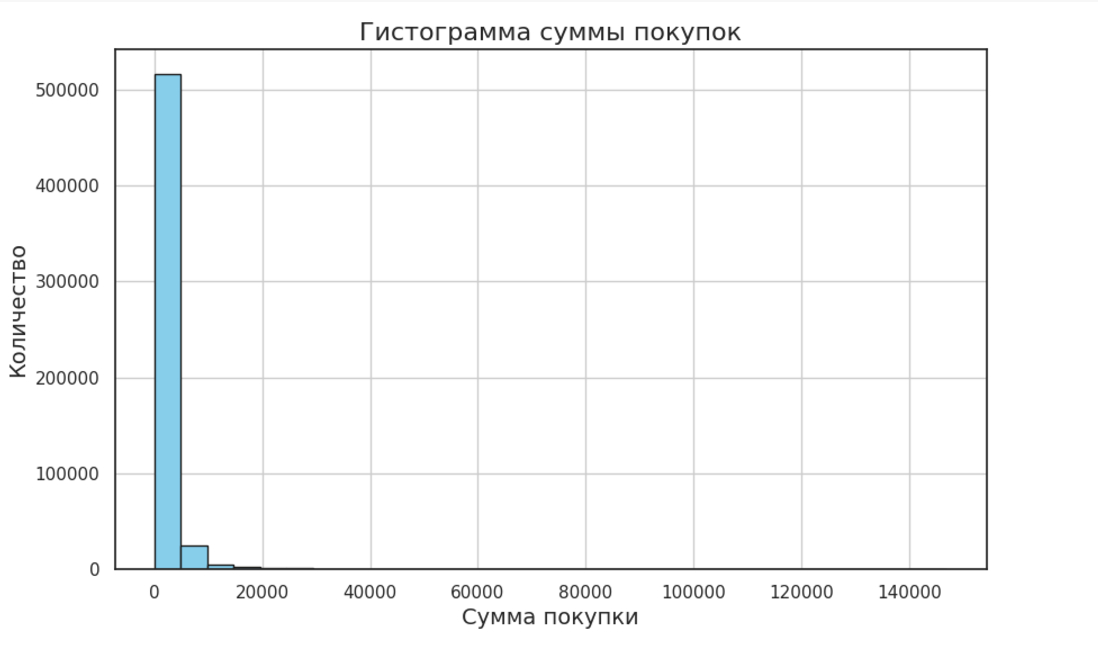
Мы привели этот график к логарифмическому виду для лучшей наглядности:
plt.figure(figsize=(10, 6))
plt.hist(np.log(logs_df_clean['revenue']), bins=10, color='green', edgecolor='white'))
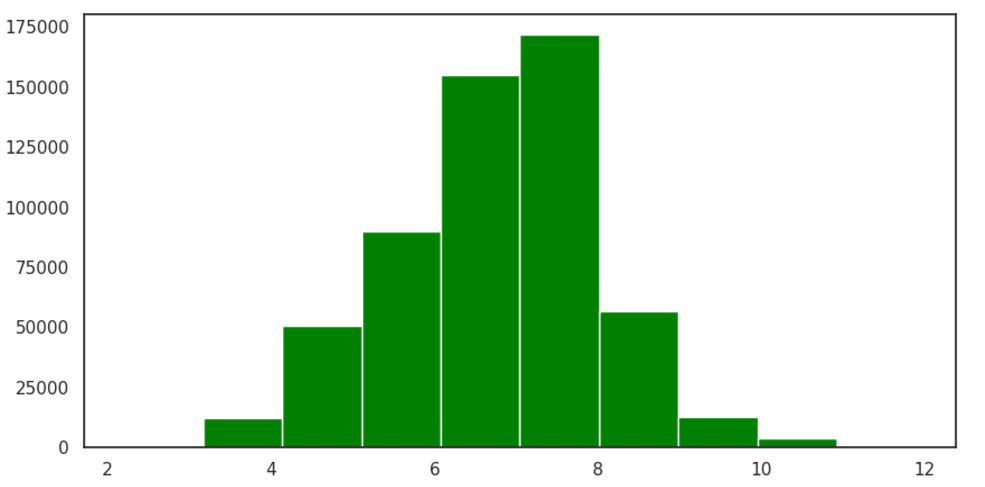
И далее на логарифмировнных значениях дохода с помощью межквартильного метода убрали выбросы.
Немного раскроем здесь понятие межквартильного метода на примере схемы, взятой из этой статьи:
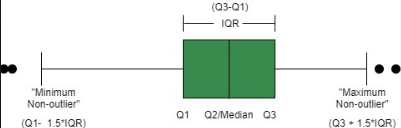
На изображении мы видим боксплот, который помогает визуализировать данные и понять, где находятся выбросы. Вот что на нем важно:
· Q1 (Первый квартиль): значение, ниже которого находится 25% данных.
· Q2 (Медиана): значение, делящее данные пополам (50% ниже, 50% выше).
· Q3 (Третий квартиль): значение, ниже которого находится 75% данных.
· IQR (Межквартильный размах): разница между Q3 и Q1, то есть: IQR=Q3−Q1. Этот показатель показывает диапазон, в котором находятся центральные 50% данных.
Любые значения, которые выходят за пределы следующего диапазона, считаются выбросами:
· Минимум=Q1−1.5⋅IQR
· Максимум=Q3+1.5⋅IQR
Число 1.5 в методе IQR — эмпирический коэффициент, который используется для определения того, насколько далеко данные могут выходить за пределы нормального диапазона, чтобы считаться выбросами. Стандартное значение 1.5⋅IQR может быть слишком жёстким для длинных хвостов экспоненциального распределения. Поэтому можно использовать больший коэффициент (например, 2 или даже 3), чтобы хвостовые значения, характерные для этого распределения, не считались выбросами.
Чтобы понять, какой коэффициент использовать, посмотрите, какие значения метод выделяет как выбросы, и подумайте, являются ли они действительно выбросами или просто естественной частью хвоста распределения.
Далее на графике: точки, выходящие за пределы "усов" (чёрные кружки), считаются выбросами, а "усы" — это минимальное и максимальное значение в пределах диапазона [Q1−1.5⋅IQR,Q3+1.5⋅IQR] .
В нашем примере выбросов оказалось немного и после применения данного метода у нас сохранилось 92% от исходного объема данных.
Код для применения межквартильного метода на логарифмированных данных:
logs_df_clean['log_revenue'] = np.log(logs_df_clean['revenue'])
Q1 = logs_df['log_revenue'].quantile(0.25)
Q3 = logs_df['log_revenue'].quantile(0.75)
IQR = Q3-Q1
#оставляем строки, которые находятся не далее границ 1.5*IQR от Q1 и Q3
logs_df_clean = logs_df_clean[(logs_df_clean['log_revenue'] >= (Q1-1.5*IQR)) & (logs_df_clean['log_revenue'] <= (Q3+1.5*IQR))]
Построение когорт
Чтобы построить когорты, нам нужно:
- Подготовить данные для формирования когорт
На основе выгруженных данных (колонки client_id, purchase_date, revenue) нам нужно определить дату первой покупки для каждого клиента и добавить колонку с идентификатором когорты ( в нашем примере - месяц первой покупки):
# Вычисляем дату первой покупки и добавляем идентификатор когорты (месяц первой покупки)
logs_df_clean['cohort'] =
(logs_df_clean.groupby('client_id')['purchase_date'].transform('min')).dt.to_period('M')
# Рассчитываем сдвиг по месяцам от когорты
logs_df_clean['transaction_month'] =
logs_df_clean['purchase_date'].dt.to_period('M')
logs_df_clean['cohort_month_offset'] = (logs_df_clean['transaction_month'] - logs_df_clean['cohort']).apply(lambda x: x.n)
logs_df_clean.head()
- Агрегировать данные
Для анализа удержания и LTV нужно агрегировать данные по когортам:
- Рассчитать количество уникальных клиентов в каждой когортной группе (client_id).
- Подсчитать суммарный доход (revenue) для каждой когорты в каждом месяце.
# Агрегация по когортам и временным периодам
cohort_data = logs_df_clean.groupby(['cohort', 'cohort_month_offset']).agg({
'client_id': 'nunique', # Количество уникальных пользователей
'revenue': 'sum' # Сумма покупок
}).reset_index()
# Переименовываем колонки для удобства
cohort_data.rename(columns={'client_id': 'user_count', 'purchase_sum': 'revenue'}, inplace=True)
cohort_data.head()
Убедитесь, что данные когорт выглядят корректно. Например:
- Для каждой когорты cohort_month_offset начинается с нуля.
- Суммарное количество пользователей соответствует исходным данным.
Расчет метрик Retention
Retention Rate — это одна из ключевых метрик, которая позволяет понять, сколько пользователей остаются активными через какое-то время после их первого взаимодействия с продуктом. В контексте нашего анализа удержание измеряет процент пользователей, которые совершили повторные покупки в разные месяцы после своей первой покупки.
Что такое удержание и зачем оно нужно?
Проще говоря, удержание показывает, насколько хорошо продукт способен возвращать клиентов. Например, если в январе первую покупку совершили 100 человек, а в феврале из них вернулось 60, то удержание за второй месяц составит 60%. Анализируя удержание по когортам, мы можем понять, на каких этапах теряются пользователи, что поможет улучшить стратегию их удержания.
Как рассчитать?
Для расчета удержания нам нужно:
- Посчитать количество пользователей в когорте (тех, кто совершил первую покупку в один и тот же период, например, в месяц).
- Рассчитать процент пользователей, вернувшихся в каждый период, относительно общего числа в когорте.
Формула расчёта выглядит так:
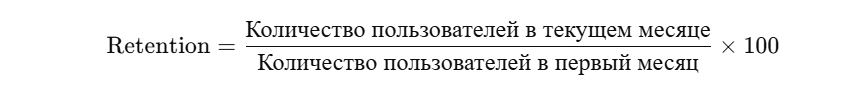
На основе наших данных рассчитаем удержание с помощью Python:
# Для каждой когорты считаем количество пользователей в первый месяц
cohort_sizes = cohort_data[cohort_data['cohort_month_offset'] == 0][['cohort', 'user_count']]
# Объединяем с остальными данными по когорте, чтобы получить общее количество пользователей для каждой когорты
cohort_data = cohort_data.merge(cohort_sizes, on='cohort', suffixes=('', '_first_month'))
# Рассчитываем удержание
cohort_data['retention'] = (cohort_data['user_count'] /
cohort_data['user_count_first_month']) * 100
Визуализируем удержание
Одним из удобных способов анализа удержания является визуализация данных в виде тепловой карты, где каждая строка представляет собой когорту, а столбцы — это месяцы после первой покупки.
Код для построения тепловой карты:
# Визуализируем это
retention_pivot = cohort_data.pivot_table(
index='cohort',
columns='cohort_month_offset',
values='retention',
aggfunc='sum',
)
retention_pivot_percent = retention_pivot * 100
sns.set(style='white')
plt.figure(figsize=(13, 9))
plt.title('Cohorts: Retention Rate')
# 1 -- отображаем данные для 1 столбца без цветовой карты
sns.heatmap(retention_pivot_percent[[0]], annot=True, fmt='.0f', linewidths=1,
linecolor='gray', cmap="Greys", cbar=False, annot_kws={"color": "black"} )
# # 2 -- делаем наложение цветовой карты на оставшиеся столбцы
# # Создаем маску для остальных столбцов
mask = np.zeros_like(retention_pivot_percent, dtype=bool)
mask[:, 0] = True # Маскируем первый столбец
sns.heatmap(retention_pivot_percent, annot=True, fmt='.0f', linewidths=1,
linecolor='gray', yticklabels = 1, cmap="Blues", cbar_kws={'label': 'Retention Rate'},
mask=mask , annot_kws={"color": "black"} )
# Добавление '%'
for text in plt.gca().texts:
text.set_text(f"{text.get_text()}%")
plt.show()
Тепловая карта покажет, как удержание покупателей изменяется с каждым месяцем для каждой когорты. Обычно удержание падает со временем, но хороший продукт будет иметь высокое удержание даже спустя несколько месяцев.
Мы получили такую карту:
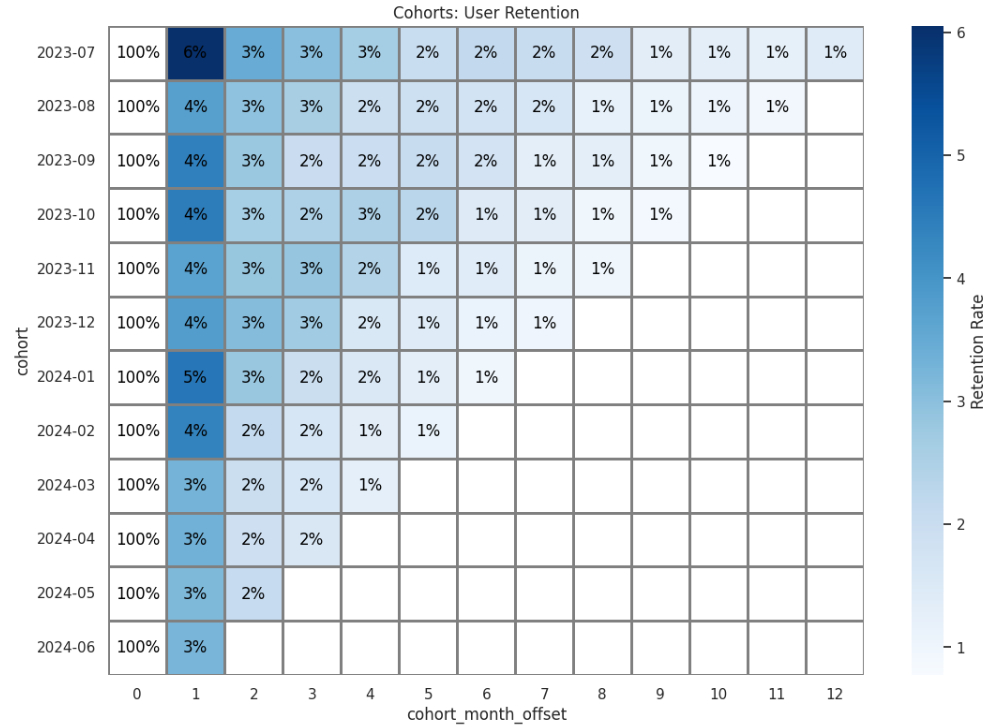
и сделали следующие выводы:
- Быстрое падение Retention после первого месяца
Во всех когортах наблюдается резкое снижение удержания покупателей уже со второго месяца. Например, большинство когорт теряют более 90% покупателей в первый же месяц после их привлечения. Это говорит о том, что значительная часть новых покупателей не возвращается.
- Стабильное снижение Retention в последующих месяцах
После второго месяца удержание продолжает снижаться, но уже более плавно. В некоторых когортах (например, 2023-07, 2023-08) удержание остаётся на уровне 1–2% в течение долгого времени. Это может быть связано с наличием небольшого числа лояльных клиентов.
- Сезонность или изменения в привлечении пользователей
Когорты до нового года показывают немного лучшее удержание в первые месяцы: 6-4% против 4-3% в когортах 2024 года. Это может указывать на изменение стратегии привлечения пользователей, сезонность или улучшение продукта/сервиса.
- Важность работы с первой когортой (0 месяц)
Видно, что почти все когорты ведут себя одинаково в дальнейшем, указывая на отсутствие значительных изменений в работе с новыми пользователями.
Таким образом, Retention Rate — это ключевая метрика для оценки, насколько эффективно продукт удерживает пользователей на протяжении времени. На основе её анализа можно принять обоснованные решения для повышения качества обслуживания, улучшения функционала и развития продукта в целом.
Расчет метрик LTV
LTV (Lifetime Value) — это метрика, которая показывает общую прибыль, которую компания получает от одного клиента за всё время его взаимодействия с продуктом. Эта метрика помогает оценить эффективность привлечения и удержания пользователей, а также понять, сколько можно инвестировать в маркетинг, чтобы привлечь новых клиентов.
Зачем считать LTV?
LTV важен для анализа долгосрочной ценности клиентов и стратегического планирования. Например:
- Сравнение LTV с затратами на привлечение клиентов (CAC) помогает понять, насколько рентабельны маркетинговые кампании.
- Оценка динамики LTV позволяет выявить когорты клиентов, которые приносят наибольшую ценность, и сосредоточиться на них.
- Анализ изменений LTV помогает оценить влияние изменений в продукте, маркетинге или сервисе.
Как рассчитывается LTV?

LTV можно считать разными способами, в зависимости от специфики бизнеса. Мы будем использовать следующую формулу:
Таким образом мы вычислим среднюю выручку, которую приносит один клиент из когорты, за определенный период времени.
Подготовка данных для расчета
Перед расчётом убедимся, что у нас есть необходимые данные:
- Когорты пользователей, которые совершили первую покупку в один и тот же период.
- Суммарная выручка по когортам за каждый период.
- Количество уникальных клиентов в когортах, чтобы посчитать среднюю ценность.
Код для расчета LTV:
# Рассчитаем суммарную выручку для каждой когорты и каждого периода
cohort_revenue = cohort_data.groupby(['cohort',
'cohort_month_offset'])['revenue'].sum().reset_index()
# Добавим количество клиентов в когортах за 0 месяц из таблицы, использованной ранее для Retention
cohort_sizes = cohort_data[['cohort','user_count_first_month',
'cohort_month_offset']]
cohort_revenue = cohort_revenue.merge(cohort_sizes,
on=['cohort','cohort_month_offset'], suffixes=('', '_first_month'))
# Рассчитаем LTV
cohort_revenue['ltv'] = cohort_revenue['revenue'] /
cohort_revenue['user_count_first_month']
cohort_revenue.head()
Визуализируем LTV
Также как и для Retention Rate построим тепловую карту
Код:
ltv_pivot = cohort_revenue.pivot_table(
index='cohort', columns='cohort_month_offset', values='ltv', aggfunc='mean').round()
# Создаем маску для столбца age = 0
mask = np.zeros_like(ltv_pivot[[0]], dtype=bool)
mask[:, 0] = False # Маскируем только первый столбец
# Построение графика: этап 1 -- отображение всех данных без цветовой карты
sns.set(style='white')
plt.figure(figsize=(18, 9))
plt.title('LTV')
# Этап 1: Отображение столбца age=0 без цветовой карты
sns.heatmap(ltv_pivot[[0]], annot=True, fmt='.2f', linewidths=1, linecolor='gray',
cmap="YlOrBr", mask=mask, cbar=False, annot_kws={"color": "black"})
# Этап 2: Отображение остальных столбцов с цветовой картой и аннотациями
mask = np.zeros_like(ltv_pivot, dtype=bool)
mask[:, 0] = Truesns.heatmap(ltv_pivot, annot=True, fmt='.2f', linewidths=1, linecolor='gray',
cmap="Blues", mask=mask, cbar_kws={'label': 'LTV'}, annot_kws={"color": "black"})
plt.show()
На тепловой карте строки представляют собой когорты (группы клиентов по дате первой покупки), а столбцы — количество месяцев, прошедших с первой транзакции. Ячейки отражают значение LTV.
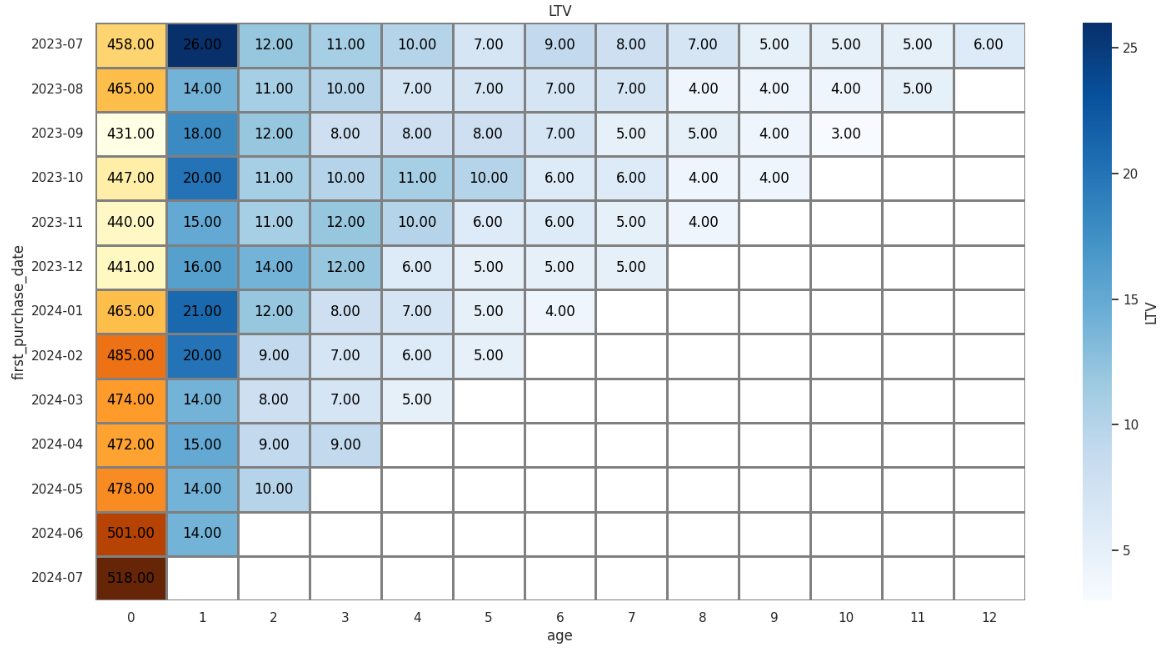
Интерпретация тепловой карты:
- Рост значений по горизонтали. Если LTV растет с увеличением количества месяцев, это говорит о том, что пользователи продолжают приносить доход, что является хорошим показателем.
- Сравнение когорт. Более темные ячейки указывают на когорты с более высокой пожизненной ценностью. Это позволяет определить наиболее ценные группы пользователей.
- Тренды по времени. Если ранние когорты имеют более высокий LTV, а более поздние — меньший, это может сигнализировать о снижении качества привлеченных пользователей или об изменениях в маркетинговых стратегиях.
В нашем примере у большинства строк LTV быстро падает после 2–3 месяцев, что может говорить о необходимости дополнительных усилий в удержании клиентов, таких как программы лояльности или таргетированное взаимодействие.
Также видно, что в 2023 году LTV в большинстве когорт снижался менее резко, чем в 2024 году. Возможно это связано с сезонностью. Например, в конце 2023 года, особенно ближе к праздникам, клиенты могли быть более активны и сами по себе, а в 2024 году (особенно начало года) это уже "затишье", где их нужно было сильнее мотивировать, но это не сработало.
Таким образом, использование тепловой карты позволяет быстро и эффективно оценить ключевые моменты в данных LTV, выявить успешные когорты и наметить точки для дальнейшего анализа.
В итоге рассчитаем совокупный LTV по когортам:
# Считаем итоговый LTV по когортам в функции
def ltv_table(output):
n = output.index.get_level_values(0) for i in n:
ltv_sum = output.loc[i].sum()
print('{} | {:.2F} '.format(i, ltv_sum))print('LTV')print('----------------------------')
ltv_table(output)
У нас получились такие значения:
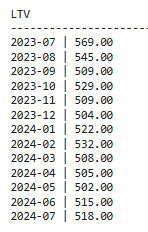
Это нормально, если значения в каждой последующей когорте немного меньше предыдущих, поскольку время наблюдения (age) постепенно сокращается.
Интересными для нас будут когорты, в которых итоговое значение резко возросло, например, как в феврале 2024 года. Возможно, клиенты, привлеченные в феврале, имели более высокий потенциал повторных покупок или сделали более крупные заказы. Или наоборот, интересно изучить резкое снижение итогового LTV, как в сентябре 2023 года.
Как использовать данные Retention и LTV для рекламы и улучшения работы с клиентами
Данные по Retention Rate и LTV — это настоящий клад для оптимизации маркетинга и улучшения стратегии взаимодействия с пользователями. Эти метрики помогают не просто смотреть на текущую ситуацию, но и делать более точные прогнозы, тестировать новые идеи и улучшать результаты. Вот несколько способов их применения:
1.Настроить ретаргетинг
Соберите client_id пользователей с низким Retention Rate или LTV. С помощью загрузки офлайн-данных и параметров посетителей присвойте этим пользователям определенное значение в Яндекс Метрике. И затем создайте сегмент по условию “люди, у которых параметр посетителя…”, чтобы использовать этот сегмент в рекламных кампаниях Яндекс Директ. Так вы сможете напомнить этим клиентам о вашем продукте.
2. Создать look-alike аудиторий
Клиенты с высоким Retention и LTV — это ваша целевая группа. Используя тот же способ с загрузкой параметров посетителей в Яндекс Метрику, создайте сегмент и привлеките новых пользователей, которые с большой вероятностью будут приносить аналогичную ценность.
3. Оптимизировать рекламные каналы
Сравнивая Retention и LTV для разных кампаний, можно точнее оценить их эффективность и улучшить стратегию распределения средств.
4. Тестировать гипотезы и улучшать стратегии
Retеntion и LTV — это показатели, которые можно использовать для тестирования гипотез. Например:
- Как изменится Retention, если предложить бесплатную доставку?
- Влияет ли размер скидки на динамику LTV?
- Какие кампании способствуют росту удержания?
Результаты таких экспериментов помогут найти наиболее эффективные подходы для улучшения клиентского опыта и повышения дохода.
Заключение
Метрики Retention и LTV дают мощные инсайты о поведении пользователей, которые можно эффективно использовать в рекламе, сегментации и оптимизации стратегии работы с клиентами. Они позволяют не только повышать отдачу от существующих кампаний, но и находить новые возможности для роста бизнеса.
Чтобы вам было проще применить описанные шаги на практике, мы создали готовый блокнот в Google Colab со всеми расчетами. Он содержит все основные этапы анализа: построение когорт, расчёт Retention Rate и LTV. Вы сможете легко адаптировать его под свои данные и получить точные результаты всего за несколько минут.