Вашего сайта нет в ответах AI? Разбираем причины и исправляем ошибки

Еще недавно борьба за трафик сводилась к одному: попасть в топ пoисковой выдачи. Но с появлением ChatGPT, Gemini и генеративного поиска Google пользователи все чаще получают готовый ответ прямо в интерфейсе AI, не переходя на сайты. Из-за этого многие компании замечают странную ситуацию: ресурс занимает высокие позиции в поиске, но его почти не цитируют нейросети. В ответах AI появляются другие площадки: иногда менее известные и даже находящиеся ниже в выдаче.
Елена Салтыкова, тимлид команды SEO инновационного digital-хаба Wunder Digital, объясняет механику выбора источников нейросетями и разбирает ошибки, которые мешают сайтам попадать в ответы ИИ.
Откуда ChatGPT берет информацию
Когда мы говорим о видимости в AI-поиске, важно понимать: нейросети не оценивают сайты так, как это делают SEO-специалисты. Они работают с источниками информации, и у разных AI-систем эти источники (ChatGPT и другие LLM-чаты, такие как Gemini, Claude) принципиально различаются.
Большие языковые модели формируют ответы на основе нескольких типов данных.
1. Обучающие данные – то, на чем модель «выросла»
Перед запуском модель обучают на огромных массивах текстов: открытых сайтах, статьях, книгах, форумах, технической документации и других публичных источниках. На основе этих данных модель формирует статистическое понимание языка, фактов и взаимосвязей между ними.
2. Актуальная информация из интернета
Современные версии чат-моделей могут получать свежие данные из сети: например, через встроенный поиск или интеграцию с поисковыми системами. Это используется для информации, которая быстро меняется: новости, курсы валют, погода и т.д. В таких случаях ответ формируется как комбинация внутренних знаний модели и найденных в данный момент внешних источников.
3. Файлы и корпоративные базы знаний
Если пользователь загружает документы — PDF, DOCX, таблицы — или подключает собственную базу знаний (например, через RAG-систему), модель может использовать эти материалы как локальный источник информации в рамках конкретного ассистента.

Елена Салтыкова, тимлид команды SEO Wunder Digital:
– ChatGPT не «заходит» на конкретный сайт каждый раз, когда пользователь задает вопрос. Он опирается либо на знания, сформированные в процессе обучения, либо на результаты внешнего поиска, если такая функция используется. Поэтому вероятность того, что информация из вашего контента повлияет на ответы модели, зависит от качества и авторитетности источника.
Чем сильнее контент с точки зрения E-E-A-T (экспертиза, опыт, авторитетность и доверие), ссылочного профиля и цитируемости, тем выше шанс, что похожие материалы будут присутствовать в обучающих данных или подтягиваться при онлайн-поиске.
Важно понимать ограничения таких модели:
- они не имеют доступа к закрытым базам данных
- не видят личных данных пользователей
- не помнят конкретных сайтов или статей
- не обновляют знания самостоятельно
Модель не «знает», из какого именно источника взят факт. Она просто генерирует наиболее правдоподобный и логичный ответ на основе обучения.
Wunder Digital — № 3 в Беларуси в рейтинге агентств по разработке и продвижению сайтов (Рейтинг Рунета 2025).

Как Google AI Overviews выбирает источники
Генеративный поиск Google — AI Overviews (ранее SGE) — работает иначе. В отличие от чат-моделей, он напрямую опирается на поисковый индекс Google, а языковая модель лишь формирует итоговый ответ и связывает его с источниками.
Все цитируемые страницы берутся из обычного органического индекса Google — тех же документов, которые участвуют в классическом ранжировании. Система сначала формирует пул кандидатов по запросу и его возможным подзапросам. Этот процесс называют fan-out: сложный вопрос разбивается на несколько подтем, для каждой из которых подбираются релевантные документы.
Google подтверждает, что в AI Overviews используются те же сигналы качества, что и в обычном поиске, но дополнительно учитывается фактор извлекаемости информации: насколько удобно системе взять конкретный факт со страницы.
К ключевым факторам обычно относят:
- Топическая релевантность и полнота ответа: Страницы, которые максимально точно закрывают конкретную подтему и дают завершенное объяснение.
- Авторитет и E-E-A-T-сигналы: Сильный домен, уникальный и полезный контент, экспертные авторы, репутация бренда и качественные внешние ссылки на сайт.
- Актуальность информации: Для цен, новостей, обзоров и быстро меняющихся тем преимущество получают обновленные материалы.
- Структура и извлекаемость данных: Четкие заголовки, списки, таблицы, FAQ-блоки и прямые ответы на вопросы облегчают извлечение фрагментов для генеративного блока.. Разнообразие доменовGoogle старается показывать несколько разных источников, а не ссылаться только на один сайт.
Исследования показывают, что большинство цитируемых страниц уже находятся в топ-10 органической выдачи по этому или близкому запросу.
Как происходит генерация ответа:
- Модель формирует структуру на основе запроса пользователя.
- Система извлекает релевантные документы из индекса (retrieval + semantic ranking).
- Модель объединяет знания из предобучения и факты из найденных страниц.
- К каждому фрагменту ответа прикрепляются ссылки на 1-3 источника, которые лучше всего подтверждают конкретный тезис.
В интерфейсе эти ссылки отображаются рядом с абзацами или под ними, позволяя пользователю перейти к первоисточнику.
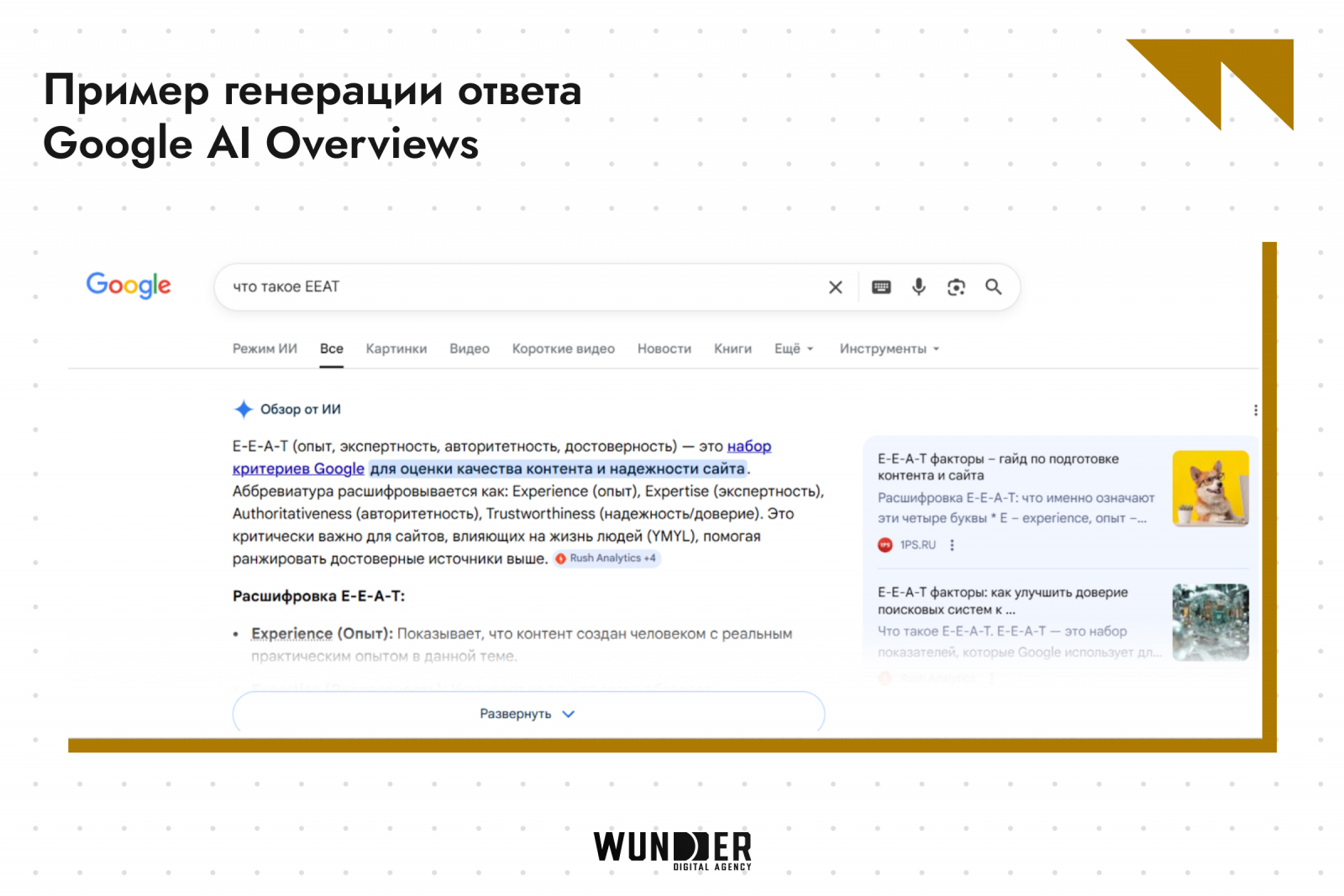
По наблюдениям специалистов и рекомендациям для вебмастеров, вероятность цитирования в AI Overviews повышают несколько факторов:
- фокусирование на семантике и намерениях пользователя
- сильные E-E-A-T-сигналы: авторы, бренд, ссылочный профиль, прозрачные источники
- структурированный и легко извлекаемый контент: Q&A-формат, списки, таблицы, FAQ
- использование структурированной разметки (FAQ, HowTo, Article, Organization, Person)
- регулярное обновление контента в темах, где важна актуальность

По каким принципам AI доверяет источникам
И генеративный поиск Google (AI Overviews), и чат-модели стремятся выбирать источники, которые выглядят опытными, экспертными, авторитетными и надежными. Это снижает риск дезинформации и повышает качество ответа.
При этом ни одна система не использует E-E-A-T как единый «фактор». Он распознается через множество косвенных сигналов, например:
Experience (опыт): Практические кейсы, конкретные примеры, демонстрация реального опыта работы с темой.
Expertise (экспертиза): Терминологическая точность, глубина объяснений, ссылки на исследования или первоисточники.
Authority (авторитет): Упоминания бренда, внешний ссылочный профиль, репутация домена.
Trust (доверие): Согласованность информации, прозрачность источников, корректность фактов и данных.
Иными словами, и поисковые системы, и AI-ассистенты пытаются определить, насколько источнику можно доверять. Главное отличие заключается в том, какие сигналы оказываются решающими.
Елена Салтыкова, тимлид команды SEO Wunder Digital:
– Для LLM-систем важен и фактор Brand Authority — насколько часто бренд упоминается в профессиональной среде: в медиа, исследованиях, обзорах и обсуждениях. Чем чаще название фигурирует в разных источниках, тем выше вероятность, что AI-модель будет воспринимать его как надежный источник.
Google: сильная зависимость от индекса и внешних сигналов
Для Google E-E-A-T — это результат сочетания нескольких типов факторов:
- качество контента
- ссылочный профиль
- поведенческие сигналы
- брендовые запросы
- общая репутация домена
Поэтому сайты с сильным SEO часто получают преимущество в ранжировании.
LLM-модели: фокус на читаемости и структуре текста
Чат-модели гораздо сильнее зависят от того, как устроен сам текст. Для них важны:
- четкая структура
- логическая связность
- полнота объяснений
- наличие явных ссылок на источники
- контекст об авторе или бренде
Другими словами, модель должна легко «понять» материал и извлечь из него факты.
Елена Салтыкова, тимлид команды SEO Wunder Digital:
– Прокачка E-E-A-T почти всегда одновременно повышает шансы и на хороший ранкинг в Google, и на то, что AI-ассистенты будут ссылаться на ваш сайт. Но это не означает полного совпадения алгоритмов.
Почему AI игнорирует ваш контент
Есть несколько распространенных причин, из-за которых даже хорошие сайты не становятся источниками для AI-ответов.
- Нет коротких и прямых ответов.Весь смысл утоплен в длинных вступлениях и «простынях» текста, поэтому модели сложно извлечь конкретный факт.
- Слабая структура контента.Мало подзаголовков, списков, таблиц, FAQ-блоков. Иногда отсутствует или неправильно настроена разметка Schema.org.
- Контент не добавляет новой информации.Если текст – это рерайт того, что уже есть у конкурентов, без кейсов, данных или исследований, у системы нет причины выбирать именно его.
- Несовпадение пользовательского интента.Страница пытается продавать, тогда как пользователь и ИИ ищут объяснение, инструкцию или чек-лист.
- Слабые сигналы доверия.Мало внешних упоминаний, неясные авторы, нет ссылок на авторитетные источники, бренд практически не присутствует за пределами сайта.
Как нейросети оценивают AI-контент
Нейросети не определяют текст как AI-контент по самому факту его происхождения, они оценивают качество текста по паттернам. К типичным признакам слабого контента относятся:
- высокая предсказуемость формулировок;
- повторяемость и шаблонные конструкции;
- низкая информационная плотность;
- отсутствие фактов, цифр и конкретики;
- одинаковый ритм и тон текста.
Елена Салтыкова, тимлид команды SEO Wunder Digital:
– Если текст состоит в основном из общих фраз и не содержит новой информации, он будет восприниматься как низкокачественный. Независимо от того, писал его человек или ИИ.
Важно понимать: AI-текст сам по себе не является проблемой. Проблема – это бессодержательный, неоригинальный и бесполезный контент.
Wunder Digital — № 3 в Беларуси в рейтинге агентств по разработке и продвижению сайтов (Рейтинг Рунета 2025).
Вывод
AI-поиск не отменяет базовые принципы качественного контента. И Google, и чат-модели стремятся опираться на источники, которые выглядят экспертными, авторитетными и надежными. Однако способы определения этих качеств различаются.
Google в большей степени зависит от классических SEO-сигналов – ссылочного профиля, структуры сайта, поведенческих факторов и авторитета домена.Чат-модели сильнее ориентируются на понятность и полноту текста, а также на то, насколько легко из него извлечь конкретные факты.
Поэтому для видимости в AI-поиске важно сочетать два подхода:
- развивать сильное SEO-присутствие и бренд-авторитет;
- создавать структурированный и содержательный контент, из которого системе легко извлекать ответы.
В новой поисковой реальности выигрывают сайты, которые не просто оптимизированы под алгоритмы, а действительно становятся источником знаний в своей теме.